dctts2
1.0.0
Dies handelt
Der Code basiert auf den folgenden Implementierungen
Das Modell Trains "text2mel" & "ssrn" separat durch trainmelmel.py & trainmag.py Sie müssen den LJSpeech-Datensatz herunterladen
Sie können Audio -Samples anhören
Vorausgebildete Modelle können hier heruntergeladen werden
Zuerst müssen Sie den Datensatz vorbereiten. Wenn Sie den LJSpeech -Datensatz verwenden möchten, können Sie die folgenden Befehle verwenden.
$ wget http://data.keithito.com/data/speech/LJSpeech-1.0.tar.bz2
$ tar xvf LJSpeech-1.0.tar.bz2
$ python prepro.py
$ python trainmel.py
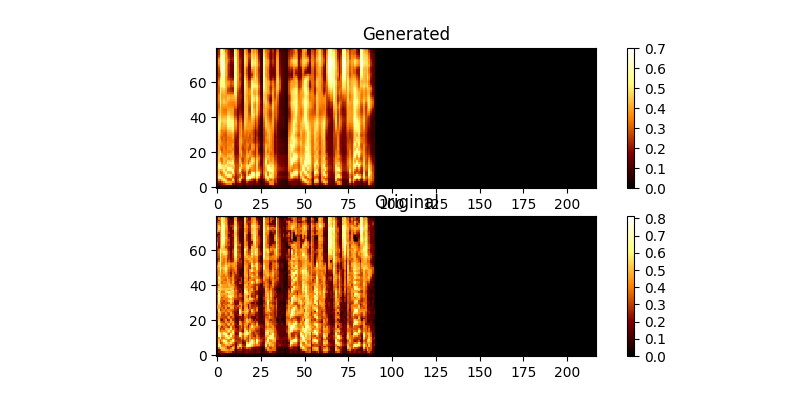
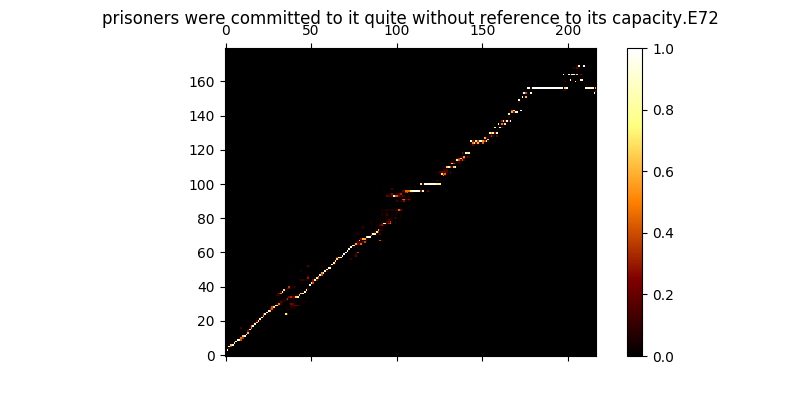
Während des Trainings können Sie die Ausgabe (standardmäßig alle 200 Minibatches) überprüfen, um die ersten beiden Beispiele in der Charge in mel0.png & mel1.png zu überprüft.
$ python trainmag.py
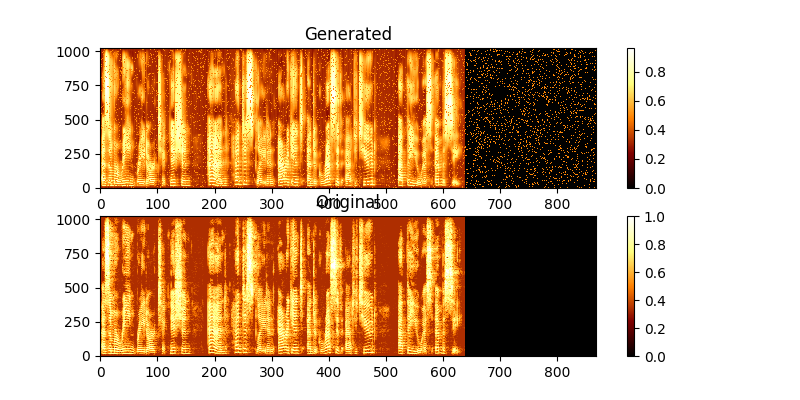
Während des Trainings können Sie die Ausgabe über Mag0.png & Mag1.png betrachten, das das gelernte Spektrogramm mit der Groung -Wahrheit vergleicht.
Um eine neue Sendance -Verwendung zu synthetisieren:
$ python synth.py --text "sentance to synthesize" --file output.wav
Sie können einen Demo -Webserver ausführen, um TTs durch Ausführen durchzuführen
$ python server.py
Dadurch wird Flask Framework verwendet, um die Demo auszuführen


