dctts2
1.0.0
Это реализация статьи «эффективно обучаемой системы текста в речь, основанная на глубоких сверточных сетях с руководством» https://arxiv.org/abs/1710.08969
Код основан на следующих реализациях
Модель обучает «text2mel» и «ssrn» отдельно через Trainmel.py & trainmag.py, соответственно, вам нужно загрузить набор данных LJSPEECH, доступный по адресу https://keithito.com/lj-peech-dataset/
Вы можете слушать образцы звука
Предварительно обученные модели можно загрузить здесь
Во -первых, вы должны подготовить набор данных. Если вы хотите использовать набор данных LJSPEECH, вы можете использовать следующие команды.
$ wget http://data.keithito.com/data/speech/LJSpeech-1.0.tar.bz2
$ tar xvf LJSpeech-1.0.tar.bz2
$ python prepro.py
$ python trainmel.py
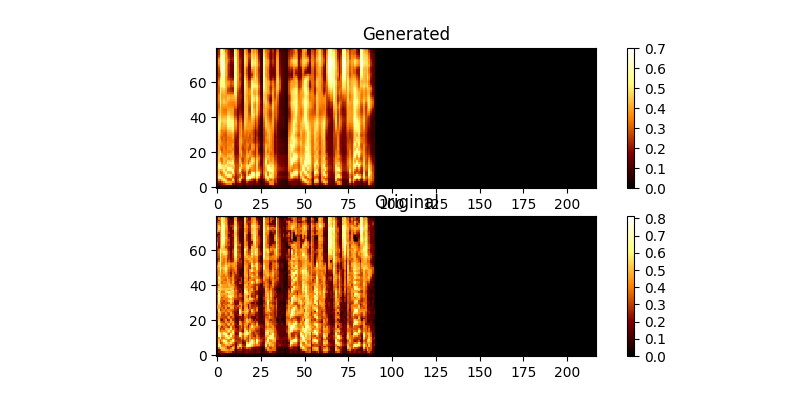
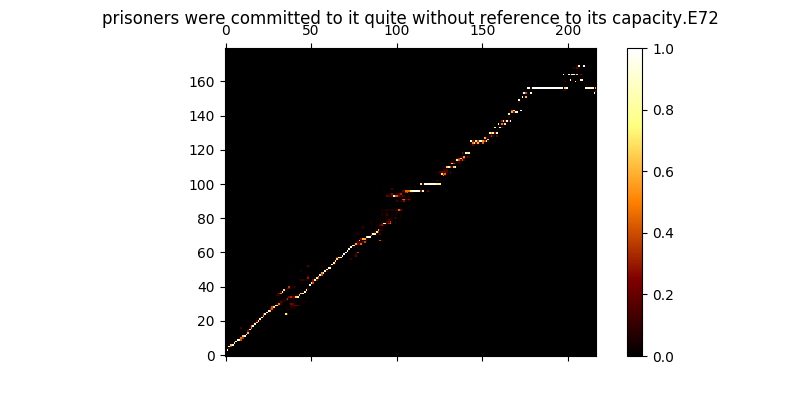
Во время обучения вы можете просмотреть вывод (по умолчанию каждые 200 minibatch). Он сбрасывает первые два примера в пакете в Mel0.png & mel1.png, а также просматривать ученый внимание через A0.png & A1.png
$ python trainmag.py
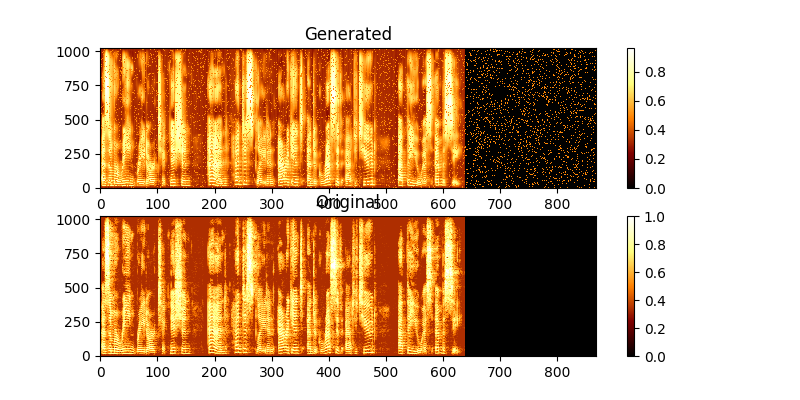
Во время обучения вы можете просмотреть вывод через mag0.png & mag1.png, который сравнивает изученную спектрограмму с истиной Groung.
Чтобы синтезировать новое использование предложения:
$ python synth.py --text "sentance to synthesize" --file output.wav
Вы можете запустить демонстрационный веб -сервер, чтобы сделать TTS, запустив
$ python server.py
Это использует флот -фреймворк для запуска демонстрации


