tts arabic pytorch
1.0.0
[Échantillons 1] [Échantillons 2] [Modèles ONNX] [Application Flutter]
Les modèles TTS (Tacotron2, Fastpitch), formés sur le corpus de la parole arabe de Nawar Halabi, y compris le vocodeur Hifi-Gan pour l'inférence TTS directe.
Papiers:
Tacotron2 | Synthèse TTS naturelle en conditionnant les prédictions du wavenet sur le spectrogramme MEL (ARXIV)
FastPitch | FASTPITCH: Texte à dis en parallèle avec prédiction de hauteur (ARXIV)
Hifi-gan | HIFI-GAN: Réseaux adversaires génératifs pour la synthèse de la parole efficace et haute fidélité (ARXIV)
Vous pouvez écouter quelques échantillons audio ici.
Des poids multicolores sont disponibles pour le modèle FastPitch. Actuellement, une autre voix masculine et deux voix féminines ont été ajoutées. Des échantillons audio peuvent être trouvés ici. Téléchargez des poids ici. Il existe également une version ONNX pour ce modèle.
L'ensemble de données multispeaker a été créé en synthétisant des données avec le modèle XTTS-V2 de Coqui et un mélange de voix de l'ensemble de données tunisien_msa.
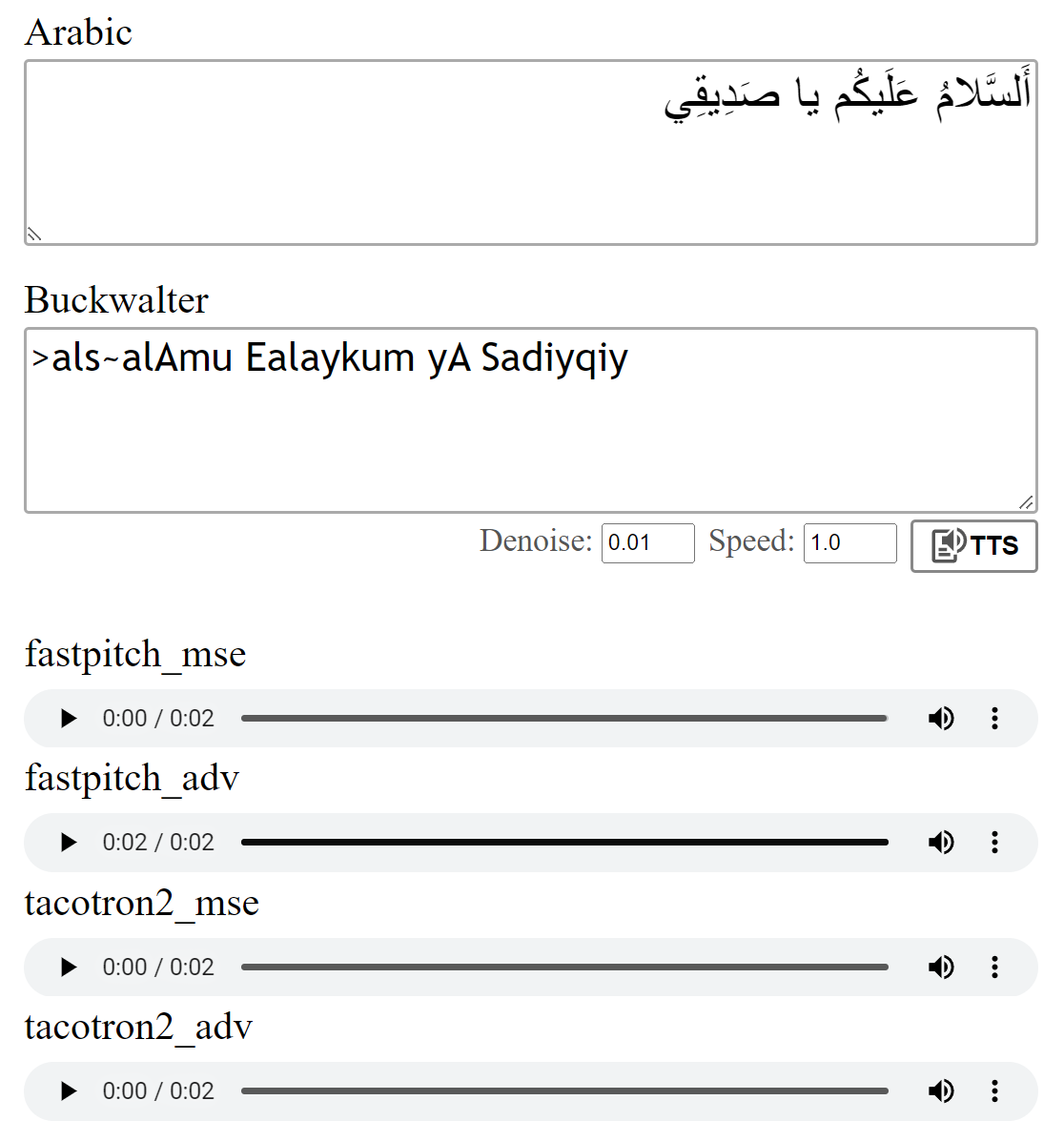
Les modèles ont été formés avec la perte MSE comme décrit dans les journaux. J'ai également formé les modèles en utilisant une perte adversaire supplémentaire (ADV). La différence n'est pas grande, mais je pense que la version (ADV) semble souvent un peu plus claire. Vous pouvez les comparer vous-même.
Running python download_files.py téléchargera tous les poids pré-entraînés, alternativement:
Téléchargez les poids pré-entraînés pour le modèle Tacotron2 (MSE | ADV).
Téléchargez les poids pré-entraînés pour le modèle FastPitch (MSE | ADV).
Téléchargez les poids de vocoder Hifi-gan (lien). Soit les mettre dans pretrained/hifigan-asc-v1 ou modifiez les lignes suivantes dans configs/basic.yaml .
# vocoder
vocoder_state_path : pretrained/hifigan-asc-v1/hifigan-asc.pth
vocoder_config_path : pretrained/hifigan-asc-v1/config.jsonCe dépôt comprend les modèles de diacritisation Shakkala et Shakkelha.
Les poids peuvent être téléchargés ici. Il existe également un référentiel et un package distinct.
-> Alternativement, téléchargez tous les modèles et placez le contenu du fichier zip dans le dossier pretrained .
torch torchaudio pyyaml
~ pour la formation: librosa matplotlib tensorboard
~ Pour l'application de démonstration: fastapi "uvicorn[standard]"
Le Tacotron2 / FastPitch de models.tacotron2 / models.fastpitch sont des emballages qui simplifient l'inférence du texte à mel. Les modèles Tacotron2Wave / FastPitch2Wave comprennent le vocodeur HIFI-AG pour l'inférence directe du texte-dispection.
text = "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي."
wave = model . tts (
text_input = text , # input text
speed = 1 , # speaking speed
denoise = 0.005 , # HifiGAN denoiser strength
speaker_id = 0 , # speaker id
batch_size = 2 , # batch size for batched inference
vowelizer = None , # vowelizer model
pitch_mul = 1 , # pitch multiplier (for FastPitch)
pitch_add = 0 , # pitch offset (for FastPitch)
return_mel = False # return mel spectrogram?
) from models . tacotron2 import Tacotron2
model = Tacotron2 ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . fastpitch import FastPitch
model = FastPitch ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . tacotron2 import Tacotron2Wave
model = Tacotron2Wave ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ]) from models . fastpitch import FastPitch2Wave
model = FastPitch2Wave ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ])Par défaut, les lettres arabes sont converties à l'aide de la translittération BuckWalter, qui peut également être utilisée directement.
wave = model . tts ( ">als~alAmu Ealaykum yA Sadiyqiy." )
wave_list = model . tts ([ "Sifr" , "wAHid" , "<i^nAn" , "^alA^ap" , ">arbaEap" , "xamsap" , "sit~ap" , "sabEap" , "^amAniyap" , "tisEap" , "Ea$arap" ]) text_unvoc = "اللغة العربية هي أكثر اللغات السامية تحدثا، وإحدى أكثر اللغات انتشارا في العالم"
wave_shakkala = model . tts ( text_unvoc , vowelizer = 'shakkala' )
wave_shakkelha = model . tts ( text_unvoc , vowelizer = 'shakkelha' )python inference.py
# default parameters:
python inference.py --list data/infer_text.txt --out_dir samples/results --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --batch_size 2 --denoise 0Pour tester l'exécution du modèle:
python test.py
# default parameters:
python test.py --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --out_dir samples/test Ce repo utilise le phonétiseur arabe de Nawar Halabi mais simplifie le résultat tel que différents contextes sont ignorés (voir text/symbols.py ). De plus, une consonne doublée est représentée comme consonne + double-token.
Le modèle Tacotron2 peut parfois avoir du mal à prononcer le dernier phonème d'une phrase lorsqu'il se termine par une consonne non vocalisée. La prononciation est plus fiable si l'on ajoute un jeton de séparation de mots à la fin et le coupe en utilisant les poids d'alignements (détails dans models.networks ). Cette option est implémentée en tant qu'étape de post-traitement par défaut qui peut être désactivée en définissant postprocess_mel=False .
Avant la formation, les fichiers audio doivent être rééchantillonnés. Le modèle a été formé après le prétraitement des fichiers à l'aide scripts/preprocess_audio.py .
Pour former le modèle avec des options spécifiées dans le fichier de configuration Exécuter:
python train.py
# default parameters:
python train.py --config configs/nawar.yamlL'application Web utilise la bibliothèque Fastapi. Pour exécuter l'application, vous avez besoin des packages suivants:
Fastapi: pour l'API backend | Uvicorn: pour servir l'application
Installer avec: pip install fastapi "uvicorn[standard]"
Exécutez avec: python app.py
Aperçu:
J'ai fait référence à l'implémentation Tacotron2 de Nvidia pour plus de détails sur la formation des modèles.
Les fichiers FastPitch proviennent de DeepLearning Examples de Nvidia


