SyntaSpeech
Pretrained Models for LJ, Biaobei, and LibriTTS.
| | | 中文文档
Repositori ini adalah implementasi Pytorch resmi dari makalah IJCAI-2022 kami, di mana kami mengusulkan syntaspeech untuk sintaks-sadar teks-ke-speech-to-speech.
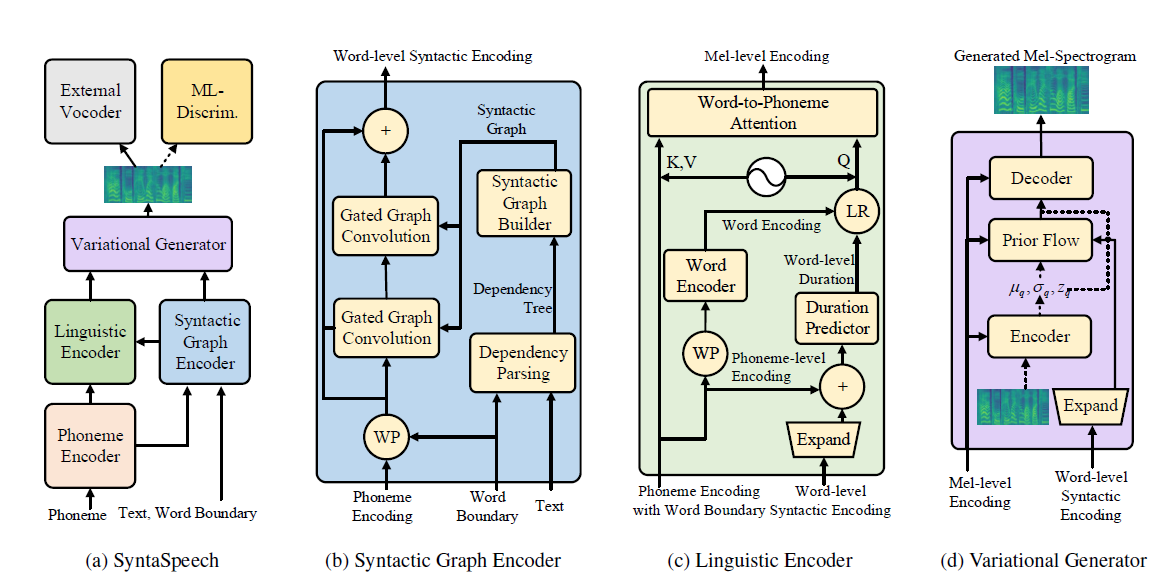
Sintaspeech kami dibangun berdasarkan portaspeech (Neurips 2021) dengan tiga fitur baru:
conda create -n synta python=3.7
condac activate synta
pip install -U pip
pip install Cython numpy==1.19.1
pip install torch==1.9.0
pip install -r requirements.txt
# install dgl for graph neural network, dgl-cu102 supports rtx2080, dgl-cu113 support rtx3090
pip install dgl-cu102 dglgo -f https://data.dgl.ai/wheels/repo.html
sudo apt install -y sox libsox-fmt-mp3
bash mfa_usr/install_mfa.sh # install force alignment tools Ikuti langkah -langkah berikut untuk menjalankan repo ini.
Anda dapat secara langsung menggunakan kumpulan data binarisasi kami untuk LJSpeech dan Biaobei. Unduh dan unzip ke dalam data/binary/ folder.
Sedangkan untuk Liblitts, Anda dapat mengunduh set data mentah dan memprosesnya dengan modul data_gen kami. Instruksi terperinci dapat ditemukan di Dosc/Prepared_data.
Kami menyediakan model vokoder pra-terlatih untuk tiga dataset. Secara khusus, HiFi-gan untuk ljspeech dan biaobei, paralelwavegan untuk libritts. Unduh dan unzip ke dalam checkpoints/ folder.
Kemudian Anda dapat melatih syntaspeech dalam tiga dataset.
cd < the root_dir of your SyntaSpeech folder >
export PYTHONPATH=./
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/lj/synta.yaml --exp_name lj_synta --reset # training in LJSpeech
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/biaobei/synta.yaml --exp_name biaobei_synta --reset # training in Biaobei
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/libritts/synta.yaml --exp_name libritts_synta --reset # training in LibriTTStensorboard --logdir=checkpoints/lj_synta
tensorboard --logdir=checkpoints/biaobei_synta
tensorboard --logdir=checkpoints/libritts_syntaCUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/lj/synta.yaml --exp_name lj_synta --reset --infer # inference in LJSpeech
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/biaobei/synta.yaml --exp_name biaobei_synta --reset --infer # inference in Biaobei
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/libritts/synta.yaml --exp_name libritts_synta --reset ---infer # inference in LibriTTS Sampel audio di koran dapat ditemukan di halaman demo kami.
Kami juga menyediakan halaman demo Huggingface untuk LJSPEECH. Coba kalimat menarik Anda di sana!
@article{ye2022syntaspeech,
title={SyntaSpeech: Syntax-Aware Generative Adversarial Text-to-Speech},
author={Ye, Zhenhui and Zhao, Zhou and Ren, Yi and Wu, Fei},
journal={arXiv preprint arXiv:2204.11792},
year={2022}
}
Kode kami didasarkan pada repo berikut:


