kernl
v0.2.2
Kernlでは、Pytorchトランスモデルを単一のコードを使用してGPUで数倍速く実行でき、簡単にハッキングできるように設計されています。
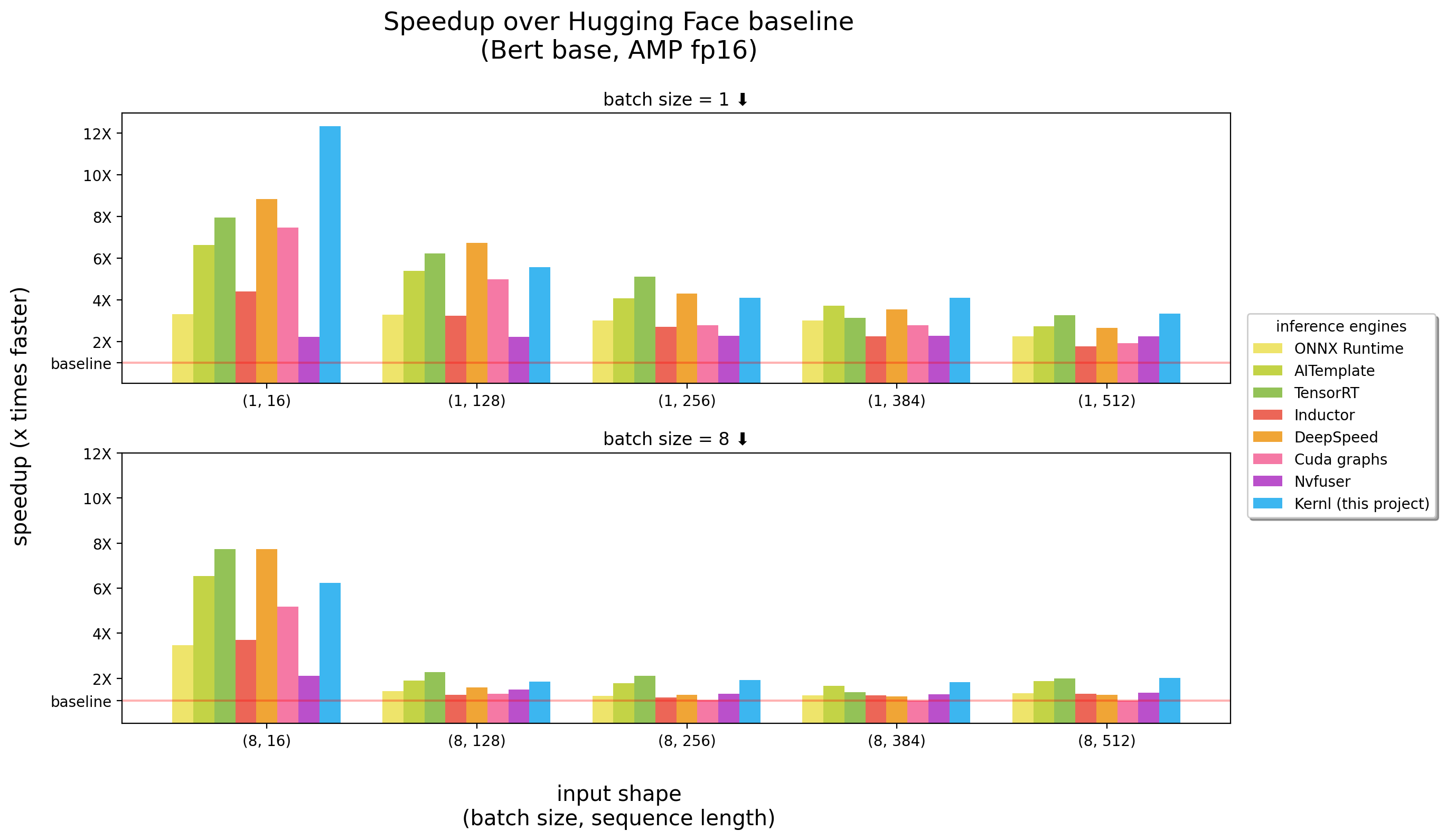
ベンチマークは3090 RTXで実行されました
Kernlは、最初に書かれたOSS推論エンジンですcuda c Openai Tritonは、GPUカーネルの書きやすくするためにOpenaiによって設計された新しい言語です。
各カーネルは200行未満のコードであり、理解して修正しやすいです。
例のリストには、PytorchでKernlを使用する方法が含まれています。
| トピック | ノート |
|---|---|
タイル張られたマトムール: CUDAスタイルのマトリックス乗算実装 | リンク |
| Matmul Offsets :Triton Matmulの実装で使用されるパフォーマンストリックに関連する詳細な説明 | リンク |
オンラインソフトマックス:並列化されたソフトマックス計算、 Flash Attentionの重要な成分 | リンク |
Flash Attention :注意マトリックスをグローバルメモリに保存せずに注意計算 | リンク |
XNLI分類:最適化の /なしで分類( Roberta + XNLI分類タスク) | リンク |
テキスト生成:最適化の有無( T5 ) | リンク |
転写生成:最適化の有無( Whisper ) | リンク |
| ** llamaバージョン2カーネルフュージョンによる最適化 | リンク |
重要:このパッケージでは、 pytorchをインストールする必要があります。
最初にインストールしてください。
pip install ' git+https://github.com/ELS-RD/kernl '
# or for local dev, after git clone ...
pip install -e .このプロジェクトでは、 Python > = 3.9が必要です。さらに、ライブラリでは、アンペアGPUとCUDAをインストールする必要があります。
Docker好む場合:
# build
DOCKER_BUILDKIT=1 docker build -t kernl .
# run
docker run --rm -it --gpus all -v $( pwd ) :/kernl kernl import torch
from transformers import AutoModel
from kernl . model_optimization import optimize_model
model = AutoModel . from_pretrained ( "model_name" ). eval (). cuda ()
optimize_model ( model )
inputs = ...
with torch . inference_mode (), torch . cuda . amp . autocast ():
outputs = model ( ** inputs )エンドツーエンドのユースケースについては、確認することをお勧めします。
test_benchmark_で始まる名前が必要ですimplementationと呼ばれるPARAMが必要です # tada!
pytest2k以上のベンチマークがあり、実行には時間がかかります。
特にベンチマークの場合、 PyTest仕組みに関するいくつかのルール:
pytest -k benchmarkのような名前でテスト/ベンチマークをフィルタリングするために-kを追加しますbenchmarkpytest -k "benchmark and not bert" Bertに関連するベンチマークを除くすべてのベンチマークを実行したい場合pytest -k benchmark --benchmark-group-by ... :pytest -k benchmark --benchmark-group-by fullfuncpytest -k benchmark --benchmark-group-by param:implementation,param:shapeparam:x 、 xは、 @pytest.mark.parametrizeのパラメーター名ですpytest -k benchmark --benchmark-group-by fullfunc,param:implementation-sを追加して、テストの出力(印刷など)を確認します-vを追加して、テストの冗長出力を確認します警告: param:X関数の少なくとも1つのパラメーターではない場合、 XはPytestクラッシュになります。
いくつかの有用なコマンド:
# only benchmarks
pytest -k benchmark
# no benchmarks
pytest -k " not benchmark "
# only linear layers benchmark, group by shape and if the input is contiguous or not
pytest test/test_linear_layer.py --benchmark-group-by fullfunc,param:shape,param:contiguousグラフ内の関数/モジュール呼び出しを置き換える最初のステップは、置き換えるパターンを作成することです。これを行う最も簡単な方法は、モデルをFXグラフに変換し、 utils.graph_reportで印刷するか、コードprint(you_graph_module.code)を印刷して印刷することです。
次に、leplage_patternを使用して、グラフのパターンを置き換えることができます。たとえば、モジュールで動作するためのいくつかの拡張機能を備えた独自のバージョンのreplace_patternがあります。その例は、 optimizerフォルダーで見つけることができます。
black / isort / flake8を使用してコードをフォーマットします。あなたはそれらをで実行することができます:
make source_code_format
make source_code_check_formatLefebvre Sarrutでは、生産でいくつかの変圧器を走らせます。それらのいくつかは、潜在性に敏感です(主に検索と想起)。
OnnxRuntimeとTensortを使用しており、Transformer DeployをOSSライブラリで作成して、コミュニティと知識を共有しています。
最近、私たちは生成言語をテストしており、それらを加速しようとしました。従来のツールでは非常に困難です。
基本的に、そしてそれを短くするために、ONNX(これらのツールをフィードするメイン形式)は、ハードウェアの幅広いサポートを備えた興味深い形式であると思われます。
ただし、そのエコシステム(およびほとんどが推論エンジン)には、新しいLLMアーキテクチャを扱う際にいくつかの制限があります。
非常に迷惑なことの1つは、新しいモデルが決して加速されないという事実です。誰かがそのためにカスタムCudaカーネルを書くのを待つ必要があります。
ソリューションが悪いと言っているわけではありません。OnnxRuntimeの大きなことの1つは、マルチハードウェアサポートです。
Tensortについては、本当に速いです。
したがって、TensortやPython / Pytorchのような速いものが欲しかったので、Kernlを構築しました。
単純なルールは、メモリ帯域幅が多くの場合、深い学習のボトルネックであり、推論を加速するために、メモリアクセスの削減は通常良い戦略です。短い入力シーケンスでは、ボトルネックはしばしばCPUオーバーヘッドに関連しているため、削除する必要があります。直感に反して、物事をより速くするために、計算をより速くする必要はありません。
主に3つのテクノロジーを活用してください。
Openai Triton:CUDAのようなGPUカーネル(Nvidia Triton Inference Serverと混同しないでください)を書くことは言語ですが、はるかに生産的です(少なくとも私たちにとって)。改善は、いくつかのOPSの融合によるものであり、GPUメモリで中間結果を保存せずに計算をチェーンすることができます。私たちはそれを使用して書き直しています:
CUDAグラフ:Pythonが遅く、吹き飛ばされ、頭上のC ++/Rustを制限することが解決策であると聞いたことがあるかもしれません。それは本当ですが、低いオーバーヘッドよりも優れているのは、オーバーヘッドではありません。それはcudaグラフです!ウォームアップステップ中に、すべてのカーネルの起動とそのパラメーターを保存し、単一のGPU命令を使用して、推論全体を再生できます。
Torchdynamo:Metaのこのプロトタイプは、動的な動作に対処するのに役立ちます。ここで説明されており、ウォームアップステップ中にいくつかの単語でモデルを追跡し、FXグラフ(静的計算グラフ)を提供します。このグラフのいくつかの操作をカーネルに置き換え、Pythonで再コンパイルします。私たちは、私たちが期待する可能性のある動的な動作に対してそれを行います。推論中、入力が分析され、正しい静的グラフが使用されます。それは本当に素晴らしいプロジェクトです、彼らのレポをチェックしてもっと知ります。
Openai Triton Kernelsのコードは、Openai TritonチュートリアルまたはXformersライブラリの例からインスピレーションを得ています。
コードやドキュメントなど、貢献したい場合は、貢献ガイドをご覧ください。
私たちが構築しようとしているコミュニティについての質問については、プロフェッショナルで行動している人との助けが必要な場合はどうすればよいかをご覧ください。


