tts arabic pytorch
1.0.0
[Muestras 1] [Muestras 2] [Modelos ONNX] [Aplicación Flutter]
Los modelos TTS (Tacotron2, Fastpitch), entrenados en el Corpus del Discurso Árabe de Nawar Halabi, incluido el Vocoder Hifi-Gan para la inferencia directa de TTS.
Papeles:
Tacotron2 | Síntesis de TTS natural mediante acondicionamiento de wavenet en predicciones de espectrograma MEL (ARXIV)
Fastpitch | FastPitch: texto paralelo a voz con predicción de tono (ARXIV)
Hifi-Gan | Hifi-Gan: redes adversas generativas para la síntesis de habla eficiente y de alta fidelidad (ARXIV)
Puedes escuchar algunas muestras de audio aquí.
Los pesos de multiespeaker están disponibles para el modelo FastPitch. Actualmente, se han agregado otra voz masculina y dos voces femeninas. Las muestras de audio se pueden encontrar aquí. Descargue pesas aquí. También existe una versión ONNX para este modelo.
El conjunto de datos MultIspeaker se creó sintetizando datos con el modelo XTTS-V2 de Coqui y una combinación de voces del conjunto de datos Tunisian_MSA.
Los modelos fueron entrenados con la pérdida de MSE como se describe en los documentos. También entrené los modelos utilizando una pérdida adversaria adicional (ADV). La diferencia no es grande, pero creo que la versión (adv) a menudo suena un poco más clara. Puedes compararlos tú mismo.
Ejecutar python download_files.py descargará todos los pesos previos a la aparición, alternativamente:
Descargue los pesos previos a la aparición para el modelo Tacotron2 (MSE | ADV).
Descargue los pesos previos a la aparición para el modelo FastPitch (MSE | ADV).
Descargue los pesos Hifi-Gan Vocoder (enlace). Póngalos en pretrained/hifigan-asc-v1 o edite las siguientes líneas en configs/basic.yaml .
# vocoder
vocoder_state_path : pretrained/hifigan-asc-v1/hifigan-asc.pth
vocoder_config_path : pretrained/hifigan-asc-v1/config.jsonEste repositorio incluye los modelos de diacritización Shakkala y Shakkelha.
Los pesos se pueden descargar aquí. También existe un repositorio y un paquete separados.
-> Alternativamente, descargue todos los modelos y coloque el contenido del archivo ZIP en la carpeta pretrained .
torch torchaudio pyyaml
~ Para el entrenamiento: librosa matplotlib tensorboard
~ Para la aplicación de demostración: fastapi "uvicorn[standard]"
El Tacotron2 / FastPitch de models.tacotron2 / models.fastpitch son envoltorios que simplifican la inferencia de texto a mezcla. Los modelos Tacotron2Wave / FastPitch2Wave incluyen el Vocoder Hifi-Gan para la inferencia directa de texto a voz.
text = "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي."
wave = model . tts (
text_input = text , # input text
speed = 1 , # speaking speed
denoise = 0.005 , # HifiGAN denoiser strength
speaker_id = 0 , # speaker id
batch_size = 2 , # batch size for batched inference
vowelizer = None , # vowelizer model
pitch_mul = 1 , # pitch multiplier (for FastPitch)
pitch_add = 0 , # pitch offset (for FastPitch)
return_mel = False # return mel spectrogram?
) from models . tacotron2 import Tacotron2
model = Tacotron2 ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . fastpitch import FastPitch
model = FastPitch ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . tacotron2 import Tacotron2Wave
model = Tacotron2Wave ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ]) from models . fastpitch import FastPitch2Wave
model = FastPitch2Wave ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ])Por defecto, las letras árabes se convierten utilizando la transliteración de Buckwalter, que también se puede usar directamente.
wave = model . tts ( ">als~alAmu Ealaykum yA Sadiyqiy." )
wave_list = model . tts ([ "Sifr" , "wAHid" , "<i^nAn" , "^alA^ap" , ">arbaEap" , "xamsap" , "sit~ap" , "sabEap" , "^amAniyap" , "tisEap" , "Ea$arap" ]) text_unvoc = "اللغة العربية هي أكثر اللغات السامية تحدثا، وإحدى أكثر اللغات انتشارا في العالم"
wave_shakkala = model . tts ( text_unvoc , vowelizer = 'shakkala' )
wave_shakkelha = model . tts ( text_unvoc , vowelizer = 'shakkelha' )python inference.py
# default parameters:
python inference.py --list data/infer_text.txt --out_dir samples/results --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --batch_size 2 --denoise 0Para probar la ejecución del modelo:
python test.py
# default parameters:
python test.py --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --out_dir samples/test Este repositorio utiliza el fonetizador árabe de Nawar Halabi, pero simplifica el resultado de tal manera que se ignoran diferentes contextos (ver text/symbols.py ). Además, una consonante duplicada se representa como consonante + duplicación de duplicación.
El modelo Tacotron2 a veces puede luchar para pronunciar el último fonema de una oración cuando termina en una consonante uncalizada. La pronunciación es más confiable si uno agrega un token de separador de palabras al final y lo corta utilizando los pesos de las alineaciones (detalles en models.networks ). Esta opción se implementa como un paso de postprocesamiento predeterminado que se puede deshabilitar configurando postprocess_mel=False .
Antes de la capacitación, los archivos de audio deben volver a muestrear. El modelo fue entrenado después de preprocesar los archivos usando scripts/preprocess_audio.py .
Para entrenar el modelo con opciones especificadas en el archivo de configuración ejecutado:
python train.py
# default parameters:
python train.py --config configs/nawar.yamlLa aplicación web utiliza la biblioteca Fastapi. Para ejecutar la aplicación necesita los siguientes paquetes:
Fastapi: para la API de backend | Uvicorn: para servir la aplicación
Instale con: pip install fastapi "uvicorn[standard]"
Ejecutar con: python app.py
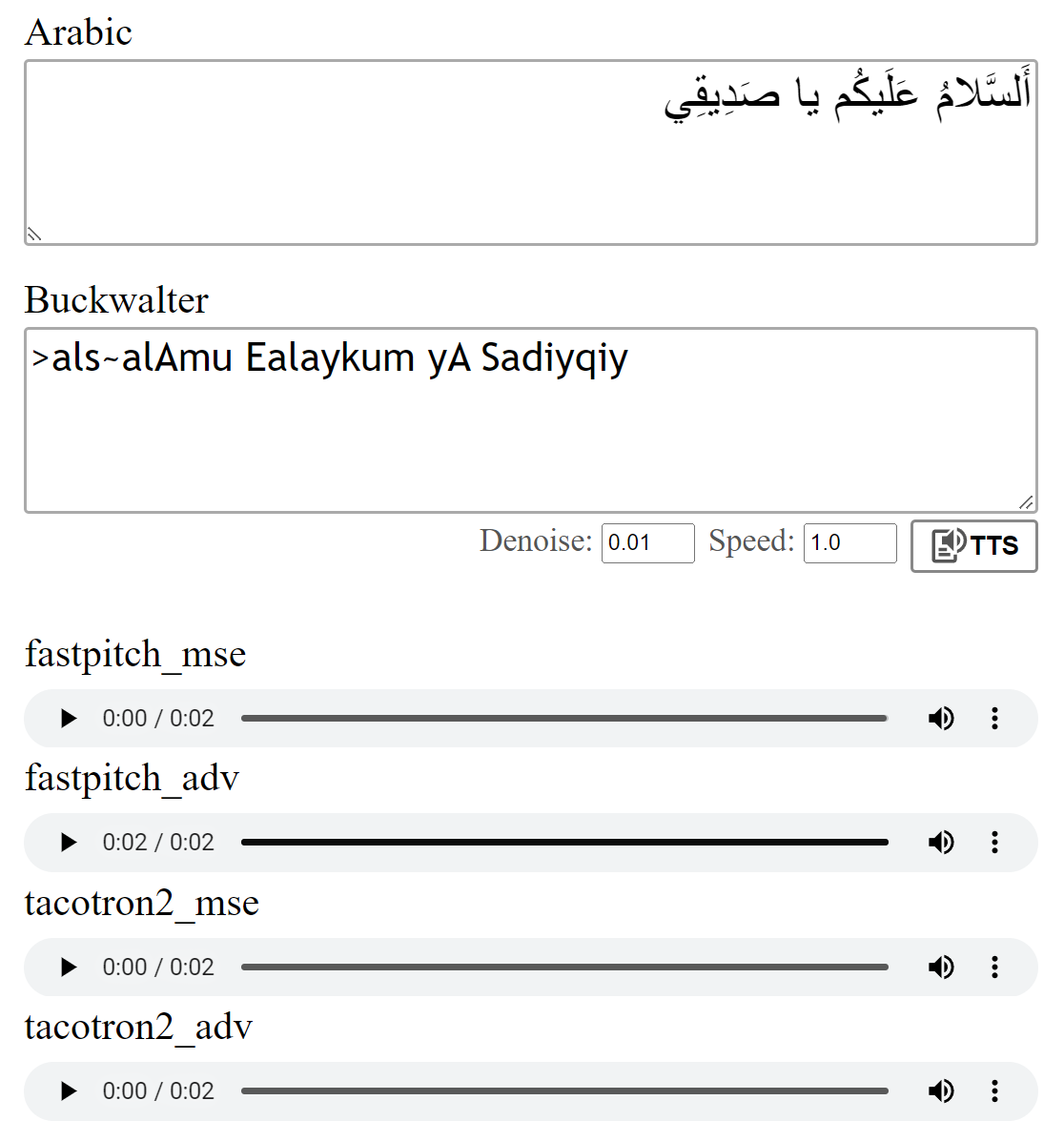
Avance:
Me referí a la implementación de Tacotron2 de NVIDIA para obtener detalles sobre la capacitación del modelo.
Los archivos de FastPitch provienen de DeeplearningExmples de NVIDIA


