tts arabic pytorch
1.0.0
[Sampel 1] [Sampel 2] [Model ONNX] [Aplikasi Flutter]
Model TTS (Tacotron2, FastPitch), dilatih di Corpus Pidato Arab Nawar Halabi, termasuk Vocoder HiFi-Gan untuk Inferensi TTS Langsung.
Dokumen:
Tacotron2 | Sintesis TTS Alami dengan mengondisikan Wavenet pada prediksi spektrogram MEL (ARXIV)
Fastpitch | FastPitch: Teks-ke-Speech Paralel dengan Prediksi Pitch (ARXIV)
Hifi-gan | HIFI-GAN: Jaringan permusuhan generatif untuk sintesis ucapan kesetiaan yang efisien dan tinggi (ARXIV)
Anda dapat mendengarkan beberapa sampel audio di sini.
Bobot multispeaker tersedia untuk model FastPitch. Saat ini, suara pria lain dan dua suara wanita telah ditambahkan. Sampel audio dapat ditemukan di sini. Unduh beban di sini. Ada juga versi ONNX untuk model ini.
Dataset multispeaker dibuat dengan mensintesis data dengan model XTTS-V2 Coqui dan campuran suara dari dataset Tunisian_MSA.
Model dilatih dengan kehilangan MSE seperti yang dijelaskan dalam makalah. Saya juga melatih model menggunakan kehilangan permusuhan tambahan (ADV). Perbedaannya tidak besar, tapi saya pikir versi (ADV) sering terdengar sedikit lebih jelas. Anda dapat membandingkannya sendiri.
Menjalankan python download_files.py akan mengunduh semua bobot pretrained, sebagai alternatif:
Unduh bobot pretrained untuk model Tacotron2 (MSE | ADV).
Unduh bobot pretrained untuk model FastPitch (MSE | ADV).
Unduh Bobot Vocoder Hifi-Gan (tautan). Entah memasukkannya ke dalam pretrained/hifigan-asc-v1 atau mengedit baris berikut di configs/basic.yaml .
# vocoder
vocoder_state_path : pretrained/hifigan-asc-v1/hifigan-asc.pth
vocoder_config_path : pretrained/hifigan-asc-v1/config.jsonRepo ini mencakup model diakritisasi Shakkala dan Shakkelha.
Bobot dapat diunduh di sini. Ada juga repo dan paket terpisah.
-> Atau, unduh semua model dan masukkan konten file zip ke dalam folder pretrained .
torch torchaudio pyyaml
~ untuk pelatihan: librosa matplotlib tensorboard
~ Untuk aplikasi demo: fastapi "uvicorn[standard]"
Tacotron2 / FastPitch dari models.tacotron2 / models.fastpitch adalah pembungkus yang menyederhanakan inferensi teks-ke-mel. Model Tacotron2Wave / FastPitch2Wave mencakup vocoder HiFi-gan untuk inferensi teks-ke-speech langsung.
text = "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي."
wave = model . tts (
text_input = text , # input text
speed = 1 , # speaking speed
denoise = 0.005 , # HifiGAN denoiser strength
speaker_id = 0 , # speaker id
batch_size = 2 , # batch size for batched inference
vowelizer = None , # vowelizer model
pitch_mul = 1 , # pitch multiplier (for FastPitch)
pitch_add = 0 , # pitch offset (for FastPitch)
return_mel = False # return mel spectrogram?
) from models . tacotron2 import Tacotron2
model = Tacotron2 ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . fastpitch import FastPitch
model = FastPitch ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . tacotron2 import Tacotron2Wave
model = Tacotron2Wave ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ]) from models . fastpitch import FastPitch2Wave
model = FastPitch2Wave ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ])Secara default, huruf Arab dikonversi menggunakan transliterasi Buckwalter, yang juga dapat digunakan secara langsung.
wave = model . tts ( ">als~alAmu Ealaykum yA Sadiyqiy." )
wave_list = model . tts ([ "Sifr" , "wAHid" , "<i^nAn" , "^alA^ap" , ">arbaEap" , "xamsap" , "sit~ap" , "sabEap" , "^amAniyap" , "tisEap" , "Ea$arap" ]) text_unvoc = "اللغة العربية هي أكثر اللغات السامية تحدثا، وإحدى أكثر اللغات انتشارا في العالم"
wave_shakkala = model . tts ( text_unvoc , vowelizer = 'shakkala' )
wave_shakkelha = model . tts ( text_unvoc , vowelizer = 'shakkelha' )python inference.py
# default parameters:
python inference.py --list data/infer_text.txt --out_dir samples/results --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --batch_size 2 --denoise 0Untuk menguji model run:
python test.py
# default parameters:
python test.py --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --out_dir samples/test Repo ini menggunakan phonetiser Arab Nawar Halabi tetapi menyederhanakan hasil sehingga konteks yang berbeda diabaikan (lihat text/symbols.py ). Lebih lanjut, konsonan ganda direpresentasikan sebagai konsonan + penggandaan.
Model Tacotron2 kadang -kadang dapat berjuang untuk mengucapkan fonem terakhir dari suatu kalimat ketika berakhir dengan konsonan yang tidak disewa. Pengucapannya lebih dapat diandalkan jika seseorang menambahkan token pemisahan kata di ujungnya dan memotongnya menggunakan bobot Alignments (detail dalam models.networks ). Opsi ini diimplementasikan sebagai langkah postprocessing default yang dapat dinonaktifkan dengan mengatur postprocess_mel=False .
Sebelum pelatihan, file audio harus di -resampled. Model ini dilatih setelah preprocessing file menggunakan scripts/preprocess_audio.py .
Untuk melatih model dengan opsi yang ditentukan dalam file konfigurasi:
python train.py
# default parameters:
python train.py --config configs/nawar.yamlAplikasi Web menggunakan pustaka FASTAPI. Untuk menjalankan aplikasi, Anda membutuhkan paket berikut:
Fastapi: untuk API backend | Uvicorn: untuk melayani aplikasi
Instal dengan: pip install fastapi "uvicorn[standard]"
Jalankan dengan: python app.py
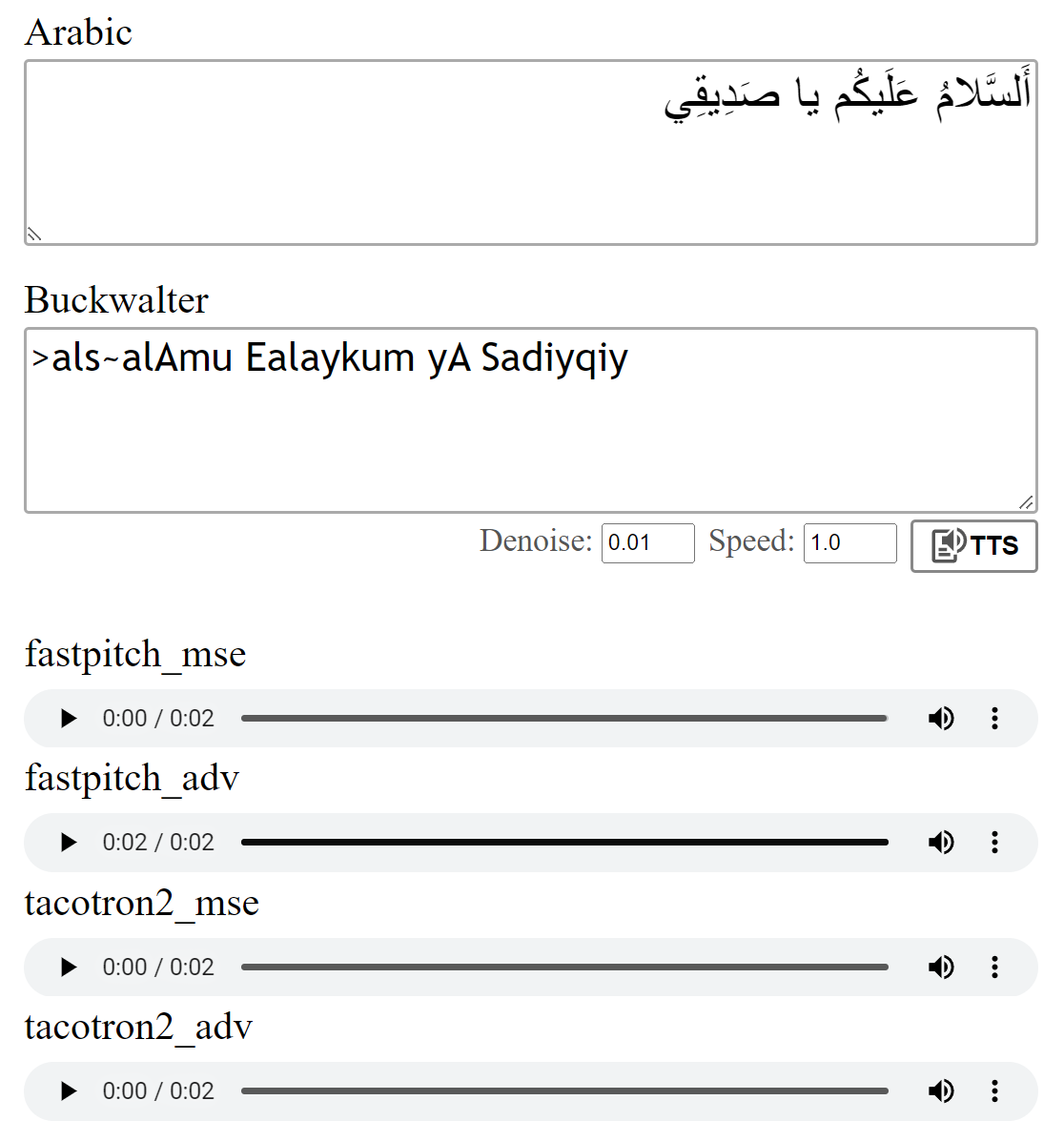
Pratinjau:
Saya merujuk pada implementasi TACOTRON2 NVIDIA untuk perincian tentang pelatihan model.
File FastPitch berasal dari contoh deeplearning -campo NVIDIA


