tts arabic pytorch
1.0.0
[Образцы 1] [Образцы 2] [модели ONNX] [Flutter App]
Модели TTS (Tacotron2, FastPitch), обученные арабскому речевому корпусу Навар Халаби, включая вокадчик Hifi-Gan для прямого вывода TTS.
Документы:
Tacotron2 | Естественный синтез TTS путем кондиционирования Wavenet на предсказаниях спектрограммы MEL (ARXIV)
FastPitch | FastPitch: параллельный текст в речь с прогнозированием танга (ARXIV)
Hifi-gan | Hifi-Gan: Генеративные состязательные сети для эффективного и высокого синтеза речи (ARXIV)
Вы можете послушать некоторые образцы аудио здесь.
Веса для мультиспикер доступны для модели FastPitch. В настоящее время были добавлены еще один мужской голос и два женских голоса. Образцы аудио можно найти здесь. Скачать веса здесь. Также существует версия ONNX для этой модели.
Набор данных Multipeaker был создан путем синтеза данных с моделью Coqui XTTS-V2 и сочетанием голосов из набора данных TUNISIAN_MSA.
Модели были обучены потерей MSE, как описано в документах. Я также обучил модели, используя дополнительную состязательную потерю (ADV). Разница не большая, но я думаю, что версия (ADV) часто звучит немного яснее. Вы можете сравнить их самостоятельно.
Запуск python download_files.py будет загружать все предварительно подготовленные веса, альтернативно:
Загрузите предварительные веса для модели Tacotron2 (MSE | ADV).
Загрузите предварительные веса для модели FastPitch (MSE | ADV).
Загрузите вес Vocoder Hifi-Gan (ссылка). Либо поместите их в pretrained/hifigan-asc-v1 , либо отредактируйте следующие строки в configs/basic.yaml .
# vocoder
vocoder_state_path : pretrained/hifigan-asc-v1/hifigan-asc.pth
vocoder_config_path : pretrained/hifigan-asc-v1/config.jsonЭто репо включает в себя модели диакритизации Shakkala и Shakkelha.
Веса можно скачать здесь. Также существует отдельная репо и пакет.
-> В качестве альтернативы, загрузите все модели и поместите содержание zip -файла в pretrained папку.
torch torchaudio pyyaml
~ Для обучения: librosa matplotlib tensorboard
~ Для демонстрационного приложения: fastapi "uvicorn[standard]"
Tacotron2 / FastPitch из models.tacotron2 / models.fastpitch -это обертки, которые упрощают вывод текста в мелу. Модели Tacotron2Wave / FastPitch2Wave включают в себя hifi-gan Vocoder для прямого вывода текста в речь.
text = "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي."
wave = model . tts (
text_input = text , # input text
speed = 1 , # speaking speed
denoise = 0.005 , # HifiGAN denoiser strength
speaker_id = 0 , # speaker id
batch_size = 2 , # batch size for batched inference
vowelizer = None , # vowelizer model
pitch_mul = 1 , # pitch multiplier (for FastPitch)
pitch_add = 0 , # pitch offset (for FastPitch)
return_mel = False # return mel spectrogram?
) from models . tacotron2 import Tacotron2
model = Tacotron2 ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . fastpitch import FastPitch
model = FastPitch ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . tacotron2 import Tacotron2Wave
model = Tacotron2Wave ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ]) from models . fastpitch import FastPitch2Wave
model = FastPitch2Wave ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ])По умолчанию арабские буквы преобразуются с использованием транслитерации Buckwalter, которая также может использоваться напрямую.
wave = model . tts ( ">als~alAmu Ealaykum yA Sadiyqiy." )
wave_list = model . tts ([ "Sifr" , "wAHid" , "<i^nAn" , "^alA^ap" , ">arbaEap" , "xamsap" , "sit~ap" , "sabEap" , "^amAniyap" , "tisEap" , "Ea$arap" ]) text_unvoc = "اللغة العربية هي أكثر اللغات السامية تحدثا، وإحدى أكثر اللغات انتشارا في العالم"
wave_shakkala = model . tts ( text_unvoc , vowelizer = 'shakkala' )
wave_shakkelha = model . tts ( text_unvoc , vowelizer = 'shakkelha' )python inference.py
# default parameters:
python inference.py --list data/infer_text.txt --out_dir samples/results --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --batch_size 2 --denoise 0Чтобы проверить запуск модели:
python test.py
# default parameters:
python test.py --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --out_dir samples/test В этом репо используется арабский фонетизер Навар Халаби, но упрощает результат, так что различные контексты игнорируются (см. text/symbols.py ). Кроме того, удвоенный согласный представлен как согласный + удвоенный ток.
Модель Tacotron2 иногда может изо всех сил пытаться произнести последнюю фонему предложения, когда она заканчивается в невокализованном согласном. Произношение более надежно, если кто-то добавляет токен сепаратора Word в конце и отрезает его, используя веса выравнивания (детали в models.networks ). Эта опция реализована как шаг постобработки по умолчанию, который можно отключить, установив postprocess_mel=False .
Перед тренировкой аудиофайлы должны быть повторно подключены. Модель была обучена после предварительной обработки файлов с помощью scripts/preprocess_audio.py .
Чтобы обучить модель с параметрами, указанными в файле конфигурации:
python train.py
# default parameters:
python train.py --config configs/nawar.yamlВеб -приложение использует библиотеку Fastapi. Чтобы запустить приложение, вам нужны следующие пакеты:
FOSTAPI: для бэкэнд API | Uvicorn: для обслуживания приложения
Установите с: pip install fastapi "uvicorn[standard]"
Запустить с: python app.py
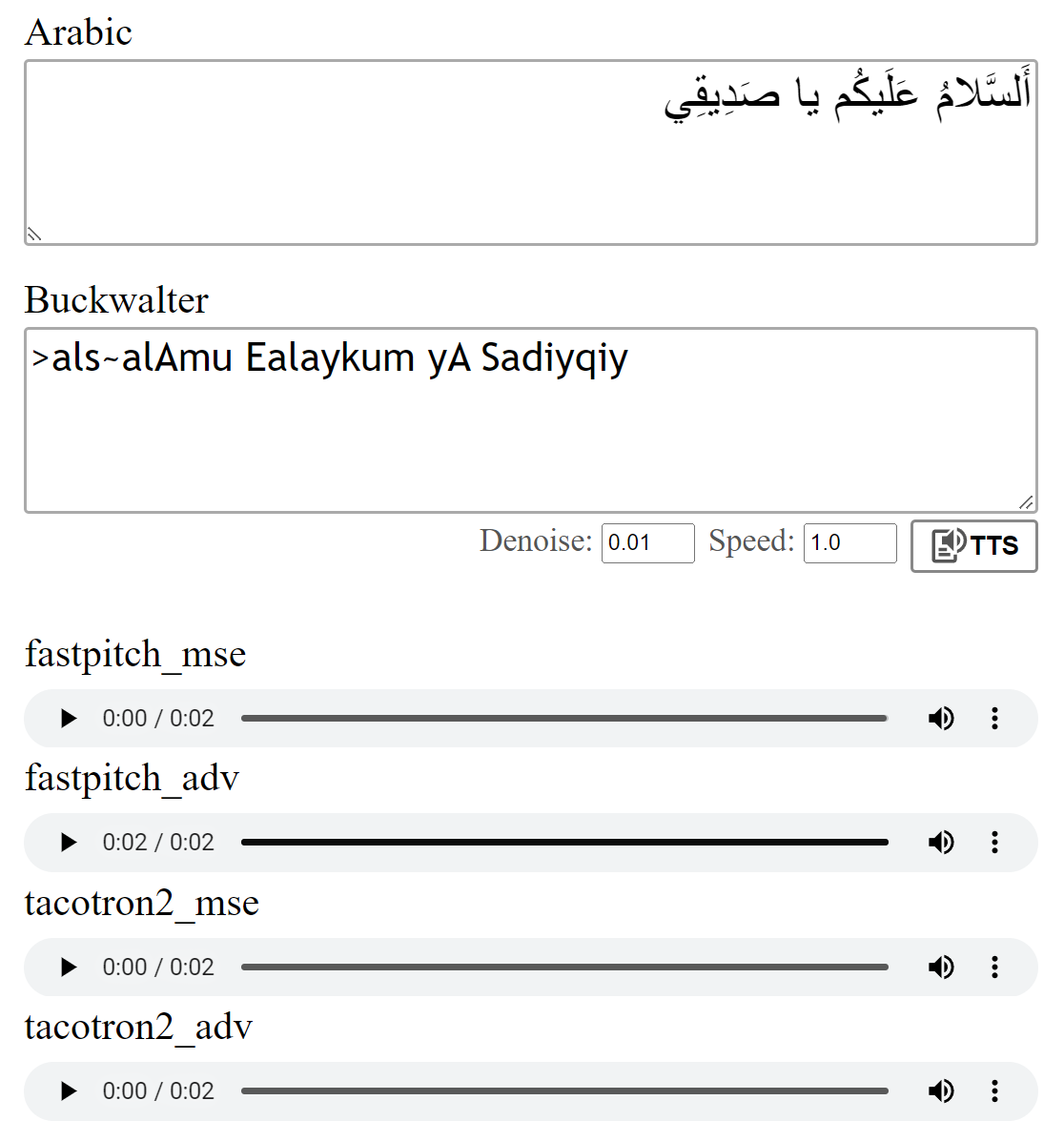
Предварительный просмотр:
Я сослался на реализацию NVIDIA Tacotron2 для получения подробной информации о модельном обучении.
Файлы FastPitch вытекают из DeepLearningExamples Nvidia


