dctts2
1.0.0
これは、「注意を払った深い畳み込みネットワークに基づいた「効率的にトレーニング可能なテキストからスピーチへ」システムの実装です」https://arxiv.org/abs/1710.08969
コードは、次の実装に基づいています
モデルトレーニング「text2mel」& "ssrn"をそれぞれTrainmel.py&trainmag.pyを介して別々にトレーニングします。
オーディオサンプルを聴くことができます
事前に訓練されたモデルはここからダウンロードできます
まず、データセットを準備する必要があります。 ljspeechデータセットを使用する場合は、次のコマンドを使用できます。
$ wget http://data.keithito.com/data/speech/LJSpeech-1.0.tar.bz2
$ tar xvf LJSpeech-1.0.tar.bz2
$ python prepro.py
$ python trainmel.py
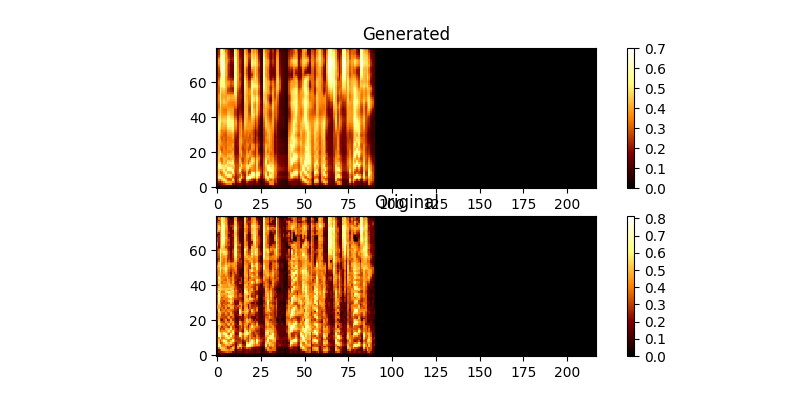
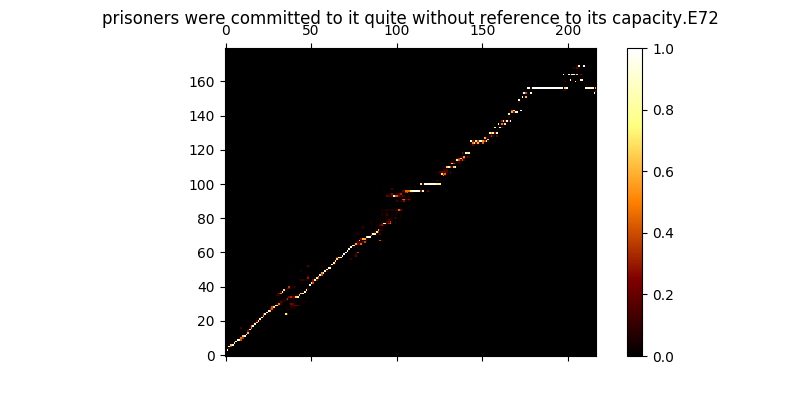
トレーニング中に、出力を確認できます(デフォルトで200ミニバッチごとに)。バッチの最初の2つの例をmel0.png&mel1.pngにダンプします。
$ python trainmag.py
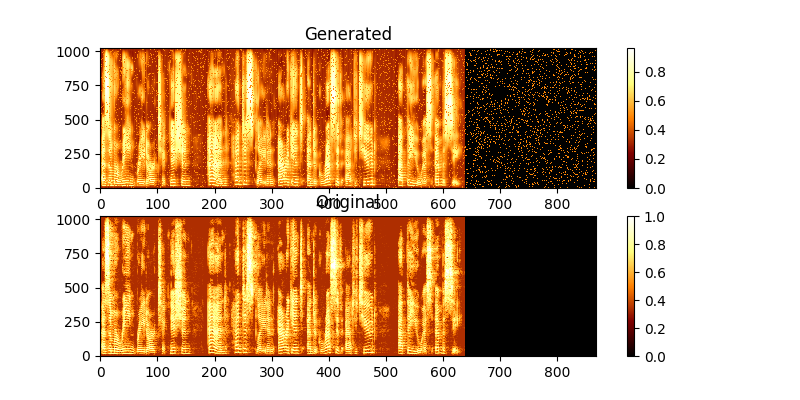
トレーニング中に、MAG0.png&mag1.pngを介した出力を表示できます。
新しいセンタンスの使用を統合するには:
$ python synth.py --text "sentance to synthesize" --file output.wav
実行してデモWebサーバーを実行してTTSを実行できます
$ python server.py
これにより、フラスコフレームワークを使用してデモを実行します


