kernl
v0.2.2
KERNL可讓您使用單行代碼在GPU上幾次運行Pytorch Transformer模型,並且設計為易於黑客入侵。
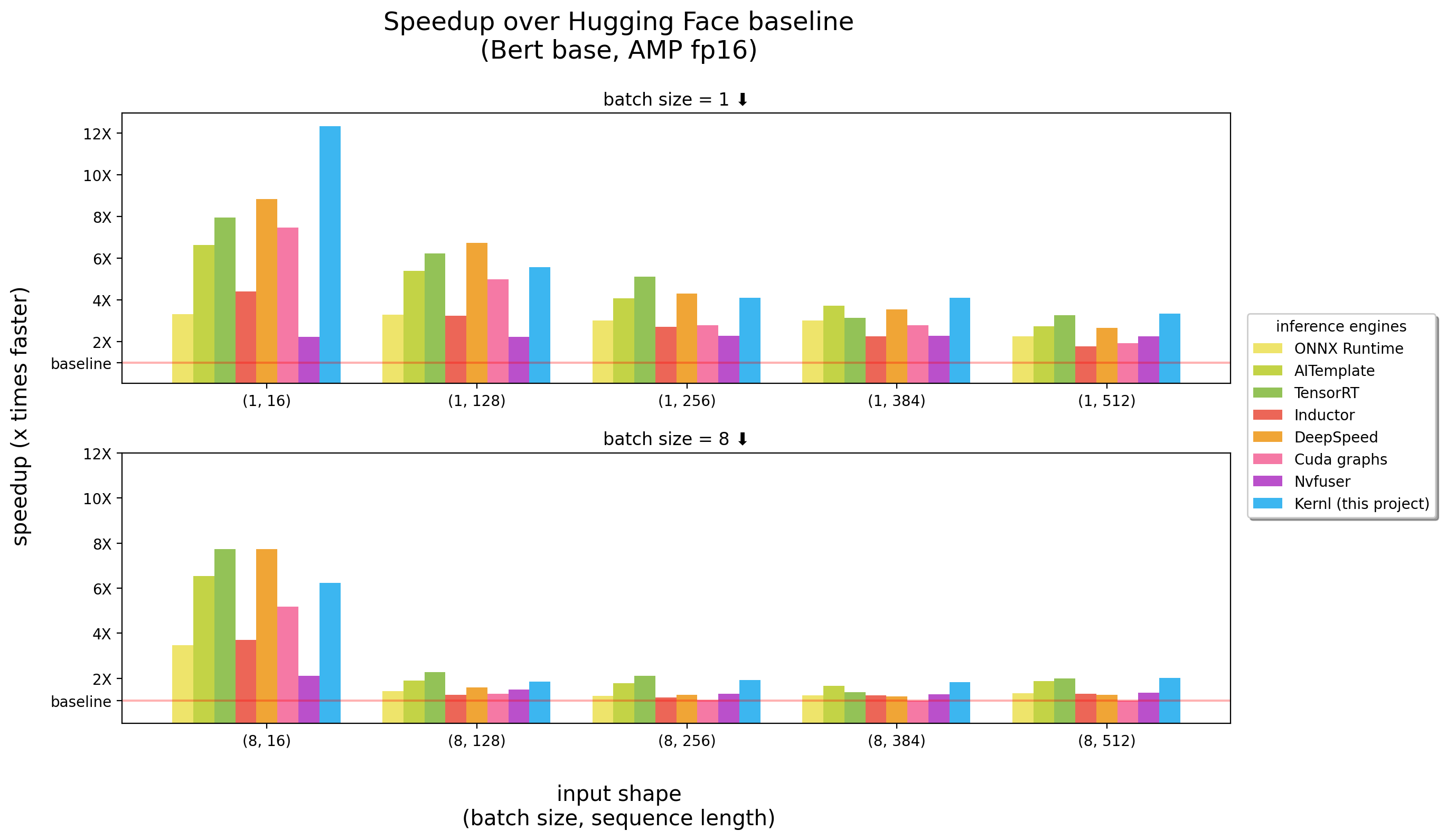
基准在3090 RTX上運行
Kernl是第一個寫的推理引擎cuda c Openai Triton,由Openai設計的一種新語言,旨在使編寫GPU內核變得更容易。
每個內核的代碼少於200行,並且易於理解和修改。
示例列表包含如何將Kernl與Pytorch一起使用。
| 話題 | 筆記本 |
|---|---|
瓷磚matmul :以CUDA樣式的矩陣乘法實現 | 關聯 |
| MatMul偏移:與Triton Matmul實現中使用的性能技巧有關的詳細說明 | 關聯 |
在線SoftMax :並行的軟磁計算, Flash Attention的關鍵要素 | 關聯 |
Flash Attention :注意計算而無需將注意力矩陣保存到全球內存 | 關聯 |
XNLI分類:具有 /沒有優化的分類( Roberta + XNLI分類任務) | 關聯 |
文本生成:具有/沒有優化( T5 ) | 關聯 |
轉錄生成:沒有/沒有優化( Whisper ) | 關聯 |
| ** Llama版本2優化內核融合 | 關聯 |
重要的是:此軟件包需要安裝pytorch 。
請先安裝。
pip install ' git+https://github.com/ELS-RD/kernl '
# or for local dev, after git clone ...
pip install -e .該項目需要Python > = 3.9。此外,庫需要安裝安培的GPU和CUDA。
如果您喜歡Docker :
# build
DOCKER_BUILDKIT=1 docker build -t kernl .
# run
docker run --rm -it --gpus all -v $( pwd ) :/kernl kernl import torch
from transformers import AutoModel
from kernl . model_optimization import optimize_model
model = AutoModel . from_pretrained ( "model_name" ). eval (). cuda ()
optimize_model ( model )
inputs = ...
with torch . inference_mode (), torch . cuda . amp . autocast ():
outputs = model ( ** inputs )對於端到端用例,您可能需要檢查:
test_benchmark_開頭的名稱implementation參數 # tada!
pytest有超過2k的基準測試,它們需要一段時間才能運行。
關於PyTest工作原理的一些規則,特別是對於基準:
-k添加到過濾器測試/基準測試名稱(例如pytest -k benchmark ,以僅以其名稱運行benchmark測試pytest -k "benchmark and not bert"如果要運行所有基準測試,除了與bert相關的基準之外pytest -k benchmark --benchmark-group-by ... ::pytest -k benchmark --benchmark-group-by fullfuncpytest -k benchmark --benchmark-group-by param:implementation,param:shapeparam:x , x是@pytest.mark.parametrize中的參數名稱pytest -k benchmark --benchmark-group-by fullfunc,param:implementation-s查看測試的輸出(打印等)-v要查看測試的詳細輸出警告: param:X如果X不是至少一個函數ran的參數,則X會造成Pytest崩潰。
一些有用的命令:
# only benchmarks
pytest -k benchmark
# no benchmarks
pytest -k " not benchmark "
# only linear layers benchmark, group by shape and if the input is contiguous or not
pytest test/test_linear_layer.py --benchmark-group-by fullfunc,param:shape,param:contiguous圖表中替換功能/模塊調用的第一步是創建將要替換的模式。最簡單的方法是將模型轉換為FX圖,然後使用utils.graph_report或通過打印代碼打印print(you_graph_module.code)將其打印出來。
然後,您可以使用repent_pattern替換圖中的模式。例如,我們擁有自己的replace_pattern版本,並具有一些可與模塊一起使用的增強功能。您可以在optimizer文件夾中找到該示例。
我們使用black / isort / flake8格式化代碼。您可以運行它們:
make source_code_format
make source_code_check_format在Lefebvre Sarrut,我們在生產中運行了幾個變壓器,其中一些是延遲敏感的(主要是搜索和收穫)。
我們正在使用Onnxruntime和Tensorrt,甚至創建了Transformer-Deploy一個OSS庫與社區分享我們的知識。
最近,我們正在測試生成語言,並試圖加速它們。傳統工具證明這很困難。
基本上,簡而言之,在我們看來,Onnx(餵養這些工具的主要格式)是一種有趣的格式,具有對硬件的廣泛支持。
但是,當我們處理新的LLM體系結構時,其生態系統(和主要是推理引擎)有一些局限性:
非常煩人的一件事是,新模型永遠不會加速,您需要等待某人為此編寫自定義CUDA內核。
並不是說解決方案很糟糕,OnnxRuntime的一件大事是其多硬件支持。
關於張力,這真的很快。
因此,我們想要像Tensorrt和Python / Pytorch一樣快的東西,這就是我們建造Kernl的原因。
簡單的規則是,內存帶寬通常是深度學習中的瓶頸,為了加速推斷,減少內存訪問通常是一個很好的策略。簡而言之,瓶頸通常與CPU開銷有關,也必須將其刪除。違反直覺,為了使事情更快,您無需更快地計算。
我們主要利用3種技術:
Openai Triton:這是一種編寫諸如CUDA之類的GPU內核的語言(不要與Nvidia Triton推理服務器相混淆),但生產力更高(至少對我們來說)。改進是由於多個操作的融合,使我們能夠鏈接計算而無需保存中間結果在GPU內存中。我們正在使用它來重寫:
CUDA圖:您可能已經聽說Python很慢,Blablabla且限制開銷的C ++/Rust應該是解決方案。這是真的,但比低頂的開銷更好。那是庫達圖!在熱身步驟中,它將節省每個內核及其參數,然後通過單個GPU指示,我們可以重新推斷整個推斷。
Torchdynamo:該原型來自META,有助於我們應對動態行為。它在此處進行了描述,在熱身步驟中用幾句話可以追踪模型並提供FX圖(靜態計算圖)。我們用我們的內核代替了該圖的某些操作,並將其重新編譯為Python。我們為我們期望擁有的任何可能的動態行為做到這一點。在推論過程中,分析輸入,並使用正確的靜態圖。這確實是一個很棒的項目,請檢查他們的回購以了解更多。
Openai Triton內核代碼從OpenAI Triton教程或Xformers庫中的示例中汲取靈感。
如果您想為代碼或文檔做出貢獻,請參閱我們的貢獻指南。
有關我們要建立的社區的任何疑問,請參閱我們的行為守則,如果您需要與非專業行為的人需要幫助,該怎麼辦。


