tts arabic pytorch
1.0.0
[Proben 1] [Proben 2] [ONNX -Modelle] [Flutter -App]
TTS-Modelle (Tacotron2, Fastpitch), trainiert auf Nawar Halabis arabischem Sprachkorpus, einschließlich des Hifi-Gan-Vokoders für direkte TTS-Inferenz.
Papiere:
Tacotron2 | Natürliche TTS -Synthese durch Konditionierung von Wellenet auf Mel -Spektrogramm -Vorhersagen (ARXIV)
Fastpitch | Fastpitch: Parallel Text-to-Speech mit Pitch Prediction (ARXIV)
Hifi-gan | Hifi-Gan: Generative kontroverse Netzwerke für die effiziente und hohe Treue-Sprachsynthese (ARXIV)
Sie können hier einige Audio -Samples anhören.
Multispeaker -Gewichte sind für das FastPitch -Modell verfügbar. Derzeit wurden eine weitere männliche Stimme und zwei weibliche Stimmen hinzugefügt. Audio -Samples finden Sie hier. Laden Sie hier Gewichte herunter. Es gibt auch eine OnNX -Version für dieses Modell.
Der Multispeaker-Datensatz wurde erstellt, indem Daten mit dem XTTS-V2-Modell von Coqui und einer Mischung aus Stimmen aus dem Tunesian_MSA-Datensatz synthetisieren.
Die Modelle wurden mit dem MSE -Verlust ausgebildet, wie in den Papieren beschrieben. Ich habe die Modelle auch mit einem zusätzlichen kontroversen Verlust (ADV) geschult. Der Unterschied ist nicht groß, aber ich denke, dass die (adv) Version oft etwas klarer klingt. Sie können sie selbst vergleichen.
Ausführen python download_files.py wird alternativ alle vorgezogenen Gewichte herunterladen:
Laden Sie die vorgenannten Gewichte für das Tacotron2 -Modell (MSE | adv) herunter.
Laden Sie die vorgezogenen Gewichte für das FastPitch -Modell (MSE | adv) herunter.
Laden Sie die Hifi-Gan-Vocoder-Gewichte (Link) herunter. Stecken Sie sie entweder in ein pretrained/hifigan-asc-v1 oder bearbeiten Sie die folgenden Zeilen in configs/basic.yaml .
# vocoder
vocoder_state_path : pretrained/hifigan-asc-v1/hifigan-asc.pth
vocoder_config_path : pretrained/hifigan-asc-v1/config.jsonDieses Repo enthält die Diakritisierungsmodelle Shakkala und Shakkelha.
Die Gewichte können hier heruntergeladen werden. Es gibt auch ein separates Repo und ein separates Paket.
-> Alternativ Alternativ herunterladen, alle Modelle herunterladen und den Inhalt der ZIP -Datei in den pretrained Ordner einlegen.
torch torchaudio pyyaml
~ Für das Training: librosa matplotlib tensorboard
~ Für die Demo -App: fastapi "uvicorn[standard]"
Der Tacotron2 / FastPitch von models.tacotron2 / models.fastpitch sind Wrapper, die Text-zu-Mel-Inferenz vereinfachen. Die Tacotron2Wave / FastPitch2Wave -Modelle enthält den Hifi-Gan-Vokoder für direkte Text-zu-Sprache-Inferenz.
text = "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي."
wave = model . tts (
text_input = text , # input text
speed = 1 , # speaking speed
denoise = 0.005 , # HifiGAN denoiser strength
speaker_id = 0 , # speaker id
batch_size = 2 , # batch size for batched inference
vowelizer = None , # vowelizer model
pitch_mul = 1 , # pitch multiplier (for FastPitch)
pitch_add = 0 , # pitch offset (for FastPitch)
return_mel = False # return mel spectrogram?
) from models . tacotron2 import Tacotron2
model = Tacotron2 ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . fastpitch import FastPitch
model = FastPitch ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
mel_spec = model . ttmel ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." ) from models . tacotron2 import Tacotron2Wave
model = Tacotron2Wave ( 'pretrained/tacotron2_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ]) from models . fastpitch import FastPitch2Wave
model = FastPitch2Wave ( 'pretrained/fastpitch_ar_adv.pth' )
model = model . cuda ()
wave = model . tts ( "اَلسَّلامُ عَلَيكُم يَا صَدِيقِي." )
wave_list = model . tts ([ "صِفر" , "واحِد" , "إِثنان" , "ثَلاثَة" , "أَربَعَة" , "خَمسَة" , "سِتَّة" , "سَبعَة" , "ثَمانِيَة" , "تِسعَة" , "عَشَرَة" ])Standardmäßig werden arabische Buchstaben unter Verwendung der Buckwalter -Transliteration umgewandelt, die auch direkt verwendet werden kann.
wave = model . tts ( ">als~alAmu Ealaykum yA Sadiyqiy." )
wave_list = model . tts ([ "Sifr" , "wAHid" , "<i^nAn" , "^alA^ap" , ">arbaEap" , "xamsap" , "sit~ap" , "sabEap" , "^amAniyap" , "tisEap" , "Ea$arap" ]) text_unvoc = "اللغة العربية هي أكثر اللغات السامية تحدثا، وإحدى أكثر اللغات انتشارا في العالم"
wave_shakkala = model . tts ( text_unvoc , vowelizer = 'shakkala' )
wave_shakkelha = model . tts ( text_unvoc , vowelizer = 'shakkelha' )python inference.py
# default parameters:
python inference.py --list data/infer_text.txt --out_dir samples/results --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --batch_size 2 --denoise 0Um den Modelllauf zu testen:
python test.py
# default parameters:
python test.py --model fastpitch --checkpoint pretrained/fastpitch_ar_adv.pth --out_dir samples/test Dieses Repo verwendet Nawar Halabis arabisch-phonetriser, vereinfacht das Ergebnis so, dass verschiedene Kontexte ignoriert werden (siehe text/symbols.py ). Darüber hinaus wird ein doppeltes Konsonant als Konsonant + Verdoppelung dargestellt.
Das Tacotron2 -Modell kann manchmal Schwierigkeiten haben, das letzte Phonem eines Satzes auszusprechen, wenn es in einem unvokalisierten Konsonanten endet. Die Aussprache ist zuverlässiger, wenn man am Ende ein Word-Separator-Token anfährt und es mit den Ausrichtungsgewichten (Details in models.networks ) abschneidet. Diese Option wird als Standard -Nachbearbeitungsschritt implementiert, der durch Einstellen postprocess_mel=False deaktiviert werden kann.
Vor dem Training müssen die Audiodateien neu abgetastet werden. Das Modell wurde nach der Vorverarbeitung der Dateien mithilfe von scripts/preprocess_audio.py trainiert.
So trainieren Sie das Modell mit den in der Konfigurationsdateilauf angegebenen Optionen:
python train.py
# default parameters:
python train.py --config configs/nawar.yamlDie Web -App verwendet die Fastapi -Bibliothek. Um die App auszuführen, benötigen Sie die folgenden Pakete:
Fastapi: Für die Backend -API | Uvicorn: zum Servieren der App
Installieren mit: pip install fastapi "uvicorn[standard]"
Führen Sie mit: python app.py aus
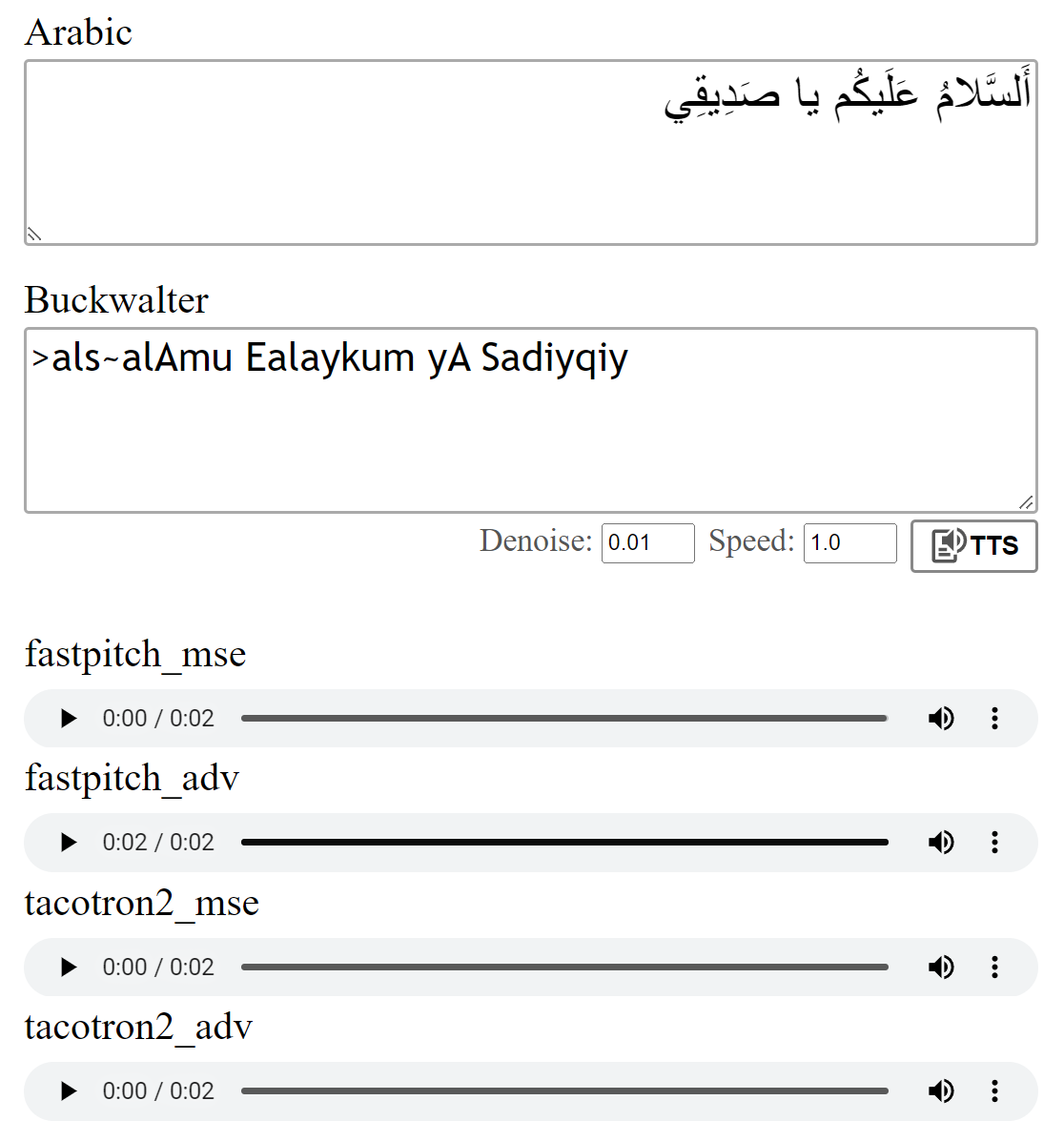
Vorschau:
Ich habe auf die Tacotron2 -Implementierung von Nvidia verwiesen, um Einzelheiten zum Modelltraining zu erhalten.
Die Fastpitch -Dateien stammen aus den DeepLearning -Examples von Nvidia


