tts arabic pytorch
1.0.0
[Amostras 1] [Amostras 2] [Modelos Onnx] [App Flutter]
Modelos TTS (Tacotron2, Fastpitch), treinados no corpus de fala árabe de Nawar Halabi, incluindo o vocoder Hifi-Gan para a inferência direta do TTS.
Papéis:
Tacotron2 | Síntese de TTS natural por condicionamento de WaveNet nas previsões de espectrograma MEL (ARXIV)
FastPitch | FastPitch: Parallel Text-topeel com previsão de afinação (ARXIV)
HIFI-GAN | HIFI-GAN: Redes adversárias generativas para síntese de fala eficiente e de alta fidelidade (ARXIV)
Você pode ouvir algumas amostras de áudio aqui.
Os pesos multispicotores estão disponíveis para o modelo FastPitch. Atualmente, outra voz masculina e duas vozes femininas foram adicionadas. Amostras de áudio podem ser encontradas aqui. Baixe pesos aqui. Também existe uma versão ONNX para este modelo.
O conjunto de dados multispeaker foi criado sintetizando dados com o modelo XTTS-V2 da Coqui e uma mistura de vozes do conjunto de dados Tunisian_MSA.
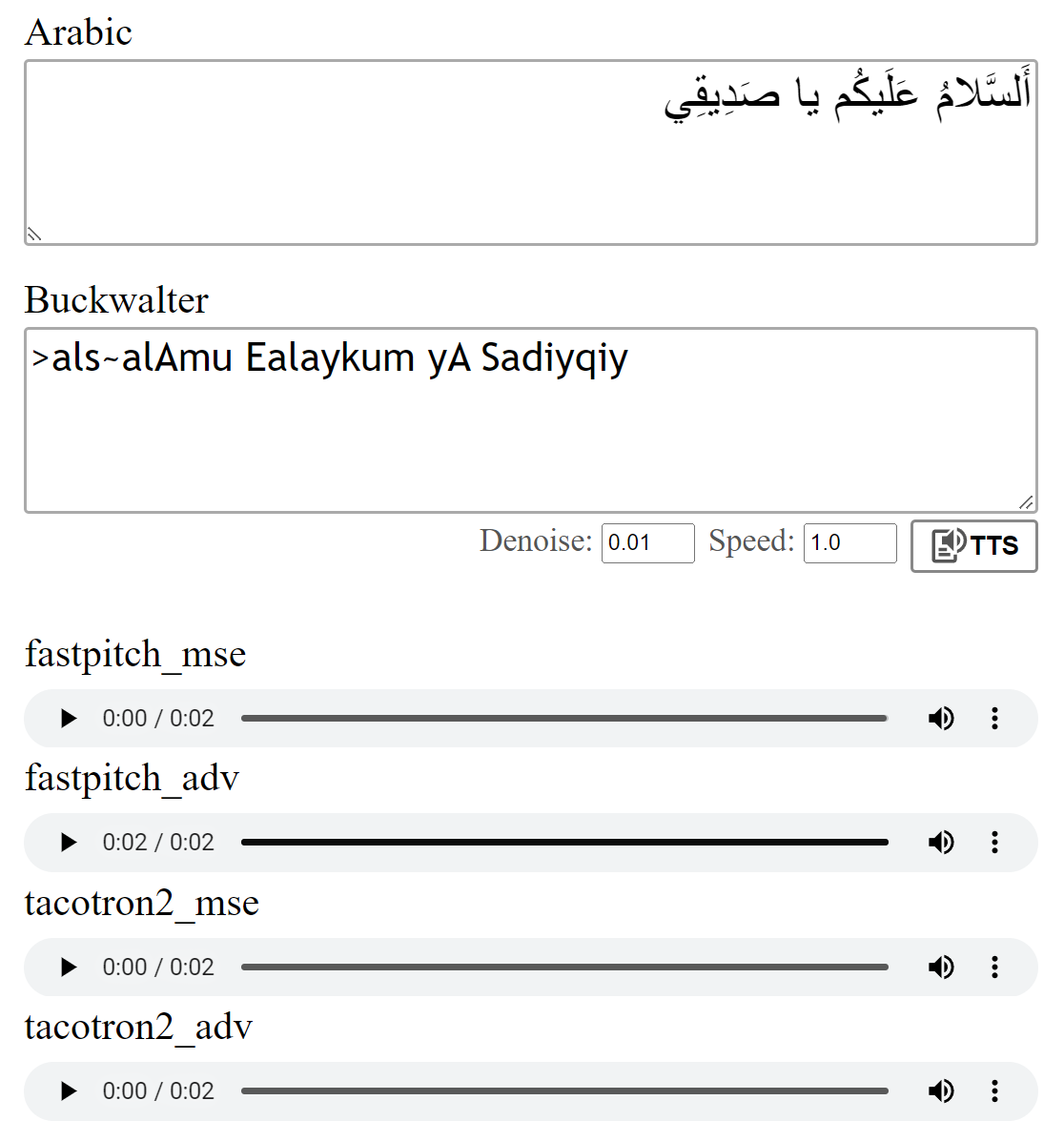
Os modelos foram treinados com a perda de MSE, conforme descrito nos jornais. Também treinei os modelos usando uma perda adversária adicional (ADV). A diferença não é grande, mas acho que a versão (adv) geralmente parece um pouco mais clara. Você pode compará -los você mesmo.
Executando python download_files.py baixará todos os pesos pré -terenciados, alternativamente:
Faça o download dos pesos pré -tenhados para o modelo Tacotron2 (MSE | Adv).
Faça o download dos pesos pré -tenhados para o modelo FastPitch (MSE | Adv).
Faça o download dos pesos do vocoder Hifi-Gan (link). Coloque-os em pretrained/hifigan-asc-v1 ou edite as seguintes linhas em configs/basic.yaml .
# vocoder
vocoder_state_path : pretrained/hifigan-asc-v1/hifigan-asc.pth
vocoder_config_path : pretrained/hifigan-asc-v1/config.jsonEste repositório inclui os modelos de diacritização Shakkala e Shakkelha.
Os pesos podem ser baixados aqui. Também existe um repositório e pacote separados.
-> Como alternativa, faça o download de todos os modelos e coloque o conteúdo do arquivo zip na pasta pretrained .
torch torchaudio pyyaml
~ Para treinamento: librosa matplotlib tensorboard
~ Para o aplicativo de demonstração: fastapi "uvicorn[standard]"
O Tacotron2 / FastPitch de models.tacotron2 / models.fastpitch são invólucros que simplificam a inferência de texto para mel. Os modelos Tacotron2Wave / FastPitch2Wave incluem o vocoder Hifi-Gan para inferência direta de texto em fala.
text = "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي."
wave = model . tts (
text_input = text , # input text
speed = 1 , # speaking speed
denoise = 0.005 , # HifiGAN denoiser strength
speaker_id = 0 , # speaker id
batch_size = 2 , # batch size for batched inference
vowelizer = None , # vowelizer model
pitch_mul = 1 , # pitch multiplier (for FastPitch)
pitch_add = 0 , # pitch offset (for FastPitch)
return_mel = False # return mel spectrogram?
) from models . tacotron2 import Tacotron2
model = Tacotron2 ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . fastpitch import FastPitch
model = FastPitch ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . tacotron2 import Tacotron2Wave
model = Tacotron2Wave ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ]) from models . fastpitch import FastPitch2Wave
model = FastPitch2Wave ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ])Por padrão, as letras árabes são convertidas usando a transliteração Buckwalter, que também pode ser usada diretamente.
wave = model . tts ( ">als~alAmu Ealaykum yA Sadiyqiy." )
wave_list = model . tts ([ "Sifr" , "wAHid" , "<i^nAn" , "^alA^ap" , ">arbaEap" , "xamsap" , "sit~ap" , "sabEap" , "^amAniyap" , "tisEap" , "Ea$arap" ]) text_unvoc = "اللغة العربية هي أكثر اللغات السامية تحدثا، وإحدى أكثر اللغات انتشارا في العالم"
wave_shakkala = model . tts ( text_unvoc , vowelizer = 'shakkala' )
wave_shakkelha = model . tts ( text_unvoc , vowelizer = 'shakkelha' )python inference.py
# default parameters:
python inference.py --list data/infer_text.txt --out_dir samples/results --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --batch_size 2 --denoise 0Para testar a execução do modelo:
python test.py
# default parameters:
python test.py --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --out_dir samples/test Este repo usa o phonetizador árabe de Nawar Halabi, mas simplifica o resultado de modo que diferentes contextos sejam ignorados (consulte text/symbols.py ). Além disso, uma consoante duplicada é representada como consoante + duplicação.
O modelo Tacotron2 às vezes pode lutar para pronunciar o último fonema de uma frase quando termina em uma consoante não vocalizada. A pronúncia é mais confiável se alguém anexar um token de separador de palavras no final e o interromper usando os pesos dos alinhamentos (detalhes em models.networks ). Esta opção é implementada como uma etapa de pós -processamento padrão que pode ser desativada, definindo postprocess_mel=False .
Antes do treinamento, os arquivos de áudio devem ser reamostrados. O modelo foi treinado após o pré -processamento dos arquivos usando scripts/preprocess_audio.py .
Para treinar o modelo com opções especificadas no arquivo de configuração executado:
python train.py
# default parameters:
python train.py --config configs/nawar.yamlO aplicativo da web usa a biblioteca FASTAPI. Para executar o aplicativo, você precisa dos seguintes pacotes:
FASTAPI: Para a API de back -end | Uvicorn: para servir o aplicativo
Instale com: pip install fastapi "uvicorn[standard]"
Corra com: python app.py
Visualização:
Referi -me à implementação do Tacotron2 da NVIDIA para obter detalhes sobre o treinamento do modelo.
Os arquivos FastPitch decorrem dos exemplos de popa de NVIDIA


