dctts2
1.0.0
這是“基於深度卷積網絡的有效訓練的文本到語音系統的實施” https://arxiv.org/abs/1710.08969
該代碼基於以下實現
模型火車“ Text2Mel”和“ SSRN”分別通過trainmel.py&trainmag.py分別下載您需要下載https://keithito.com/lj-speech-dataset/可用的ljspeech數據集
您可以收聽音頻樣本
可以在此處下載預訓練的模型
首先,您必須準備數據集。如果要使用LJSpeech數據集,則可以使用以下命令。
$ wget http://data.keithito.com/data/speech/LJSpeech-1.0.tar.bz2
$ tar xvf LJSpeech-1.0.tar.bz2
$ python prepro.py
$ python trainmel.py
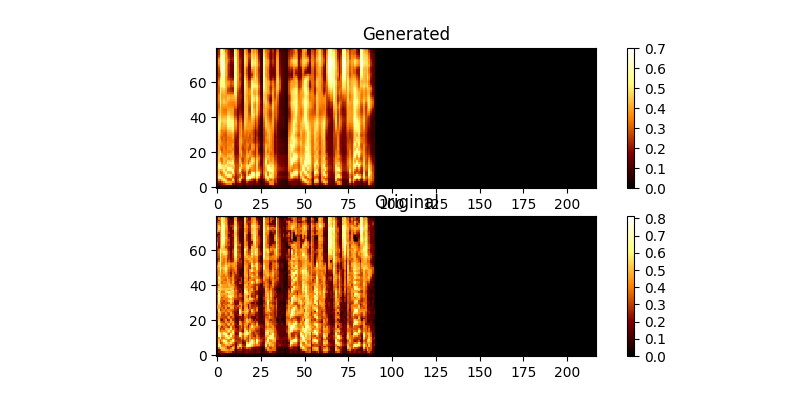
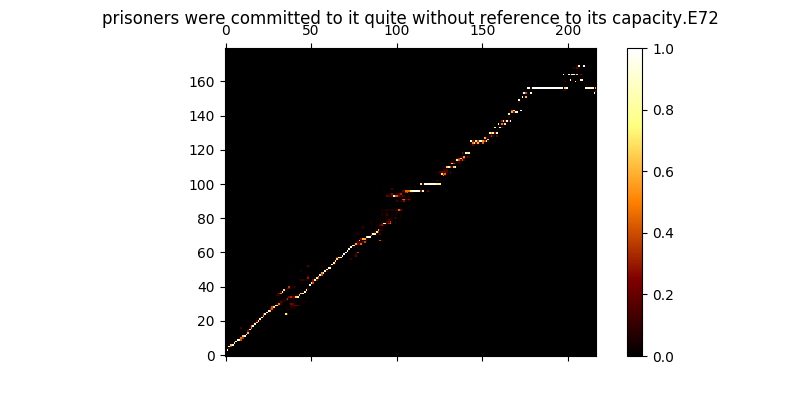
在培訓期間,您可以查看輸出(默認情況下每200個小匹配),它將批次中的前兩個示例轉儲到mel0.png&mel1.png中,還可以通過a0.png&a1.png查看學習的注意力
$ python trainmag.py
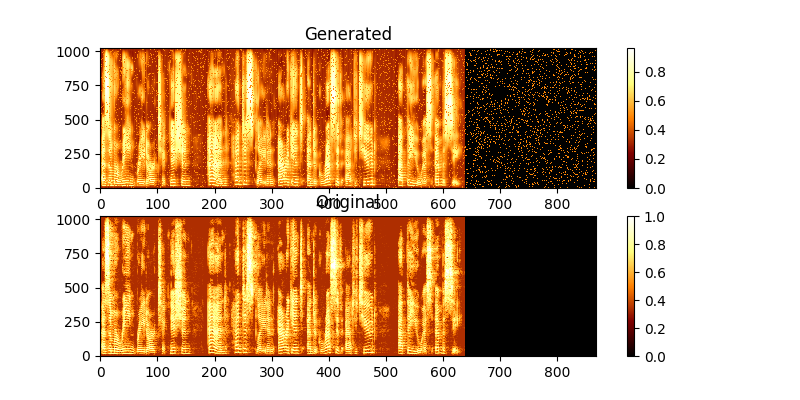
在訓練過程中,您可以通過mag0.png&mag1.png查看輸出,該輸出將學習的頻譜圖與Groung真相進行了比較。
綜合新的寄件使用:
$ python synth.py --text "sentance to synthesize" --file output.wav
您可以通過運行來運行演示Web服務器進行TTS
$ python server.py
這使用燒瓶框架運行演示


