tts arabic pytorch
1.0.0
[サンプル1] [サンプル2] [ONNXモデル] [フラッターアプリ]
TTSモデル(Tacotron2、FastPitch)、直接TTS推論のためのHifi-Gan Vocoderを含むNawar Halabiのアラビア語の音声コーパスで訓練されています。
論文:
tacotron2 | MEL Spectrogram Predictions(arxiv)に波線を条件付けすることによる天然TTS合成
FastPitch | FastPitch:ピッチ予測を備えた並列テキストからスピーチ(ARXIV)
hifi-gan | HIFI-GAN:効率的で高忠実度の音声合成のための生成敵意ネットワーク(ARXIV)
ここでいくつかのオーディオサンプルを聴くことができます。
Multispeakerウェイトは、FastPitchモデルで利用できます。現在、別の男性の声と2つの女性の声が追加されています。オーディオサンプルはここにあります。ここからウェイトをダウンロードしてください。また、このモデルにはONNXバージョンも存在します。
Multispeakerデータセットは、CoquiのXTTS-V2モデルとTunisian_MSAデータセットの声の組み合わせでデータを合成することによって作成されました。
モデルは、論文に記載されているように、MSE損失で訓練されました。また、追加の敵対的損失(ADV)を使用してモデルを訓練しました。違いは大きくありませんが、(ADV)バージョンはしばしば少し明確に聞こえると思います。自分で比較できます。
python download_files.py実行すると、すべての前提条件の重みがダウンロードされます。
Tacotron2モデル(MSE | ADV)の前提条件の重みをダウンロードします。
FastPitchモデル(MSE | ADV)の前提条件の重みをダウンロードします。
Hifi-Gan Vocoder Weights(リンク)をダウンロードします。それらをpretrained/hifigan-asc-v1に入れるか、 configs/basic.yamlの次の行を編集します。
# vocoder
vocoder_state_path : pretrained/hifigan-asc-v1/hifigan-asc.pth
vocoder_config_path : pretrained/hifigan-asc-v1/config.jsonこのレポは、Diacritization Models ShakkalaとShakkelhaが含まれています。
ウェイトはここからダウンロードできます。別のレポとパッケージも存在します。
- >あるいは、すべてのモデルをダウンロードして、ZIPファイルのコンテンツをpretrainedフォルダーに配置します。
torch torchaudio pyyaml
〜トレーニング用: librosa matplotlib tensorboard
〜デモアプリの場合: fastapi "uvicorn[standard]"
models.tacotron2からのTacotron2 / FastPitch / models.fastpitchは、テキストからメルの推論を簡素化するラッパーです。 Tacotron2Wave / FastPitch2Waveモデルには、直接テキストからスピーチへの推論のためのHIFI-GANボコーダーが含まれています。
text = "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي."
wave = model . tts (
text_input = text , # input text
speed = 1 , # speaking speed
denoise = 0.005 , # HifiGAN denoiser strength
speaker_id = 0 , # speaker id
batch_size = 2 , # batch size for batched inference
vowelizer = None , # vowelizer model
pitch_mul = 1 , # pitch multiplier (for FastPitch)
pitch_add = 0 , # pitch offset (for FastPitch)
return_mel = False # return mel spectrogram?
) from models . tacotron2 import Tacotron2
model = Tacotron2 ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . fastpitch import FastPitch
model = FastPitch ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . tacotron2 import Tacotron2Wave
model = Tacotron2Wave ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ]) from models . fastpitch import FastPitch2Wave
model = FastPitch2Wave ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ])デフォルトでは、アラビア文字は、Buckwalterの音訳を使用して変換されます。これは直接使用できます。
wave = model . tts ( ">als~alAmu Ealaykum yA Sadiyqiy." )
wave_list = model . tts ([ "Sifr" , "wAHid" , "<i^nAn" , "^alA^ap" , ">arbaEap" , "xamsap" , "sit~ap" , "sabEap" , "^amAniyap" , "tisEap" , "Ea$arap" ]) text_unvoc = "اللغة العربية هي أكثر اللغات السامية تحدثا، وإحدى أكثر اللغات انتشارا في العالم"
wave_shakkala = model . tts ( text_unvoc , vowelizer = 'shakkala' )
wave_shakkelha = model . tts ( text_unvoc , vowelizer = 'shakkelha' )python inference.py
# default parameters:
python inference.py --list data/infer_text.txt --out_dir samples/results --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --batch_size 2 --denoise 0モデルの実行をテストするには:
python test.py
# default parameters:
python test.py --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --out_dir samples/testこのレポでは、Nawar Halabiのアラビア語の害虫術師を使用しますが、結果を簡素化して、異なるコンテキストが無視されるようになります( text/symbols.pyを参照)。さらに、子音が倍増したものが子音 +ダブルトークンとして表されます。
Tacotron2モデルは、局所化されていない子音で終わるときに、文の最後の音素を発音するのに苦労することがあります。発音は、最後に単語セパレータトークンを追加し、アライメント重み( models.networksの詳細)を使用してそれを切り取る場合、より信頼性が高くなります。このオプションはpostprocess_mel=Falseを設定することで無効にできるデフォルトのポストプロセスステップとして実装されます。
トレーニング前に、オーディオファイルを再サンプリングする必要があります。このモデルはscripts/preprocess_audio.pyを使用してファイルを前処理した後にトレーニングされました。
構成ファイルで指定されたオプションを使用してモデルをトレーニングするには:
python train.py
# default parameters:
python train.py --config configs/nawar.yamlWebアプリはFastapiライブラリを使用します。アプリを実行するには、次のパッケージが必要です。
FASTAPI:バックエンドAPIの場合| Uvicorn:アプリを提供するため
インストール: pip install fastapi "uvicorn[standard]"
実行: python app.py
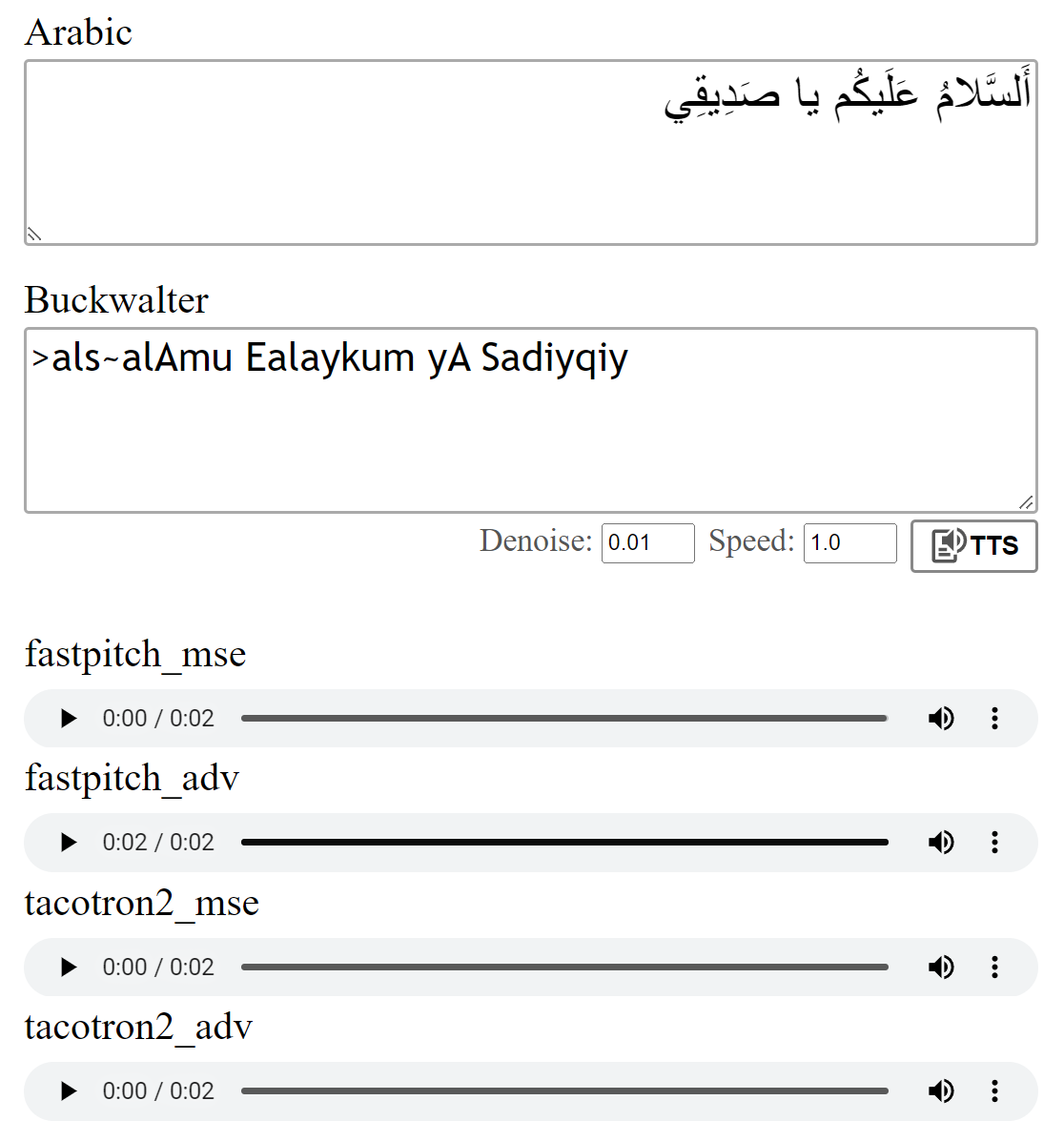
プレビュー:
モデルトレーニングの詳細については、NvidiaのTacotron2実装について言及しました。
FastPitchファイルは、Nvidiaのdeeplearningexamplesに由来しています


