dctts2
1.0.0
Esta é uma implementação do artigo "Sistema de texto em fala com eficientemente treinável com base em redes convolucionais profundas com atenção guiada" https://arxiv.org/abs/1710.08969
O código é baseado nas seguintes implementações
O modelo treina "text2mel" e "ssrn" separadamente através de trensmel.py & TrainMag.py, respectivamente, você precisa baixar o conjunto de dados do LJSpeech disponível em https://keithito.com/lj-seech-dataset/
Você pode ouvir amostras de áudio
Modelos pré-treinados podem ser baixados aqui
Primeiro, você deve preparar o conjunto de dados. Se você deseja usar o conjunto de dados LJSpeech, pode usar os seguintes comandos.
$ wget http://data.keithito.com/data/speech/LJSpeech-1.0.tar.bz2
$ tar xvf LJSpeech-1.0.tar.bz2
$ python prepro.py
$ python trainmel.py
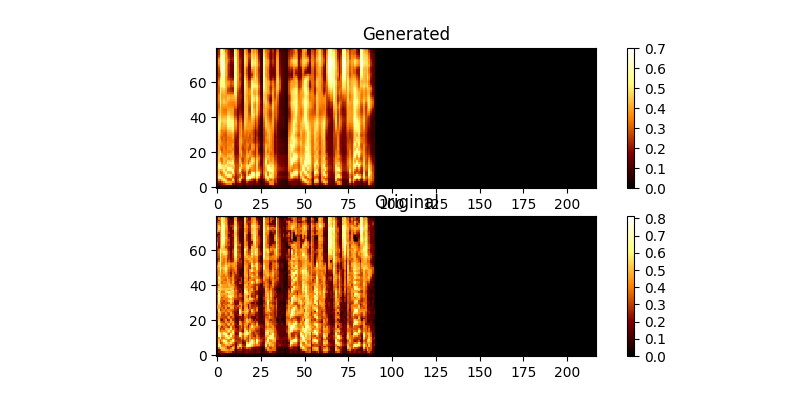
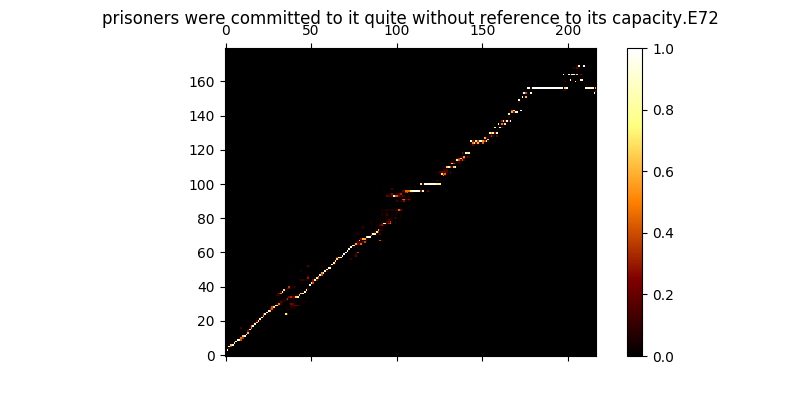
Durante o treinamento, você pode revisar a saída (por padrão a cada 200 minibatches), ele despeja os dois primeiros exemplos no lote em Mel0.png & Mel1.png também veja a atenção aprendida através de A0.png & a1.png
$ python trainmag.py
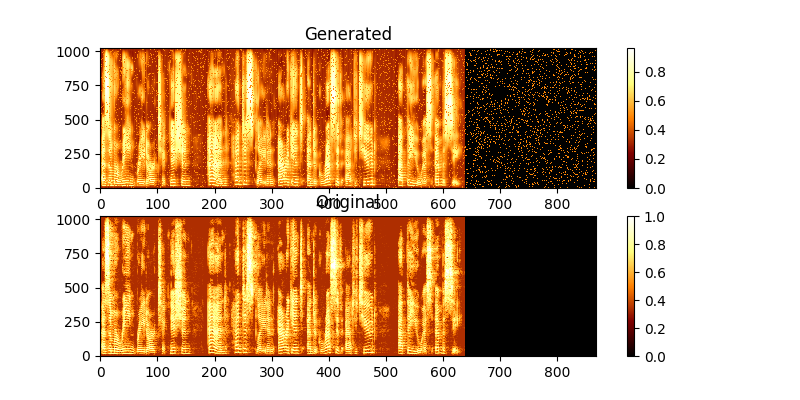
Durante o treinamento, você pode visualizar a saída através do Mag0.png & Mag1.png, que compara o espectrograma aprendido com a verdade groung.
Para sintetizar um novo uso de sentença:
$ python synth.py --text "sentance to synthesize" --file output.wav
Você pode executar um servidor da Demo Web para fazer TTS executando
$ python server.py
Isso usa a estrutura do Flask para executar a demonstração


