dctts2
1.0.0
Ini adalah implementasi dari makalah "sistem teks-ke-speech yang dapat dilatih secara efisien berdasarkan jaringan konvolusional yang dalam dengan perhatian terpandu" https://arxiv.org/abs/1710.08969
Kode ini didasarkan pada implementasi berikut
Model melatih "Text2Mel" & "SSRN" secara terpisah melalui trainmel.py & trainmag.py Anda perlu mengunduh dataset LJSPEECH yang tersedia di https://keithito.com/lj-sheech-dataset/
Anda dapat mendengarkan sampel audio
Model pra-terlatih dapat diunduh di sini
Pertama, Anda harus menyiapkan dataset. Jika Anda ingin menggunakan dataset LJSPEECH, Anda dapat menggunakan perintah berikut.
$ wget http://data.keithito.com/data/speech/LJSpeech-1.0.tar.bz2
$ tar xvf LJSpeech-1.0.tar.bz2
$ python prepro.py
$ python trainmel.py
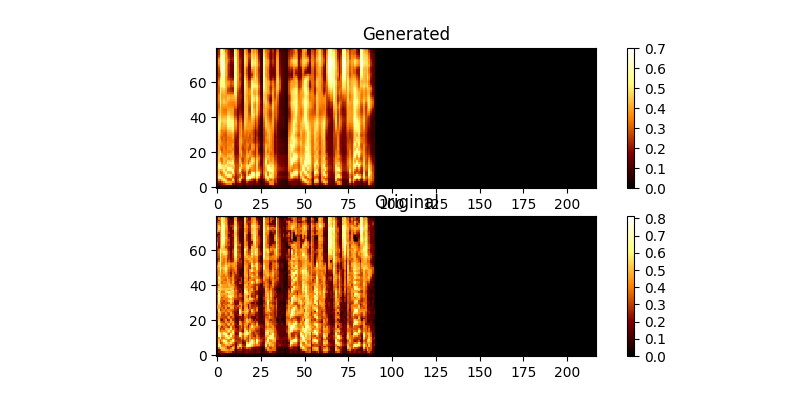
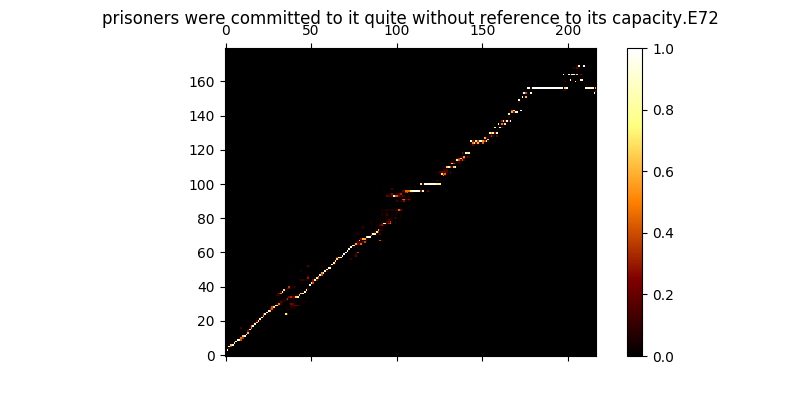
Selama pelatihan, Anda dapat meninjau output (secara default setiap 200 minibatch) ia membuang dua contoh pertama dalam batch ke dalam Mel0.png & Mel1.png juga melihat perhatian yang dipelajari melalui a0.png & a1.png
$ python trainmag.py
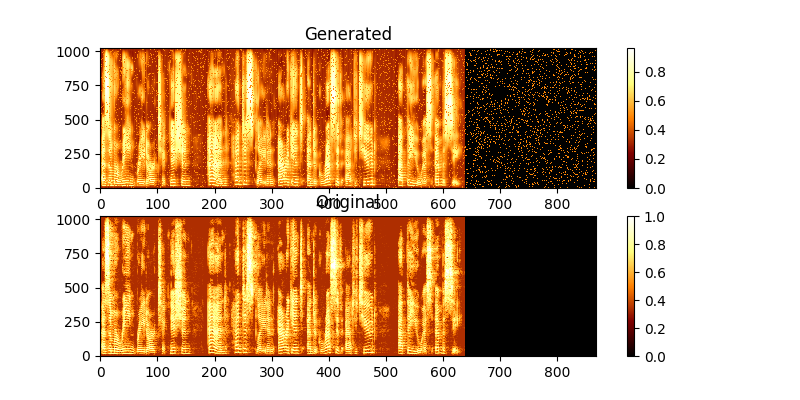
Selama pelatihan, Anda dapat melihat output melalui MAG0.PNG & mag1.png, yang membandingkan spektrogram yang dipelajari dengan kebenaran Groung.
Untuk mensintesis penggunaan Sentance baru:
$ python synth.py --text "sentance to synthesize" --file output.wav
Anda dapat menjalankan server web demo untuk melakukan TTS dengan menjalankan
$ python server.py
Ini menggunakan kerangka flask untuk menjalankan demo


