tts arabic pytorch
1.0.0
[樣品1] [樣品2] [ONNX模型] [Flutter App]
TTS模型(Tacotron2,FastPitch),接受了Nawar Halabi的阿拉伯語語音語料庫的培訓,其中包括用於直接TTS推理的Hifi-Gan Vocoder。
文件:
tacotron2 |天然TTS合成通過調節MEL譜圖預測(ARXIV)上的象徵
FastPitch | FastPitch:與音調預測(ARXIV)的平行文本對語音通話(ARXIV)
hifi-gan | HIFI-GAN:生成的對抗網絡,可高效和高保真語音綜合(ARXIV)
您可以在這裡收聽一些音頻樣本。
MultiSpeaker重量可用於FastPitch型號。目前,添加了另一種男性聲音和兩個女性聲音。音頻樣本可以在這裡找到。在這裡下載權重。此模型也存在一個ONNX版本。
通過將數據與Coqui的XTTS-V2模型合成數據,並從Tunisian_MSA數據集中合成多種聲音來創建多孔數據集。
如論文中所述,對模型進行了MSE損失訓練。我還使用其他對抗性損失(ADV)訓練了模型。區別不大,但我認為(ADV)版本通常聽起來有些清晰。您可以自己比較它們。
運行python download_files.py將下載所有預審預定的權重:
下載用於Tacotron2型號(MSE | ADV)的預算權重。
下載FastPitch型號(MSE | ADV)的預算權重。
下載Hifi-Gan Vocoder重量(鏈接)。將它們放入pretrained/hifigan-asc-v1中,或在configs/basic.yaml中編輯以下行。
# vocoder
vocoder_state_path : pretrained/hifigan-asc-v1/hifigan-asc.pth
vocoder_config_path : pretrained/hifigan-asc-v1/config.json此存儲庫包括Shakkala和Shakkelha的大氣壓模型。
權重可以在這裡下載。還有一個單獨的回購和包裝。
- >或者,下載所有型號,然後將ZIP文件的內容放入pretrained文件夾中。
torch torchaudio pyyaml
〜用於培訓: librosa matplotlib tensorboard
〜對於演示應用程序: fastapi "uvicorn[standard]"
Tacotron2 / FastPitch from models.tacotron2 / models.fastpitch是簡化文本與梅爾推斷的包裝器。 Tacotron2Wave / FastPitch2Wave模型包括用於直接文本到語音推理的Hifi-Gan Vocoder。
text = "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي."
wave = model . tts (
text_input = text , # input text
speed = 1 , # speaking speed
denoise = 0.005 , # HifiGAN denoiser strength
speaker_id = 0 , # speaker id
batch_size = 2 , # batch size for batched inference
vowelizer = None , # vowelizer model
pitch_mul = 1 , # pitch multiplier (for FastPitch)
pitch_add = 0 , # pitch offset (for FastPitch)
return_mel = False # return mel spectrogram?
) from models . tacotron2 import Tacotron2
model = Tacotron2 ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . fastpitch import FastPitch
model = FastPitch ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . tacotron2 import Tacotron2Wave
model = Tacotron2Wave ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ]) from models . fastpitch import FastPitch2Wave
model = FastPitch2Wave ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ])默認情況下,阿拉伯字母使用Buckwalter音譯轉換,也可以直接使用。
wave = model . tts ( ">als~alAmu Ealaykum yA Sadiyqiy." )
wave_list = model . tts ([ "Sifr" , "wAHid" , "<i^nAn" , "^alA^ap" , ">arbaEap" , "xamsap" , "sit~ap" , "sabEap" , "^amAniyap" , "tisEap" , "Ea$arap" ]) text_unvoc = "اللغة العربية هي أكثر اللغات السامية تحدثا، وإحدى أكثر اللغات انتشارا في العالم"
wave_shakkala = model . tts ( text_unvoc , vowelizer = 'shakkala' )
wave_shakkelha = model . tts ( text_unvoc , vowelizer = 'shakkelha' )python inference.py
# default parameters:
python inference.py --list data/infer_text.txt --out_dir samples/results --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --batch_size 2 --denoise 0測試模型運行:
python test.py
# default parameters:
python test.py --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --out_dir samples/test此存儲庫使用Nawar Halabi的阿拉伯語phonetiser,但簡化了結果,從而忽略了不同的上下文(請參閱text/symbols.py )。此外,兩倍的輔音表示為輔音 +加倍。
tacotron2模型有時可能會在句子以未經vocalized的輔音結束時發音。如果一個人在末端附加單詞分離器令牌並使用對齊權重切除( models.networks中的詳細信息),則發音更可靠。此選項是通過設置postprocess_mel=False可以禁用的默認後處理步驟實現的。
在培訓之前,必須重新採樣音頻文件。使用scripts/preprocess_audio.py預處理文件後,對該模型進行了訓練。
用配置文件運行中指定的選項訓練模型:
python train.py
# default parameters:
python train.py --config configs/nawar.yamlWeb應用程序使用FastAPI庫。要運行該應用程序,您需要以下軟件包:
FastApi:對於後端API | UVICORN:為應用程序服務
使用: pip install fastapi "uvicorn[standard]"
運行: python app.py
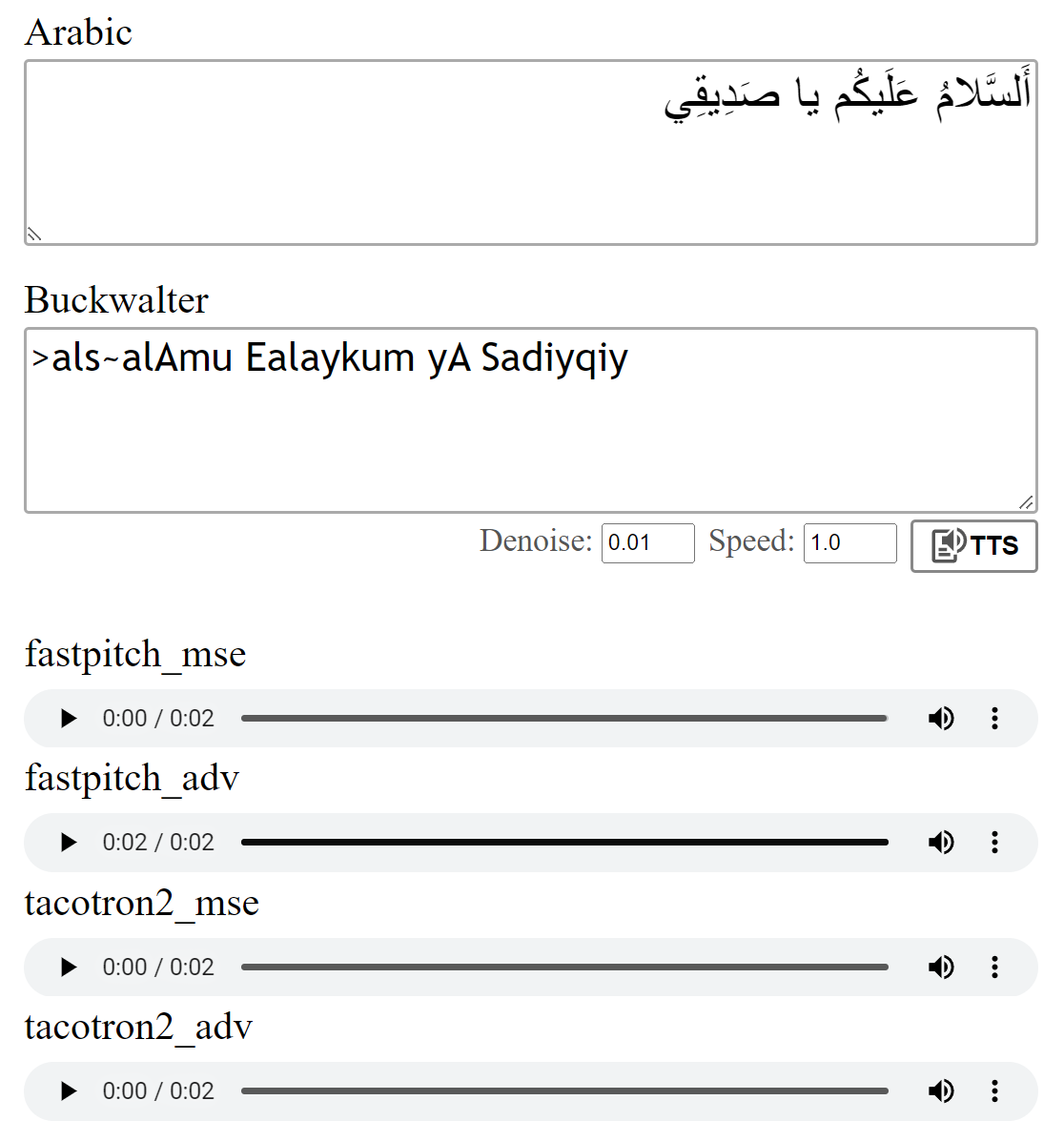
預覽:
我提到了NVIDIA的TACOTRON2實現,以了解模型培訓的詳細信息。
FastPitch文件源於Nvidia的深度學習示例


