tts arabic pytorch
1.0.0
[샘플 1] [샘플 2] [Onnx 모델] [Flutter App]
TTS 모델 (Tacotron2, Fastpitch)은 직접 TTS 추론을위한 Hifi-Gan 보코더를 포함하여 Nawar Halabi의 아랍어 연설 코퍼스에 대해 교육을 받았습니다.
서류:
타코 트론 2 | Mel Spectrogram Predictions에서 컨디셔닝 Wavenet에 의한 천연 TTS 합성 (ARXIV)
Fastpitch | Fastpitch : 피치 예측이있는 병렬 텍스트 음성 (ARXIV)
Hifi-gan | Hifi-gan : 효율적이고 고 충실도 음성 합성을위한 생성 적대적 네트워크 (ARXIV)
여기에서 일부 오디오 샘플을들을 수 있습니다.
Fastpitch 모델에는 멀티 스피커 가중치를 사용할 수 있습니다. 현재 또 다른 남성 목소리와 두 명의 여성 목소리가 추가되었습니다. 오디오 샘플은 여기에서 찾을 수 있습니다. 여기에서 가중치를 다운로드하십시오. 이 모델에 대한 ONNX 버전도 있습니다.
멀티 스피커 데이터 세트는 Coqui의 XTTS-v2 모델과 Tunisian_MSA 데이터 세트의 음성 혼합으로 데이터를 합성하여 생성되었습니다.
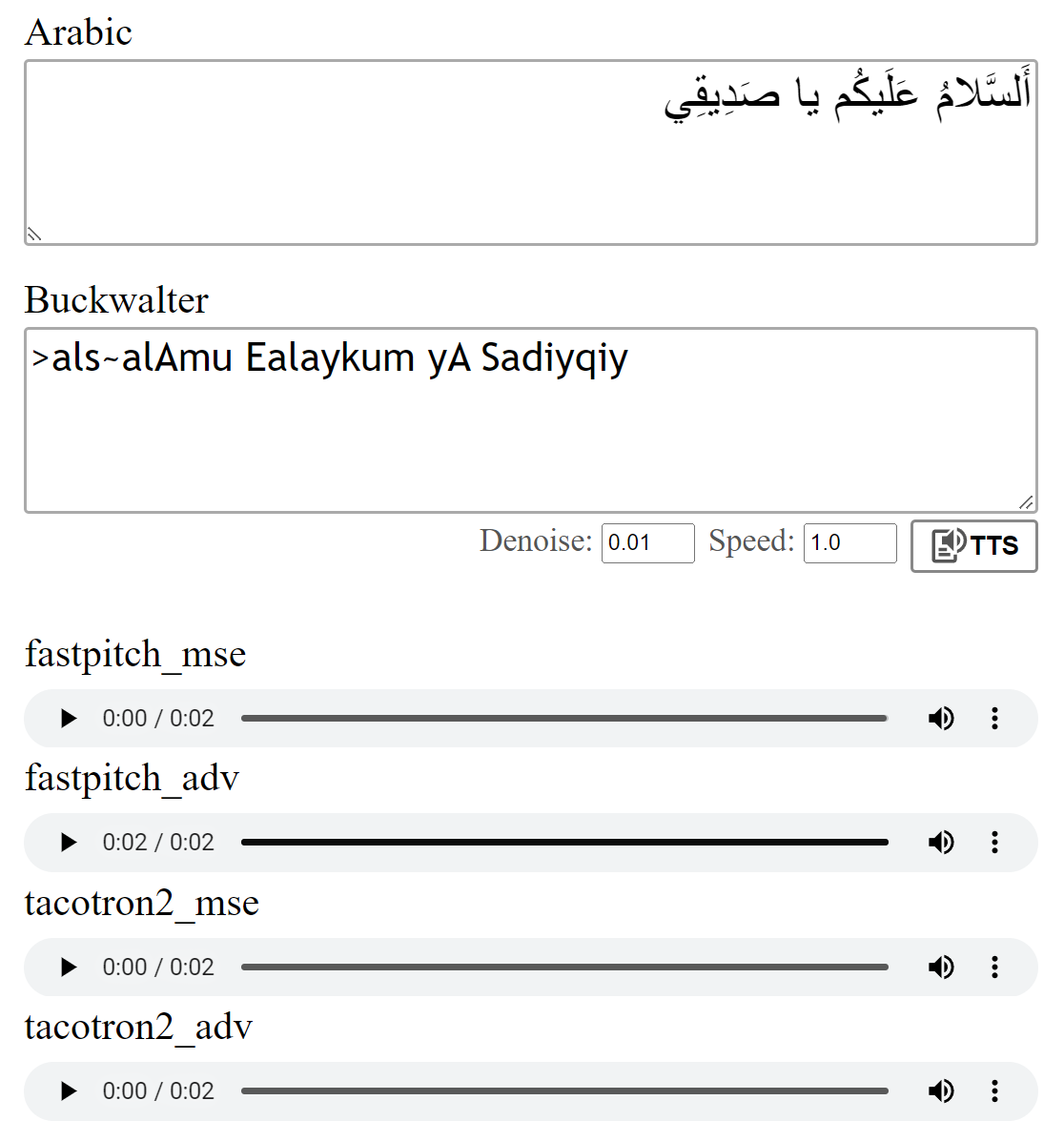
이 모델은 논문에 설명 된대로 MSE 손실로 훈련되었습니다. 또한 추가의 적대적 손실 (ADV)을 사용하여 모델을 교육했습니다. 차이는 크지 않지만 (ADV) 버전이 종종 조금 더 명확하게 들린다고 생각합니다. 당신은 그들을 직접 비교할 수 있습니다.
Python running python download_files.py 실행하면 모든 사전 미세 가중치가 다운로드됩니다.
Tacotron2 모델 (MSE | adv)의 사전 가중치를 다운로드하십시오.
Fastpitch Model (MSE | ADV)의 사전 배치 된 가중치를 다운로드하십시오.
Hifi-gan 보코더 가중치 (링크)를 다운로드하십시오. pretrained/hifigan-asc-v1 에 넣거나 configs/basic.yaml 에서 다음 줄을 편집하십시오.
# vocoder
vocoder_state_path : pretrained/hifigan-asc-v1/hifigan-asc.pth
vocoder_config_path : pretrained/hifigan-asc-v1/config.json이 repo에는 Shakkala와 Shakkelha가 디아크리닝 모델이 포함되어 있습니다.
가중치는 여기에서 다운로드 할 수 있습니다. 별도의 리포와 패키지도 있습니다.
-> 또는 대안 적으로 모든 모델을 다운로드하고 ZIP 파일의 내용을 pretrained 폴더에 넣으십시오.
torch torchaudio pyyaml
~ 훈련 : librosa matplotlib tensorboard
~ 데모 앱의 경우 : fastapi "uvicorn[standard]"
models.tacotron2 / models.fastpitch 의 Tacotron2 / FastPitch 는 텍스트-멜로 추론을 단순화하는 포장지입니다. Tacotron2Wave / FastPitch2Wave 모델에는 직접 텍스트 음성 연기 추론을위한 Hifi-gan 보코더가 포함되어 있습니다.
text = "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي."
wave = model . tts (
text_input = text , # input text
speed = 1 , # speaking speed
denoise = 0.005 , # HifiGAN denoiser strength
speaker_id = 0 , # speaker id
batch_size = 2 , # batch size for batched inference
vowelizer = None , # vowelizer model
pitch_mul = 1 , # pitch multiplier (for FastPitch)
pitch_add = 0 , # pitch offset (for FastPitch)
return_mel = False # return mel spectrogram?
) from models . tacotron2 import Tacotron2
model = Tacotron2 ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . fastpitch import FastPitch
model = FastPitch ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . tacotron2 import Tacotron2Wave
model = Tacotron2Wave ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ]) from models . fastpitch import FastPitch2Wave
model = FastPitch2Wave ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ])기본적으로 아랍어 문자는 Buckwalter 음역을 사용하여 변환되며 직접 사용할 수 있습니다.
wave = model . tts ( ">als~alAmu Ealaykum yA Sadiyqiy." )
wave_list = model . tts ([ "Sifr" , "wAHid" , "<i^nAn" , "^alA^ap" , ">arbaEap" , "xamsap" , "sit~ap" , "sabEap" , "^amAniyap" , "tisEap" , "Ea$arap" ]) text_unvoc = "اللغة العربية هي أكثر اللغات السامية تحدثا، وإحدى أكثر اللغات انتشارا في العالم"
wave_shakkala = model . tts ( text_unvoc , vowelizer = 'shakkala' )
wave_shakkelha = model . tts ( text_unvoc , vowelizer = 'shakkelha' )python inference.py
# default parameters:
python inference.py --list data/infer_text.txt --out_dir samples/results --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --batch_size 2 --denoise 0모델 실행을 테스트하려면 :
python test.py
# default parameters:
python test.py --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --out_dir samples/test 이 저장소는 Nawar Halabi의 아라비아 포도주를 사용하지만 다른 컨텍스트가 무시되도록 결과를 단순화합니다 ( text/symbols.py 참조). 또한, 두 배의 자음은 자음 + 이중화로 표시됩니다.
Tacotron2 모델은 때때로 비율이없는 자음으로 끝날 때 문장의 마지막 음소를 발음하기 위해 고군분투 할 수 있습니다. 끝에 Word-Separator 토큰을 추가하고 정렬 가중치 ( models.networks 의 세부 사항)를 사용하여 절단하면 발음이 더 신뢰할 수 있습니다. 이 옵션은 postprocess_mel=False 설정하여 비활성화 할 수있는 기본 후 처리 단계로 구현됩니다.
교육 전에 오디오 파일을 리샘플링해야합니다. scripts/preprocess_audio.py 사용하여 파일을 사전 처리 한 후 모델이 교육을 받았습니다.
구성 파일 실행에 지정된 옵션으로 모델을 교육하려면 다음과 같습니다.
python train.py
# default parameters:
python train.py --config configs/nawar.yaml웹 앱은 Fastapi 라이브러리를 사용합니다. 앱을 실행하려면 다음 패키지가 필요합니다.
Fastapi : 백엔드 API 용 | Uvicorn : 앱을 제공합니다
설치 : pip install fastapi "uvicorn[standard]"
: python app.py 와 함께 실행하십시오
시사:
모델 교육에 대한 자세한 내용은 Nvidia의 Tacotron2 구현을 언급했습니다.
Fastpitch 파일은 Nvidia의 DeeplearningExamples에서 비롯됩니다


