SyntaSpeech
Pretrained Models for LJ, Biaobei, and LibriTTS.
| | | 中文文档
Ce référentiel est la mise en œuvre officielle Pytorch de notre article IJCAI-2022, dans lequel nous proposons Syntaspaspaspheeche pour la syntaxe non autorégressive de texte à la parole.
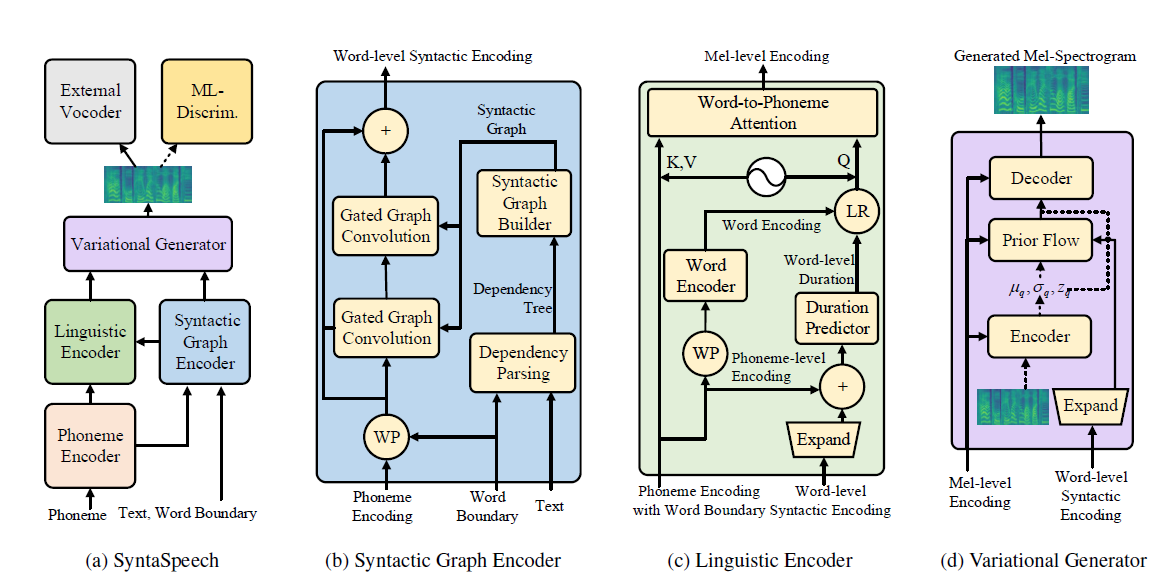
Notre syntaspaspasheenech est construite sur la base de Portaspaspasheenech (Neirips 2021) avec trois nouvelles fonctionnalités:
conda create -n synta python=3.7
condac activate synta
pip install -U pip
pip install Cython numpy==1.19.1
pip install torch==1.9.0
pip install -r requirements.txt
# install dgl for graph neural network, dgl-cu102 supports rtx2080, dgl-cu113 support rtx3090
pip install dgl-cu102 dglgo -f https://data.dgl.ai/wheels/repo.html
sudo apt install -y sox libsox-fmt-mp3
bash mfa_usr/install_mfa.sh # install force alignment tools Veuillez suivre les étapes suivantes pour exécuter ce dépôt.
Vous pouvez utiliser directement nos ensembles de données binarisés pour LJSpeech et Biaobei. Téléchargez-les et décompressez-les dans le dossier data/binary/ .
En ce qui concerne les Libritts, vous pouvez télécharger les ensembles de données bruts et les traiter avec nos modules data_gen . Des instructions détaillées peuvent être trouvées dans DOSC / Prepare_data.
Nous fournissons le modèle pré-formé de vocoders pour trois ensembles de données. Plus précisément, HIFI-AG pour LJSpeech et Biaobei, parallelwavegan pour les Libritts. Téléchargez-les et déziptez-les dans les checkpoints/ dossier.
Ensuite, vous pouvez former Syntaspaspaspheenech dans les trois ensembles de données.
cd < the root_dir of your SyntaSpeech folder >
export PYTHONPATH=./
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/lj/synta.yaml --exp_name lj_synta --reset # training in LJSpeech
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/biaobei/synta.yaml --exp_name biaobei_synta --reset # training in Biaobei
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/libritts/synta.yaml --exp_name libritts_synta --reset # training in LibriTTStensorboard --logdir=checkpoints/lj_synta
tensorboard --logdir=checkpoints/biaobei_synta
tensorboard --logdir=checkpoints/libritts_syntaCUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/lj/synta.yaml --exp_name lj_synta --reset --infer # inference in LJSpeech
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/biaobei/synta.yaml --exp_name biaobei_synta --reset --infer # inference in Biaobei
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/libritts/synta.yaml --exp_name libritts_synta --reset ---infer # inference in LibriTTS Des échantillons audio dans le papier se trouvent dans notre page de démonstration.
Nous fournissons également une page de démonstration HuggingFace pour LJSpeech. Essayez vos phrases intéressantes là-bas!
@article{ye2022syntaspeech,
title={SyntaSpeech: Syntax-Aware Generative Adversarial Text-to-Speech},
author={Ye, Zhenhui and Zhao, Zhou and Ren, Yi and Wu, Fei},
journal={arXiv preprint arXiv:2204.11792},
year={2022}
}
Nos codes sont basés sur les références suivantes:


