dctts2
1.0.0
هذا هو تطبيق الورقة "نظام النص إلى الكلام القابل للتدريب بكفاءة استنادًا إلى شبكات تلافيفية عميقة مع اهتمام موجه" https://arxiv.org/abs/1710.08969
يعتمد الرمز على التطبيقات التالية
يدرب النموذج "Text2mel" & "SSRN" بشكل منفصل من خلال Trainmel.py & Trainmag.py على التوالي تحتاج إلى تنزيل مجموعة بيانات LJSpeech المتاحة على https://keithito.com/lj-spech-dataset/
يمكنك الاستماع إلى عينات الصوت
يمكن تنزيل النماذج المدربة مسبقًا هنا
أولاً ، عليك إعداد مجموعة البيانات. إذا كنت ترغب في استخدام مجموعة بيانات LJSpeech ، فيمكنك استخدام الأوامر التالية.
$ wget http://data.keithito.com/data/speech/LJSpeech-1.0.tar.bz2
$ tar xvf LJSpeech-1.0.tar.bz2
$ python prepro.py
$ python trainmel.py
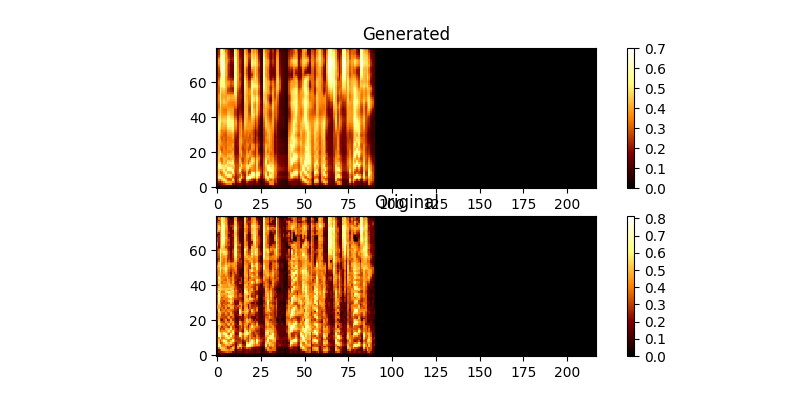
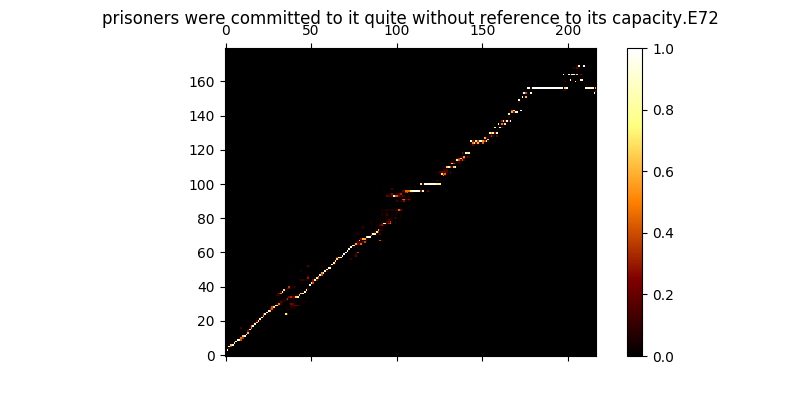
أثناء التدريب ، يمكنك مراجعة المخرجات (افتراضيًا كل 200 حافلة صغيرة) ، يتفريغ أول مثالين في الدفعة في MEL0.PNG & MEL1.PNG وكذلك عرض الانتباه المستفاد من خلال A0.PNG & A1.PNG
$ python trainmag.py
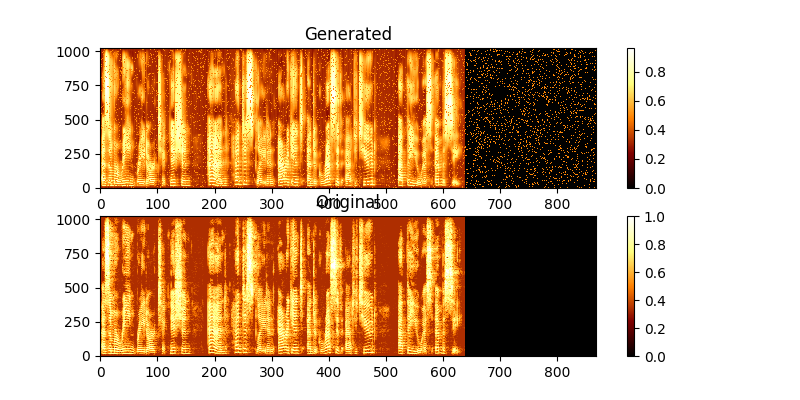
أثناء التدريب ، يمكنك عرض الإخراج من خلال mag0.png & mag1.png ، والذي يقارن الطيف المستفاد مع حقيقة Groung.
لتوليف استخدام عقوبة جديدة:
$ python synth.py --text "sentance to synthesize" --file output.wav
يمكنك تشغيل خادم ويب تجريبي للقيام بـ TTS عن طريق التشغيل
$ python server.py
هذا يستخدم إطار قارورة لتشغيل العرض التوضيحي


