dctts2
1.0.0
이 논문의 구현은 "https://arxiv.org/abs/1710.08969를 안내하는 깊은 컨볼 루션 네트워크를 기반으로 효율적으로 훈련 가능한 텍스트 음성 음성 시스템을 구현 한 것입니다.
코드는 다음 구현을 기반으로합니다
이 모델은 Trainmel.py & Trainmag.py를 통해 "Text2mel"및 "SSRN"을 각각 별도로 진행합니다.
오디오 샘플 을들을 수 있습니다
미리 훈련 된 모델은 여기에서 다운로드 할 수 있습니다
먼저 데이터 세트를 준비해야합니다. ljspeech 데이터 세트를 사용하려면 다음 명령을 사용할 수 있습니다.
$ wget http://data.keithito.com/data/speech/LJSpeech-1.0.tar.bz2
$ tar xvf LJSpeech-1.0.tar.bz2
$ python prepro.py
$ python trainmel.py
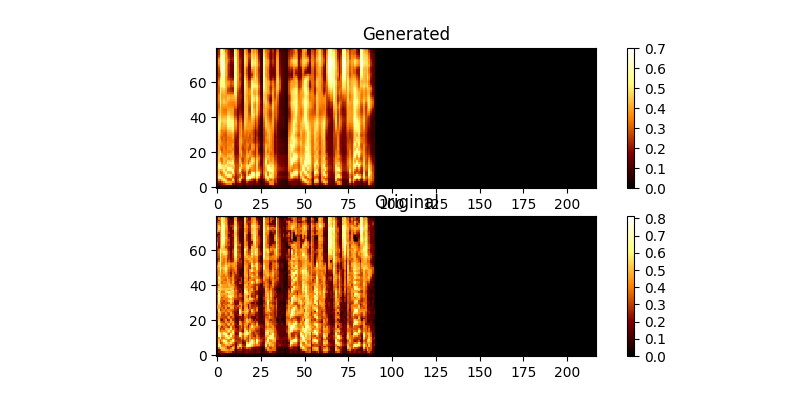
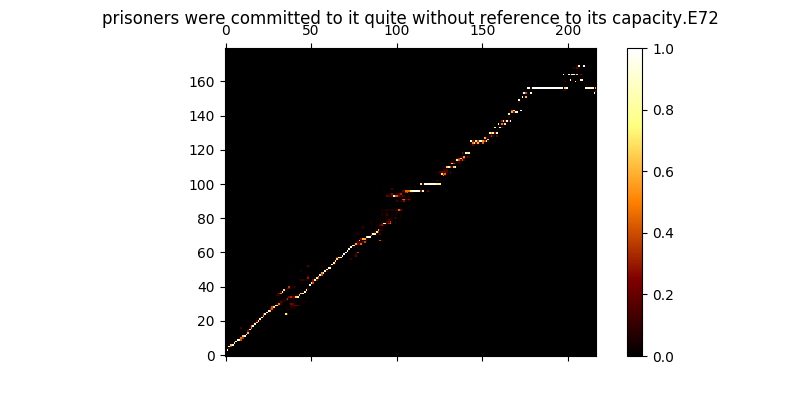
훈련 중에 출력을 검토 할 수 있습니다 (기본적으로 200 개의 미니 디바치마다) 배치에 처음 두 예제를 Mel0.png & Mel1.png에 버리고 A0.png & A1.png를 통해 학습 된 관심을보십시오.
$ python trainmag.py
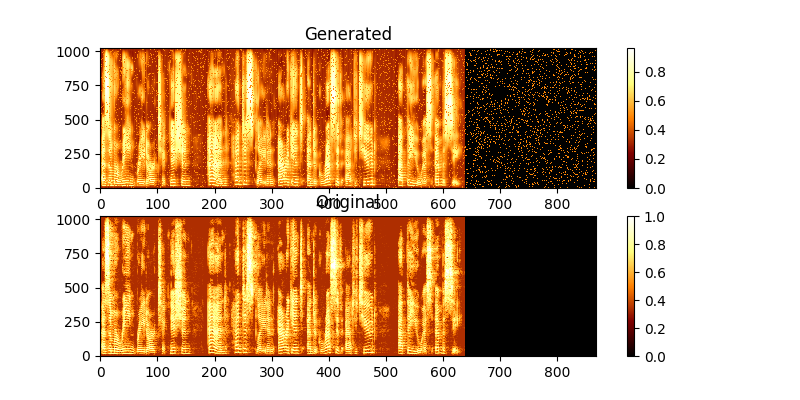
훈련 중에 MAG0.png & MAG1.png를 통해 출력을 볼 수 있으며, 이는 학습 된 스펙트로 그램을 groung 진실과 비교합니다.
새로운 선고 사용을 종합하기 위해 :
$ python synth.py --text "sentance to synthesize" --file output.wav
데모 웹 서버를 실행하여 실행하여 TTS를 수행 할 수 있습니다.
$ python server.py
이것은 플라스크 프레임 워크를 사용하여 데모를 실행합니다


