SyntaSpeech
Pretrained Models for LJ, Biaobei, and LibriTTS.
| | | 中文文档
Este repositório é a implementação oficial do Pytorch do nosso artigo IJCAI-2022, no qual propomos o SyntaSpeech para a sintaxe, com consciência de sintaxe, não autorregressiva, texto em fala.
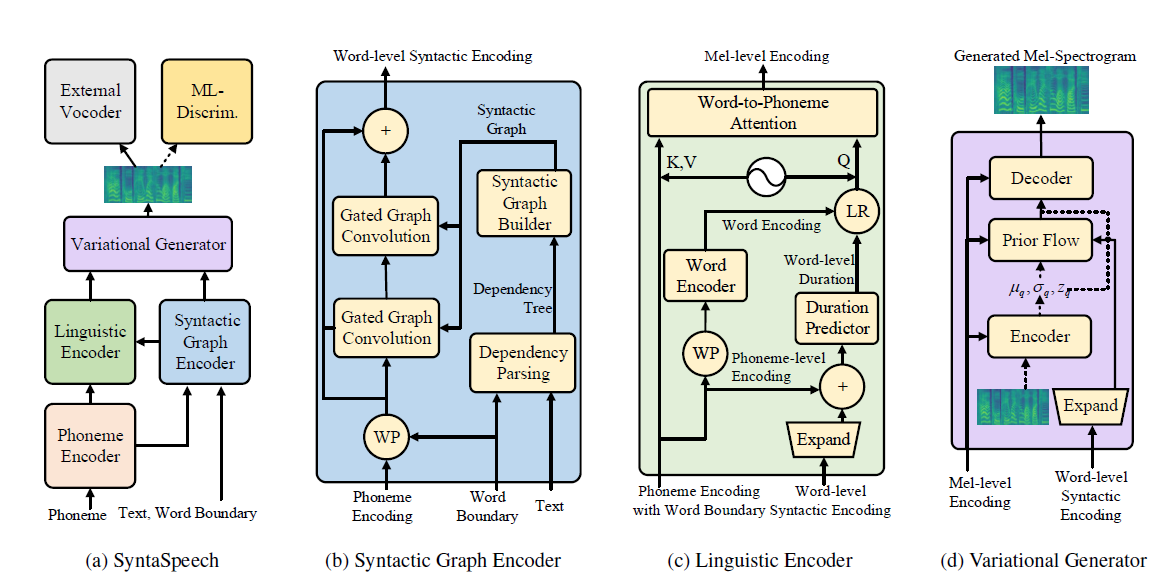
Nosso SyntaSpeech é construído com base no Portaspeech (Neurips 2021) com três novos recursos:
conda create -n synta python=3.7
condac activate synta
pip install -U pip
pip install Cython numpy==1.19.1
pip install torch==1.9.0
pip install -r requirements.txt
# install dgl for graph neural network, dgl-cu102 supports rtx2080, dgl-cu113 support rtx3090
pip install dgl-cu102 dglgo -f https://data.dgl.ai/wheels/repo.html
sudo apt install -y sox libsox-fmt-mp3
bash mfa_usr/install_mfa.sh # install force alignment tools Siga as etapas a seguir para executar este repositório.
Você pode usar diretamente nossos conjuntos de dados binarizados para LJSpeech e Biaobei. Faça o download e descompacte -os na pasta data/binary/ .
Quanto ao Libritts, você pode baixar os conjuntos de dados brutos e processá -los com nossos módulos data_gen . Instruções detalhadas podem ser encontradas em DOSC/preparar_data.
Fornecemos o modelo pré-treinado de vocoders para três conjuntos de dados. Especificamente, Hifi-Gan para LJSpeech e Biaobei, Parallelwavegan para Libritts. Faça o download e descompacte -os nos checkpoints/ pasta.
Em seguida, você pode treinar o SyntaSPeech nos três conjuntos de dados.
cd < the root_dir of your SyntaSpeech folder >
export PYTHONPATH=./
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/lj/synta.yaml --exp_name lj_synta --reset # training in LJSpeech
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/biaobei/synta.yaml --exp_name biaobei_synta --reset # training in Biaobei
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/libritts/synta.yaml --exp_name libritts_synta --reset # training in LibriTTStensorboard --logdir=checkpoints/lj_synta
tensorboard --logdir=checkpoints/biaobei_synta
tensorboard --logdir=checkpoints/libritts_syntaCUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/lj/synta.yaml --exp_name lj_synta --reset --infer # inference in LJSpeech
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/biaobei/synta.yaml --exp_name biaobei_synta --reset --infer # inference in Biaobei
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/libritts/synta.yaml --exp_name libritts_synta --reset ---infer # inference in LibriTTS Amostras de áudio no papel podem ser encontradas em nossa página de demonstração.
Também fornecemos a página de demonstração Huggingface para LJSpeech. Experimente suas frases interessantes lá!
@article{ye2022syntaspeech,
title={SyntaSpeech: Syntax-Aware Generative Adversarial Text-to-Speech},
author={Ye, Zhenhui and Zhao, Zhou and Ren, Yi and Wu, Fei},
journal={arXiv preprint arXiv:2204.11792},
year={2022}
}
Nossos códigos são baseados nos seguintes repositórios:


