kernl
v0.2.2
Kernl을 사용하면 한 줄의 코드로 GPU에서 Pytorch Transformer 모델을 여러 번 더 빠르게 실행할 수 있으며 쉽게 해킹 할 수 있도록 설계되었습니다.
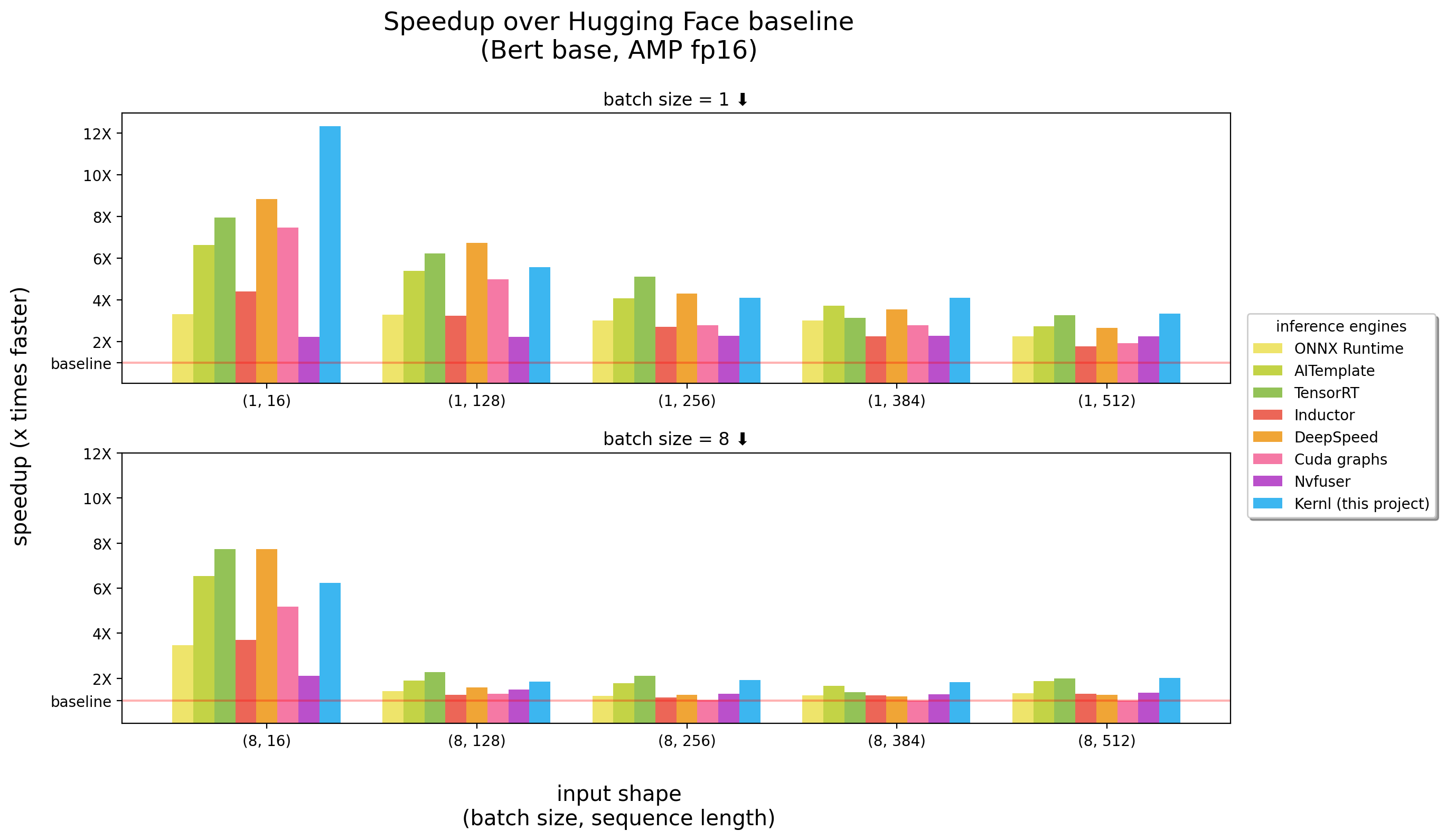
벤치 마크는 3090 RTX에서 실행되었습니다
Kernl은 작성된 최초의 OSS 추론 엔진입니다 쿠다 c Openai Triton, OpenAi가 설계 한 새로운 언어 인 GPU 커널을보다 쉽게 작성할 수 있습니다.
각 커널은 200 줄의 코드 라인 미만이며 이해하고 수정하기 쉽습니다 .
예제 목록에는 Pytorch와 함께 Kernl을 사용하는 방법이 포함되어 있습니다.
| 주제 | 공책 |
|---|---|
타일로 된 매트 : CUDA 스타일의 매트릭스 곱셈 구현 | 링크 |
| Matmul 오프셋 : Triton Matmul 구현에 사용되는 성능 트릭과 관련된 자세한 설명 | 링크 |
온라인 SoftMax : 병렬 소프트 메이스 계산, Flash Attention 의 핵심 요소 | 링크 |
Flash Attention : 글로벌 메모리에주의 매트릭스를 저장하지 않고주의 계산 | 링크 |
XNLI 분류 : 최적화가없는 분류 ( Roberta + XNLI 분류 작업) | 링크 |
텍스트 생성 : 최적화가 있거나없는 ( T5 ) | 링크 |
전사 생성 : 최적화가/없는/없는 ( Whisper ) | 링크 |
| ** 커널 퓨전에 의한 라마 버전 2 최적화 | 링크 |
중요 :이 패키지에는 pytorch 설치되어 있어야합니다.
먼저 설치하십시오.
pip install ' git+https://github.com/ELS-RD/kernl '
# or for local dev, after git clone ...
pip install -e . 이 프로젝트에는 Python > = 3.9가 필요합니다. 또한 라이브러리에는 Ampere GPU와 Cuda가 설치되어 있어야합니다.
Docker 선호하는 경우 :
# build
DOCKER_BUILDKIT=1 docker build -t kernl .
# run
docker run --rm -it --gpus all -v $( pwd ) :/kernl kernl import torch
from transformers import AutoModel
from kernl . model_optimization import optimize_model
model = AutoModel . from_pretrained ( "model_name" ). eval (). cuda ()
optimize_model ( model )
inputs = ...
with torch . inference_mode (), torch . cuda . amp . autocast ():
outputs = model ( ** inputs )엔드 투 엔드 사용 사례의 경우 다음을 확인할 수 있습니다.
test_benchmark_ 로 시작하는 이름이 있어야합니다.implementation 이라는 매개 변수가 있어야합니다. # tada!
pytest2K가 넘는 벤치 마크가 있으며 실행하는 데 시간이 걸립니다.
PyTest 의 작동 방식, 특히 벤치 마크에 대한 일부 규칙 :
pytest -k benchmark 와 같은 이름으로 필터 테스트/벤치 마크에 -k 를 추가하여 이름으로 benchmark 가있는 테스트 만 실행합니다.pytest -k "benchmark and not bert"pytest -k benchmark --benchmark-group-by ... :pytest -k benchmark --benchmark-group-by fullfuncpytest -k benchmark --benchmark-group-by param:implementation,param:shapeparam:x , x 는 @pytest.mark.parametrize 의 매개 변수 이름입니다pytest -k benchmark --benchmark-group-by fullfunc,param:implementation-s 추가하십시오 (인쇄 등)-v 추가하십시오. 경고 : param:X X 실행 된 함수 중 하나 이상의 매개 변수가 아닌 경우 pytest 충돌이 발생합니다.
유용한 명령 :
# only benchmarks
pytest -k benchmark
# no benchmarks
pytest -k " not benchmark "
# only linear layers benchmark, group by shape and if the input is contiguous or not
pytest test/test_linear_layer.py --benchmark-group-by fullfunc,param:shape,param:contiguous 그래프에서 기능/모듈 호출을 대체하는 첫 번째 단계는 교체 할 패턴을 만드는 것입니다. 이 작업을 수행하는 가장 쉬운 방법은 모델을 FX 그래프로 변환 한 다음 utils.graph_report 로 인쇄하거나 코드 print(you_graph_module.code) 인쇄하는 것입니다.
그런 다음 replace_pattern을 사용하여 그래프의 패턴을 대체 할 수 있습니다. 예를 들어 모듈과 함께 작동하도록 향상된 개선 사항이있는 자체 버전의 replace_pattern 있습니다. optimizer 폴더에서 그 예를 찾을 수 있습니다.
우리는 black / isort / flake8 사용하여 코드를 포맷합니다. 다음과 같이 실행할 수 있습니다.
make source_code_format
make source_code_check_formatLefebvre Sarrut에서 우리는 생산에서 여러 변압기를 실행하며, 그 중 일부는 대기 시간에 민감합니다 (검색 및 재활용).
우리는 OnnxRuntime 및 Tensorrt를 사용하고 있으며 Community와 우리의 지식을 공유하기 위해 OSS 라이브러리를 만들었습니다.
최근에 우리는 생성 언어를 테스트하고 있었고이를 가속화하려고 노력했습니다. 전통적인 도구에서는 매우 어려운 것으로 판명됩니다.
기본적으로 짧게하기 위해 ONNX (해당 도구를 공급하기위한 주요 형식)는 하드웨어를 광범위하게 지원하는 흥미로운 형식 인 것 같습니다.
그러나 생태계 (및 주로 추론 엔진)는 새로운 LLM 아키텍처를 다룰 때 몇 가지 제한 사항이 있습니다.
매우 성가신 것은 새로운 모델이 결코 가속화되지 않는다는 사실입니다. 누군가가 맞춤형 Cuda 커널을 작성할 때까지 기다려야합니다.
솔루션이 나쁘다고 말하는 것은 아닙니다. OnnxRuntime의 큰 것은 멀티 하드웨어 지원입니다.
Tensorrt와 관련하여 정말 빠릅니다.
그래서 우리는 Tensorrt와 Python / Pytorch에서 빠른 무언가를 원했습니다. 그래서 우리는 Kernl을 만들었습니다.
간단한 규칙은 메모리 대역폭이 종종 딥 러닝의 병목 현상이며 추론을 가속화하기 위해 메모리 액세스 감소는 일반적으로 좋은 전략입니다. 짧은 입력 순서에서 병목 현상은 종종 CPU 오버 헤드와 관련이 있으므로 제거해야합니다. 직관적으로, 물건을 더 빨리 만들기 위해 계산이 더 빨라질 필요는 없습니다.
우리는 대부분 3 가지 기술을 활용합니다.
Openai Triton : Cuda와 같은 GPU 커널을 작성하는 언어 (Nvidia Triton 추론 서버와 혼동되지 않음)이지만 훨씬 더 생산적입니다 (적어도 미국). 개선은 여러 OPS의 융합으로 인한 것이므로 GPU 메모리에 중간 결과를 저장하지 않고 계산을 체인 할 수 있습니다. 우리는 그것을 사용하여 다시 쓰고 있습니다.
CUDA 그래프 : 파이썬이 느리고 Blablabla가 느리고 오버 헤드 C ++/Rust가 솔루션이어야한다고 들었을 것입니다. 사실이지만 낮은 오버 헤드보다 낫습니다. 그것은 cuda 그래프입니다! 워밍업 단계에서 시작된 모든 커널과 그 매개 변수를 저장 한 다음 단일 GPU 명령으로 전체 추론을 재생할 수 있습니다.
Torchdynamo : Meta 의이 프로토 타입은 역동적 인 행동에 대처하는 데 도움이됩니다. 여기에 설명되어 있으며 워밍업 단계에서 몇 단어로 모델을 추적하고 FX 그래프 (정적 계산 그래프)를 제공합니다. 우리는이 그래프의 일부 작업을 커널로 교체하고 파이썬으로 다시 컴파일합니다. 우리는 우리가 기대할 수있는 동적 행동을 위해 그렇게합니다. 추론 중에 입력이 분석되고 올바른 정적 그래프가 사용됩니다. 정말 멋진 프로젝트입니다. 더 많은 것을 알 수 있도록 레포를 확인하십시오.
OpenAi Triton 커널의 코드는 OpenAi Triton Tutorials 또는 Xformers Library의 예제에서 영감을 얻습니다.
예를 들어 코드 또는 문서에 기여하려면 기여 가이드를 참조하십시오.
우리가 구축하려는 커뮤니티에 대한 질문과 비전문적으로 행동하는 사람과의 도움이 필요한 경우해야 할 일에 대해서는 당사의 행동 강령을 참조하십시오.


