dctts2
1.0.0
Ceci est une mise en œuvre du document "Système de texte à dispection efficacement formable basé sur des réseaux convolutionnels profonds avec une attention guidée" https://arxiv.org/abs/1710.08969
Le code est basé sur les implémentations suivantes
Le modèle forme "text2mel" & "ssrn" séparément via TrainMel.py & Trainmag.py respectivement, vous devez télécharger l'ensemble de données LJSpeech disponible sur https://keithito.com/lj-peech-dataset/
Vous pouvez écouter des échantillons audio
Les modèles pré-formés peuvent être téléchargés ici
Tout d'abord, vous devez préparer un ensemble de données. Si vous souhaitez utiliser l'ensemble de données LJSPEECH, vous pouvez utiliser les commandes suivantes.
$ wget http://data.keithito.com/data/speech/LJSpeech-1.0.tar.bz2
$ tar xvf LJSpeech-1.0.tar.bz2
$ python prepro.py
$ python trainmel.py
Pendant la formation, vous pouvez consulter la sortie (par défaut tous les 200 minibatchs), il vide les deux premiers exemples du lot dans Mel0.png & mel1.png et consultez l'attention du savant via a0.png & a1.png
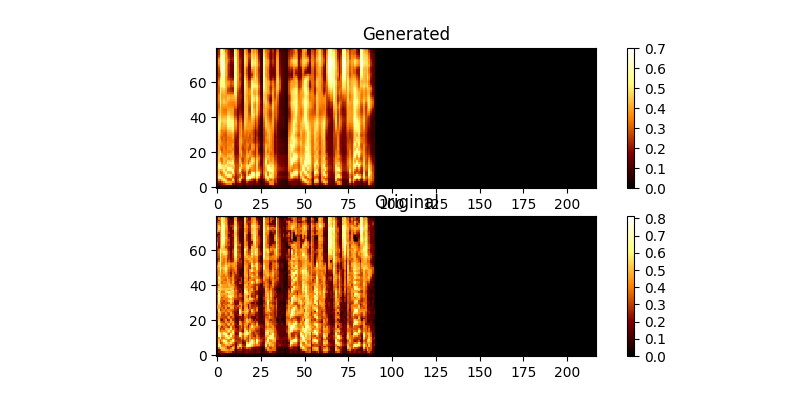
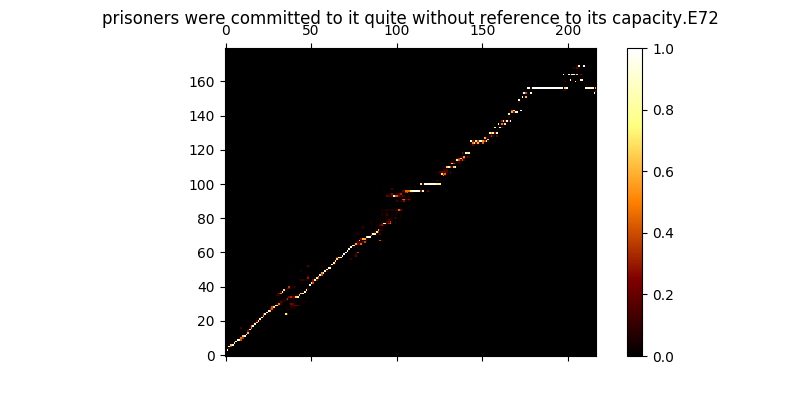
$ python trainmag.py
Pendant l'entraînement, vous pouvez voir la sortie via MAG0.PNG & MAG1.PNG, qui compare le spectrogramme appris à la vérité Groung.
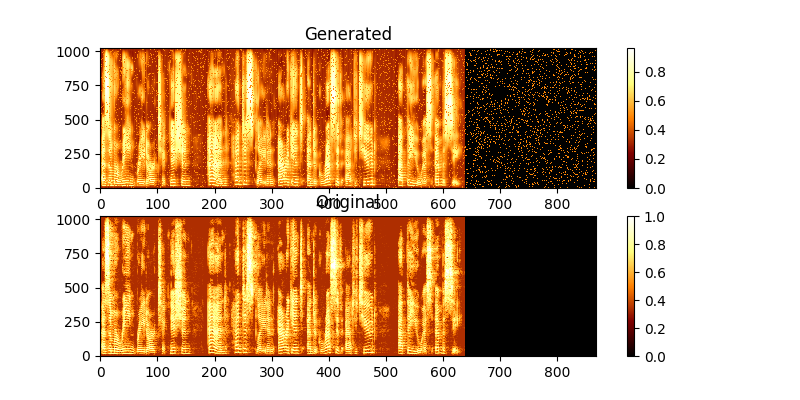
Pour synthétiser une nouvelle utilisation de la section:
$ python synth.py --text "sentance to synthesize" --file output.wav
Vous pouvez exécuter un serveur Web de démonstration pour faire TTS en exécutant
$ python server.py
Cela utilise Flask Framework pour exécuter la démo


