dctts2
1.0.0
นี่คือการดำเนินการของกระดาษ "ระบบข้อความเป็นคำพูดที่ฝึกอบรมได้อย่างมีประสิทธิภาพโดยใช้เครือข่ายเชิงลึกที่มีความสนใจ" https://arxiv.org/abs/1710.08969
รหัสขึ้นอยู่กับการใช้งานต่อไปนี้
รุ่นรถไฟ "Text2Mel" & "SSRN" แยกออกจากกันผ่าน trainmel.py & trainmag.py ตามลำดับคุณต้องดาวน์โหลดชุดข้อมูล ljspeech ที่ https://keithito.com/lj-speech-dataset/
คุณสามารถฟัง ตัวอย่างเสียง
สามารถดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมล่วงหน้าได้ ที่นี่
ก่อนอื่นคุณต้องเตรียมชุดข้อมูล หากคุณต้องการใช้ชุดข้อมูล LJSpeech คุณสามารถใช้คำสั่งต่อไปนี้
$ wget http://data.keithito.com/data/speech/LJSpeech-1.0.tar.bz2
$ tar xvf LJSpeech-1.0.tar.bz2
$ python prepro.py
$ python trainmel.py
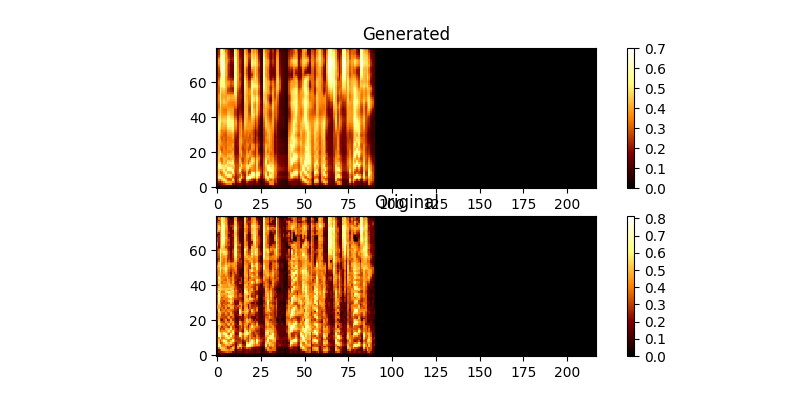
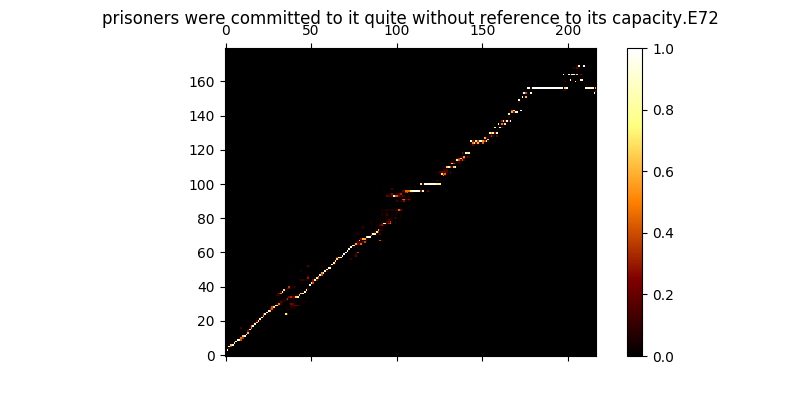
ในระหว่างการฝึกอบรมคุณสามารถตรวจสอบผลลัพธ์ (โดยค่าเริ่มต้นทุก ๆ 200 minibatches) มันทิ้งตัวอย่างสองตัวอย่างแรกในชุดลงใน mel0.png & mel1.png และดูความสนใจที่เรียนรู้ผ่าน a0.png & a1.png
$ python trainmag.py
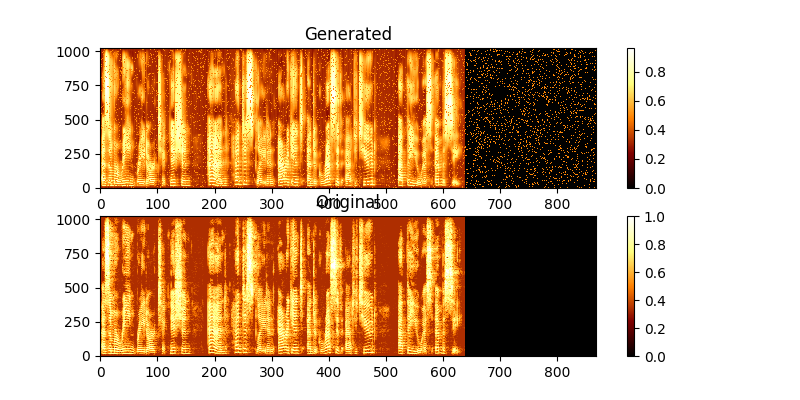
ในระหว่างการฝึกอบรมคุณสามารถดูผลลัพธ์ผ่าน mag0.png & mag1.png ซึ่งเปรียบเทียบสเปกโตรแกรมที่เรียนรู้กับความจริงของ Groung
เพื่อสังเคราะห์การใช้คำสั่งใหม่:
$ python synth.py --text "sentance to synthesize" --file output.wav
คุณสามารถเรียกใช้เว็บเซิร์ฟเวอร์สาธิตเพื่อทำ TTS โดยเรียกใช้
$ python server.py
สิ่งนี้ใช้ Flask Framework เพื่อเรียกใช้การสาธิต


