tts arabic pytorch
1.0.0
[العينات 1] [العينات 2] [نماذج ONNX] [تطبيق flutter]
نماذج TTS (Tacotron2 ، fastpitch) ، تدرب على مجموعة الكلام العربي في نوار هالابي ، بما في ذلك المتفرج HIFI من أجل استنتاج TTS المباشر.
الأوراق:
Tacotron2 | تخليق TTS الطبيعي عن طريق تكييف Wavenet على تنبؤات طيفية MEL (ARXIV)
fastpitch | Fastpitch: نص متوازي إلى كلام مع التنبؤ بالملعب (ARXIV)
HIFI-GAN | HIFI-GAN: شبكات الخصومة التوليدية لتوليف خطاب الكفاءة والعالي الإخلاص (ARXIV)
يمكنك الاستماع إلى بعض عينات الصوت هنا.
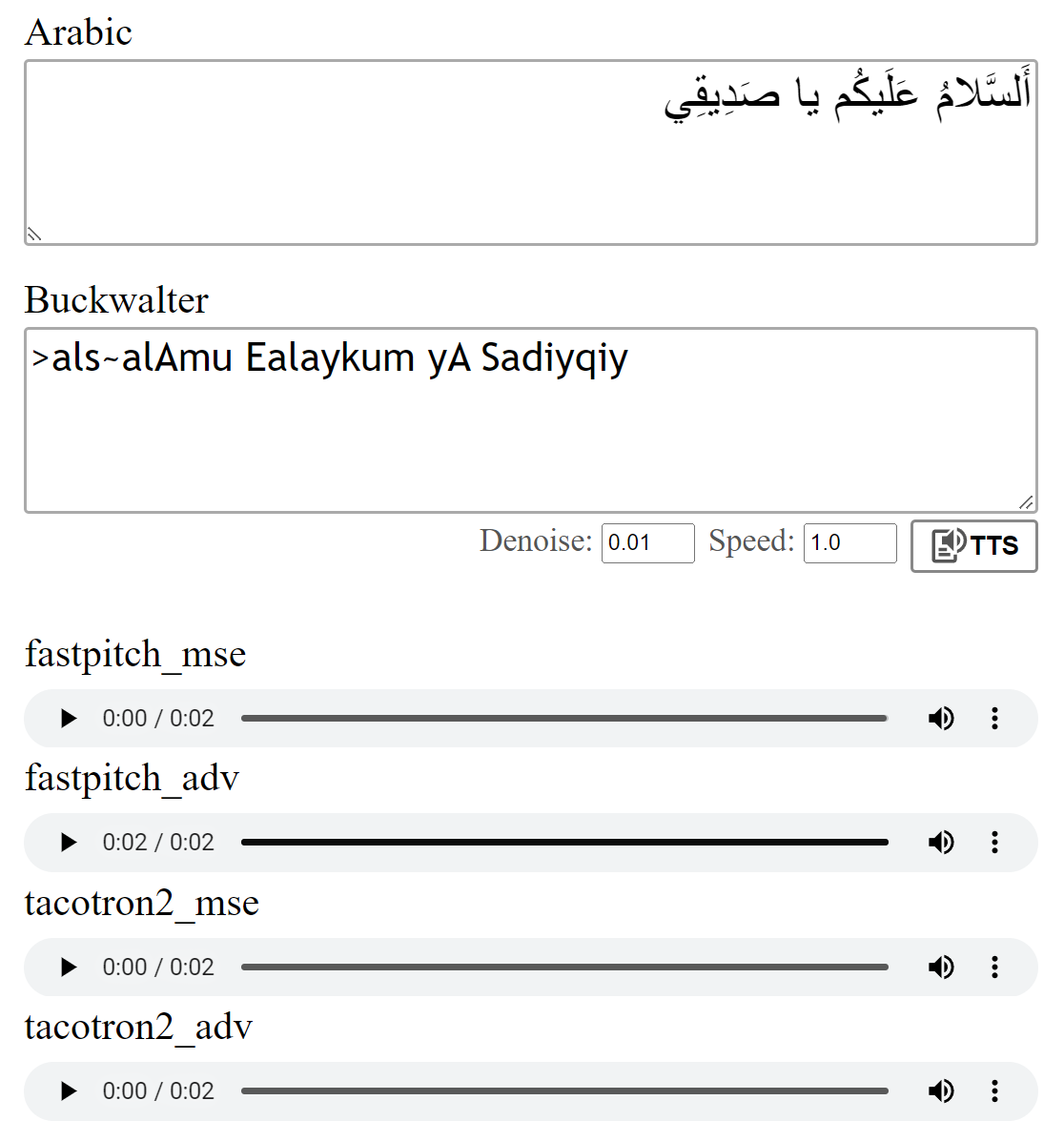
تتوفر أوزان متعددة الأوزان لطراز FastPitch. حاليا ، تمت إضافة صوت ذكر آخر وصوتان من الإناث. يمكن العثور على عينات الصوت هنا. تنزيل الأوزان هنا. يوجد أيضًا إصدار ONNX لهذا النموذج.
تم إنشاء مجموعة بيانات Multispeaker من خلال تصنيع البيانات مع نموذج XTTS-V2 من Coqui ومزيج من الأصوات من مجموعة بيانات Tonisian_MSA.
تم تدريب النماذج مع فقدان MSE كما هو موضح في الأوراق. قمت أيضًا بتدريب النماذج باستخدام خسارة عدوانية إضافية (ADV). الفرق ليس كبيرًا ، لكنني أعتقد أن إصدار (ADV) غالبًا ما يبدو أكثر وضوحًا. يمكنك مقارنةهم بنفسك.
سيقوم تشغيل python download_files.py بتنزيل جميع الأوزان المسبقة ، بدلاً من ذلك:
قم بتنزيل الأوزان المسبقة لنموذج Tacotron2 (MSE | ADV).
قم بتنزيل الأوزان المسبقة لنموذج FastPitch (MSE | ADV).
قم بتنزيل أوزان Vocoder HIFI-GAN (الرابط). إما أن تضعهم في pretrained/hifigan-asc-v1 أو تحرير الأسطر التالية في configs/basic.yaml .
# vocoder
vocoder_state_path : pretrained/hifigan-asc-v1/hifigan-asc.pth
vocoder_config_path : pretrained/hifigan-asc-v1/config.jsonيتضمن هذا الريبو نماذج تخطيط Shakkala و Shakkelha.
يمكن تنزيل الأوزان هنا. يوجد أيضًا ريبو وحزمة منفصلة.
-> بدلاً من ذلك ، قم بتنزيل جميع النماذج ووضع محتوى ملف zip في المجلد pretrained .
torch torchaudio pyyaml
~ للتدريب: librosa matplotlib tensorboard
~ للتطبيق التجريبي: fastapi "uvicorn[standard]"
Tacotron2 / FastPitch من models.tacotron2 / models.fastpitch هي مغلفات تبسيط استنتاج النص إلى mel. تتضمن طرز Tacotron2Wave / FastPitch2Wave المتفرجات HIFI من أجل الاستدلال المباشر من النص إلى كلام.
text = "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي."
wave = model . tts (
text_input = text , # input text
speed = 1 , # speaking speed
denoise = 0.005 , # HifiGAN denoiser strength
speaker_id = 0 , # speaker id
batch_size = 2 , # batch size for batched inference
vowelizer = None , # vowelizer model
pitch_mul = 1 , # pitch multiplier (for FastPitch)
pitch_add = 0 , # pitch offset (for FastPitch)
return_mel = False # return mel spectrogram?
) from models . tacotron2 import Tacotron2
model = Tacotron2 ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . fastpitch import FastPitch
model = FastPitch ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . tacotron2 import Tacotron2Wave
model = Tacotron2Wave ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ]) from models . fastpitch import FastPitch2Wave
model = FastPitch2Wave ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ])بشكل افتراضي ، يتم تحويل الحروف العربية باستخدام ترجمة Buckwalter ، والتي يمكن استخدامها أيضًا مباشرة.
wave = model . tts ( ">als~alAmu Ealaykum yA Sadiyqiy." )
wave_list = model . tts ([ "Sifr" , "wAHid" , "<i^nAn" , "^alA^ap" , ">arbaEap" , "xamsap" , "sit~ap" , "sabEap" , "^amAniyap" , "tisEap" , "Ea$arap" ]) text_unvoc = "اللغة العربية هي أكثر اللغات السامية تحدثا، وإحدى أكثر اللغات انتشارا في العالم"
wave_shakkala = model . tts ( text_unvoc , vowelizer = 'shakkala' )
wave_shakkelha = model . tts ( text_unvoc , vowelizer = 'shakkelha' )python inference.py
# default parameters:
python inference.py --list data/infer_text.txt --out_dir samples/results --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --batch_size 2 --denoise 0لاختبار تشغيل النموذج:
python test.py
# default parameters:
python test.py --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --out_dir samples/test يستخدم هذا الريبو نور هالابي-الفني العرب ، ولكنه يبسط النتيجة بحيث يتم تجاهل السياقات المختلفة (انظر text/symbols.py ). علاوة على ذلك ، يتم تمثيل ساكن مضاعف على أنه ساكن + مضاعفة.
يمكن أن يناضل نموذج Tacotron2 في بعض الأحيان من أجل نطق آخر صوتي من الجملة عندما ينتهي في ساكن غير متحيز. يكون النطق أكثر موثوقية إذا قام أحد بإلحاق رمز سباحة الكلمات في النهاية ويقطعه باستخدام أوزان المحاذاة (التفاصيل في models.networks ). يتم تنفيذ هذا الخيار كخطوة افتراضية بعد المعالجة التي يمكن تعطيلها عن طريق تعيين postprocess_mel=False .
قبل التدريب ، يجب إعادة تشكيل ملفات الصوت. تم تدريب النموذج بعد المعالجة المسبقة للملفات باستخدام scripts/preprocess_audio.py .
لتدريب النموذج بالخيارات المحددة في تشغيل ملف التكوين:
python train.py
# default parameters:
python train.py --config configs/nawar.yamlيستخدم تطبيق الويب مكتبة Fastapi. لتشغيل التطبيق ، تحتاج إلى الحزم التالية:
Fastapi: لخلفية API | Uvicorn: لخدمة التطبيق
تثبيت مع: pip install fastapi "uvicorn[standard]"
تشغيل مع: python app.py
معاينة:
أشرت إلى تطبيق Tacotron2 من NVIDIA للحصول على تفاصيل حول التدريب النموذجي.
تنبع ملفات fastpitch من أمثلة Nvidia's DeepLearningex


