tts arabic pytorch
1.0.0
[ตัวอย่างที่ 1] [ตัวอย่าง 2] [onnx models] [แอปพลิเคชัน]
โมเดล TTS (Tacotron2, Fastpitch) ได้รับการฝึกฝนเกี่ยวกับคลังคำพูดภาษาอาหรับของ Nawar Halabi รวมถึง Hifi-Gan Vocoder สำหรับการอนุมาน TTS โดยตรง
เอกสาร:
Tacotron2 | การสังเคราะห์ TTS ธรรมชาติโดยการปรับสภาพ wavenet บนการทำนาย MEL spectrogram (arxiv)
Fastpitch | fastpitch: ข้อความแบบขนานกับคำพูดพร้อมการทำนายระดับเสียง (arxiv)
Hifi-Gan | HIFI-GAN: เครือข่ายฝ่ายตรงข้ามแบบกำเนิดสำหรับการสังเคราะห์คำพูดที่มีประสิทธิภาพและมีความซื่อสัตย์สูง (ARXIV)
คุณสามารถฟังตัวอย่างเสียงได้ที่นี่
มีน้ำหนักหลายครั้งสำหรับรุ่น Fastpitch ปัจจุบันมีการเพิ่มเสียงชายอีกครั้งและเสียงหญิงสองคน ตัวอย่างเสียงสามารถพบได้ที่นี่ ดาวน์โหลดน้ำหนักที่นี่ นอกจากนี้ยังมีรุ่น ONNX สำหรับรุ่นนี้
ชุดข้อมูล Multispeaker ถูกสร้างขึ้นโดยการสังเคราะห์ข้อมูลด้วยรุ่น XTTS-V2 ของ Coqui และการผสมผสานของเสียงจากชุดข้อมูล Tunisian_MSA
แบบจำลองได้รับการฝึกฝนด้วยการสูญเสีย MSE ตามที่อธิบายไว้ในเอกสาร ฉันยังฝึกอบรมแบบจำลองโดยใช้การสูญเสียที่เป็นปฏิปักษ์เพิ่มเติม (ADV) ความแตกต่างไม่ใหญ่ แต่ฉันคิดว่าเวอร์ชัน (adv) มักจะฟังดูชัดเจนขึ้นเล็กน้อย คุณสามารถเปรียบเทียบได้ด้วยตัวเอง
Running python download_files.py จะดาวน์โหลดน้ำหนักที่ได้รับการฝึกฝนทั้งหมดหรือ
ดาวน์โหลดน้ำหนักที่ได้รับการฝึกฝนสำหรับรุ่น Tacotron2 (MSE | ADV)
ดาวน์โหลดน้ำหนักที่ได้รับการฝึกฝนสำหรับรุ่น Fastpitch (MSE | ADV)
ดาวน์โหลด Hifi-Gan Vocoder Weights (ลิงก์) ไม่ว่าจะเป็นพวกเขาลงใน pretrained/hifigan-asc-v1 หรือแก้ไขบรรทัดต่อไปนี้ใน configs/basic.yaml
# vocoder
vocoder_state_path : pretrained/hifigan-asc-v1/hifigan-asc.pth
vocoder_config_path : pretrained/hifigan-asc-v1/config.jsonrepo นี้รวมถึงโมเดล diacritization Shakkala และ Shakkelha
น้ำหนักสามารถดาวน์โหลดได้ที่นี่ นอกจากนี้ยังมี repo และแพ็คเกจแยกต่างหาก
-> หรือดาวน์โหลดทุกรุ่นและใส่เนื้อหาของไฟล์ ZIP ลงในโฟลเดอร์ pretrained
torch torchaudio pyyaml
~ สำหรับการฝึกอบรม: librosa matplotlib tensorboard
~ สำหรับแอพสาธิต: fastapi "uvicorn[standard]"
Tacotron2 / FastPitch จาก models.tacotron2 / models.fastpitch เป็น wrappers ที่ทำให้การอนุมานแบบข้อความกับเมลง่ายขึ้น โมเดล Tacotron2Wave / FastPitch2Wave รวมถึง HIFI-GAN Vocoder สำหรับการอนุมานแบบข้อความโดยตรงกับการพูด
text = "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي."
wave = model . tts (
text_input = text , # input text
speed = 1 , # speaking speed
denoise = 0.005 , # HifiGAN denoiser strength
speaker_id = 0 , # speaker id
batch_size = 2 , # batch size for batched inference
vowelizer = None , # vowelizer model
pitch_mul = 1 , # pitch multiplier (for FastPitch)
pitch_add = 0 , # pitch offset (for FastPitch)
return_mel = False # return mel spectrogram?
) from models . tacotron2 import Tacotron2
model = Tacotron2 ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . fastpitch import FastPitch
model = FastPitch ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . tacotron2 import Tacotron2Wave
model = Tacotron2Wave ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ]) from models . fastpitch import FastPitch2Wave
model = FastPitch2Wave ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ])โดยค่าเริ่มต้นตัวอักษรภาษาอาหรับจะถูกแปลงโดยใช้การทดสอบ Buckwalter ซึ่งสามารถใช้โดยตรง
wave = model . tts ( ">als~alAmu Ealaykum yA Sadiyqiy." )
wave_list = model . tts ([ "Sifr" , "wAHid" , "<i^nAn" , "^alA^ap" , ">arbaEap" , "xamsap" , "sit~ap" , "sabEap" , "^amAniyap" , "tisEap" , "Ea$arap" ]) text_unvoc = "اللغة العربية هي أكثر اللغات السامية تحدثا، وإحدى أكثر اللغات انتشارا في العالم"
wave_shakkala = model . tts ( text_unvoc , vowelizer = 'shakkala' )
wave_shakkelha = model . tts ( text_unvoc , vowelizer = 'shakkelha' )python inference.py
# default parameters:
python inference.py --list data/infer_text.txt --out_dir samples/results --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --batch_size 2 --denoise 0เพื่อทดสอบการรันโมเดล:
python test.py
# default parameters:
python test.py --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --out_dir samples/test repo นี้ใช้ภาษาอาหรับ-พงศาวดารของ Nawar Halabi แต่ลดความซับซ้อนของผลลัพธ์เช่นบริบทที่แตกต่างกันถูกละเว้น (ดู text/symbols.py ) นอกจากนี้พยัญชนะสองเท่าจะแสดงเป็นพยัญชนะ + สองเท่า
แบบจำลอง Tacotron2 บางครั้งสามารถดิ้นรนเพื่อออกเสียงเสียงสุดท้ายของประโยคเมื่อมันจบลงในพยัญชนะที่ไม่ได้รับการรับรอง การออกเสียงมีความน่าเชื่อถือมากขึ้นหากมีการผนวกโทเค็นคำแยกคำในตอนท้ายและตัดออกโดยใช้น้ำหนักการจัดตำแหน่ง (รายละเอียดใน models.networks ) ตัวเลือกนี้ถูกนำมาใช้เป็นขั้นตอนการประมวลผลหลังเริ่มต้นที่สามารถปิดใช้งานได้โดยการตั้งค่า postprocess_mel=False
ก่อนการฝึกอบรมไฟล์เสียงจะต้องมีการสุ่มตัวอย่างอีกครั้ง โมเดลได้รับการฝึกอบรมหลังจากประมวลผลไฟล์ล่วงหน้าโดยใช้ scripts/preprocess_audio.py
ในการฝึกอบรมโมเดลด้วยตัวเลือกที่ระบุในไฟล์กำหนดค่า:
python train.py
# default parameters:
python train.py --config configs/nawar.yamlเว็บแอปใช้ไลบรารี fastapi ในการเรียกใช้แอพที่คุณต้องการแพ็คเกจต่อไปนี้:
fastapi: สำหรับแบ็กเอนด์ API | Uvicorn: สำหรับให้บริการแอป
ติดตั้งด้วย: pip install fastapi "uvicorn[standard]"
รันด้วย: python app.py
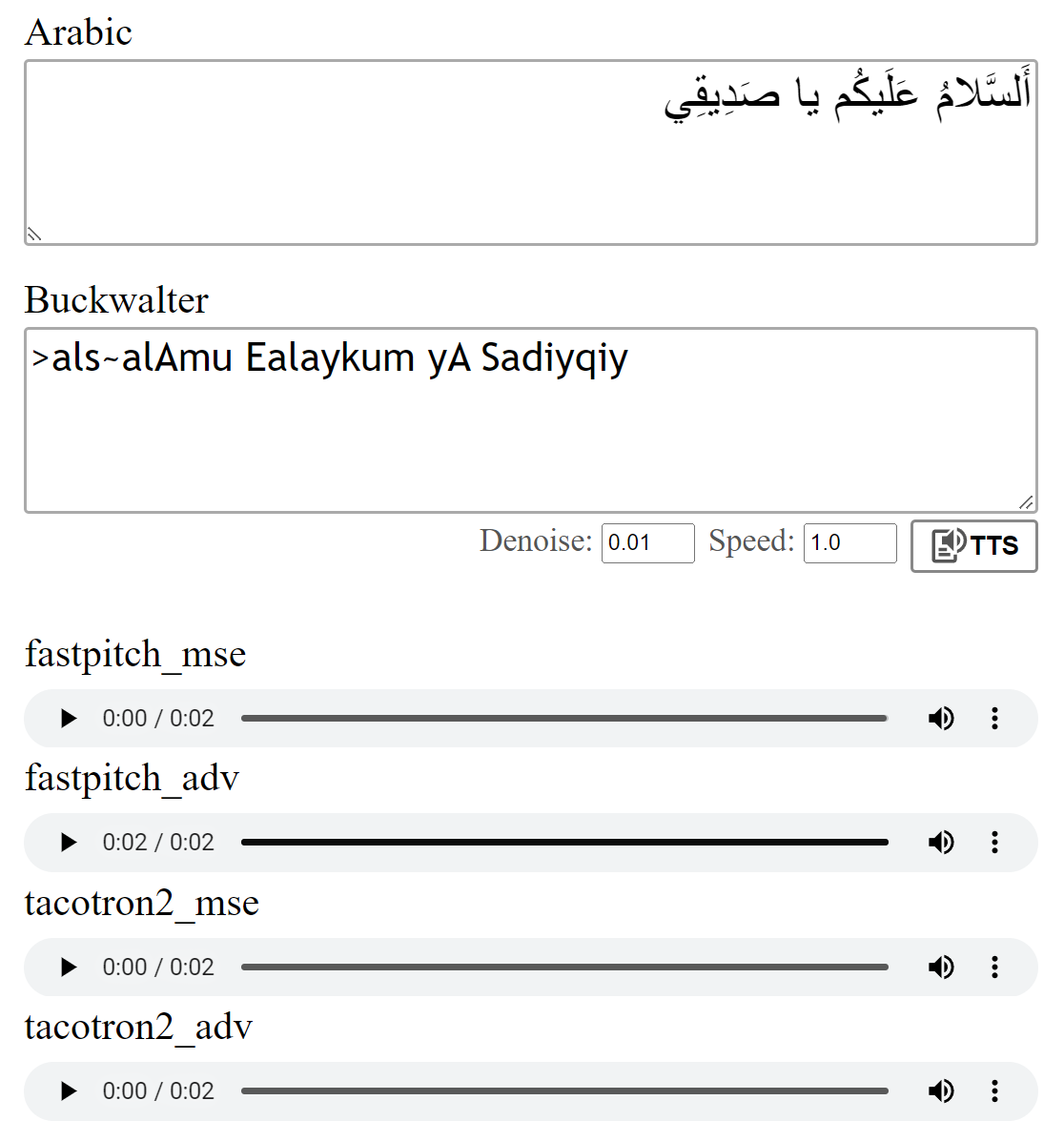
ดูตัวอย่าง:
ฉันอ้างถึงการใช้งาน Tacotron2 ของ Nvidia สำหรับรายละเอียดเกี่ยวกับการฝึกอบรมแบบจำลอง
ไฟล์ fastpitch เกิดจาก deeplearningexamples ของ Nvidia


