dctts2
1.0.0
Esta es una implementación del documento "Sistema de texto a especie eficientemente capacitable basado en redes convolucionales profundas con atención guiada" https://arxiv.org/abs/1710.08969
El código se basa en las siguientes implementaciones
El modelo entrena "Text2mel" y "SSRN" por separado a través de Trainmel.py & Trainmag.py, respectivamente, debe descargar el conjunto de datos LJSpeech disponible en https://keithito.com/lj-speech-dataset/
Puedes escuchar muestras de audio
Los modelos previamente capacitados se pueden descargar aquí
Primero, debe preparar el conjunto de datos. Si desea usar el conjunto de datos LJSPEECch, puede usar los siguientes comandos.
$ wget http://data.keithito.com/data/speech/LJSpeech-1.0.tar.bz2
$ tar xvf LJSpeech-1.0.tar.bz2
$ python prepro.py
$ python trainmel.py
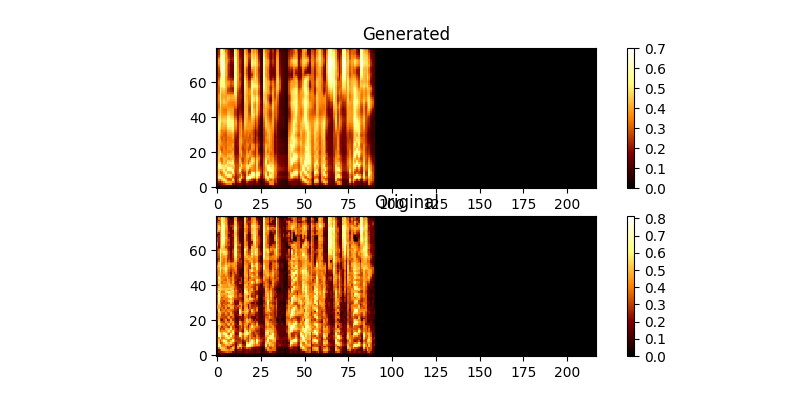
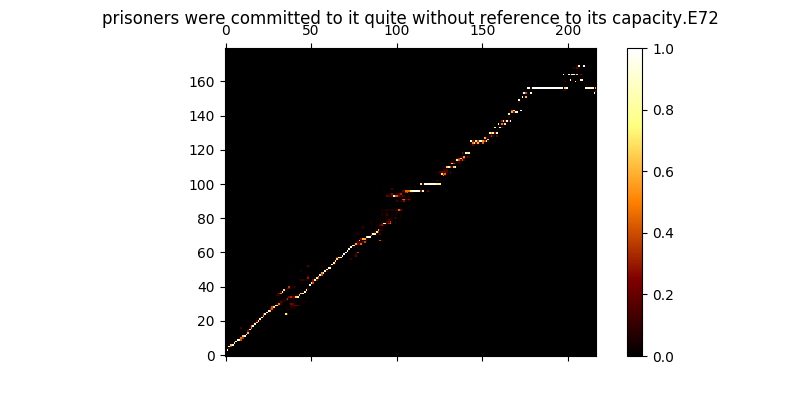
Durante el entrenamiento, puede revisar la salida (por defecto cada 200 minibatches), descarta los dos primeros ejemplos en el lote a Mel0.png & Mel1.png, así que vea la atención aprendida a través de A0.png & a1.png
$ python trainmag.py
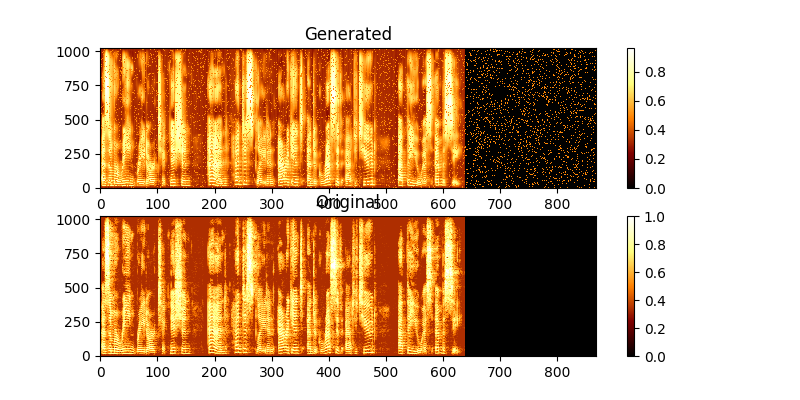
Durante el entrenamiento, puede ver la salida a través de MAG0.png y mag1.png, que compara el espectrograma aprendido con la verdad de Groung.
Para sintetizar un nuevo uso de la sentencia:
$ python synth.py --text "sentance to synthesize" --file output.wav
Puede ejecutar un servidor web de demostración para hacer TTS ejecutando
$ python server.py
Esto usa el marco de frascos para ejecutar la demostración


