kernl
v0.2.2
Kernl memungkinkan Anda menjalankan model transformator pytorch beberapa kali lebih cepat pada GPU dengan satu baris kode, dan dirancang agar mudah diretas.
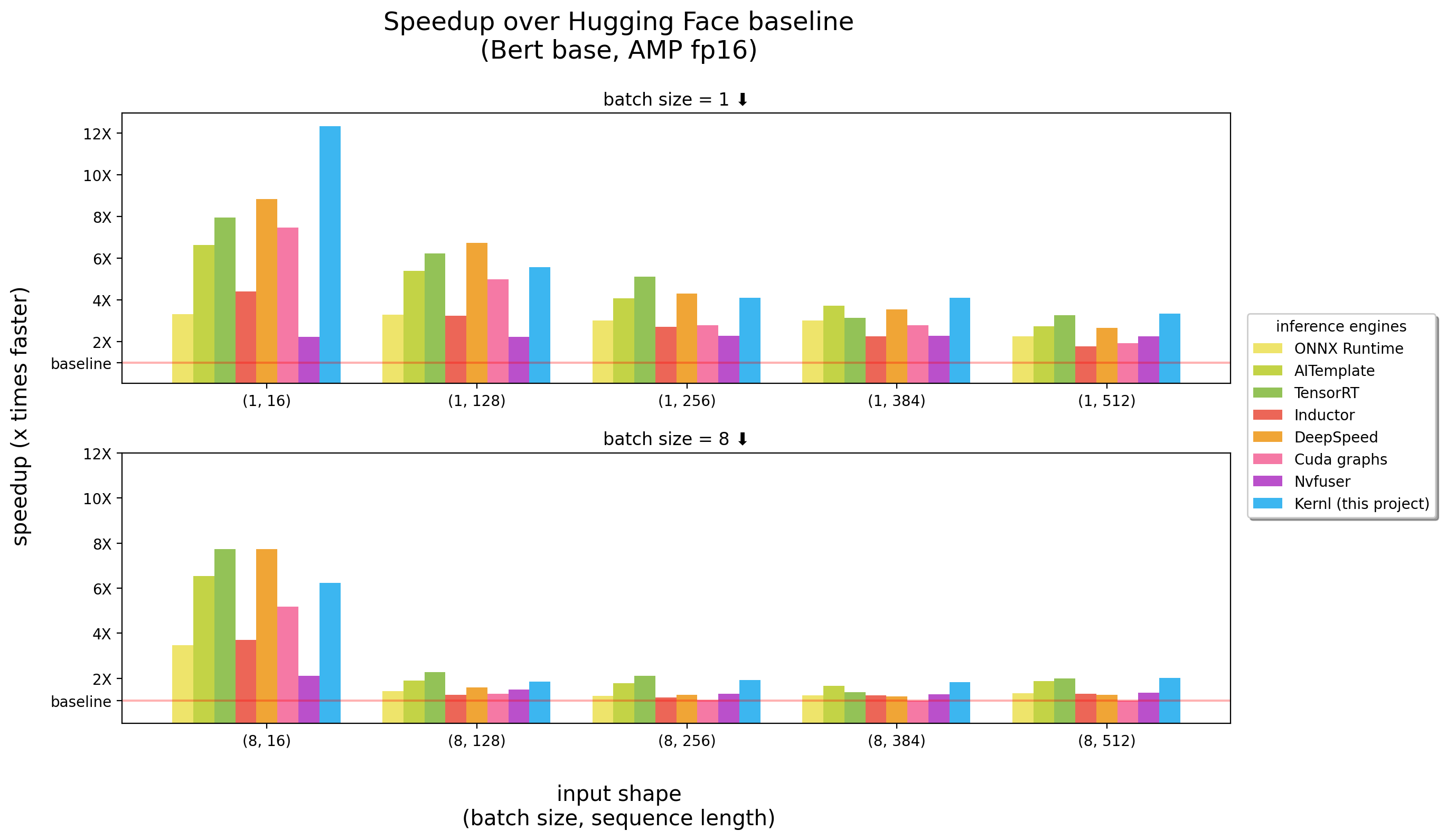
Tolok ukur berlari pada 3090 RTX
Kernl adalah mesin inferensi OSS pertama yang ditulis Cuda c Openai Triton, bahasa baru yang dirancang oleh Openai untuk membuatnya lebih mudah menulis kernel GPU.
Setiap kernel kurang dari 200 baris kode, dan mudah dipahami dan dimodifikasi.
Daftar contoh berisi cara menggunakan kernl dengan pytorch.
| Topik | Buku catatan |
|---|---|
Matriks Matriks Implementasi dalam Gaya CUDA | link |
| Offset Matmul : Penjelasan terperinci terkait dengan trik kinerja yang digunakan dalam implementasi Triton Matmul | link |
Softmax Online : Perhitungan Softmax Paralelisasi, Bahan Utama Flash Attention | link |
Flash Attention : Perhitungan perhatian tanpa menyimpan matriks perhatian ke memori global | link |
Klasifikasi XNLI : Klasifikasi dengan / tanpa optimasi ( Roberta + XNLI Tugas Klasifikasi) | link |
Generasi Teks : Dengan/Tanpa Optimalisasi ( T5 ) | link |
Generasi Transkripsi : Dengan/Tanpa Optimalisasi ( Whisper ) | link |
| ** Llama Versi 2 Optimalisasi oleh Kernel Fusion | link |
Penting : Paket ini membutuhkan pytorch yang diinstal.
Harap instal dulu.
pip install ' git+https://github.com/ELS-RD/kernl '
# or for local dev, after git clone ...
pip install -e . Proyek ini membutuhkan Python > = 3.9. Selain itu, perpustakaan memerlukan GPU dan CUDA Ampere untuk diinstal.
Jika Anda lebih suka Docker :
# build
DOCKER_BUILDKIT=1 docker build -t kernl .
# run
docker run --rm -it --gpus all -v $( pwd ) :/kernl kernl import torch
from transformers import AutoModel
from kernl . model_optimization import optimize_model
model = AutoModel . from_pretrained ( "model_name" ). eval (). cuda ()
optimize_model ( model )
inputs = ...
with torch . inference_mode (), torch . cuda . amp . autocast ():
outputs = model ( ** inputs )Untuk kasus penggunaan ujung ke ujung, Anda mungkin ingin memeriksa:
test_benchmark_implementation saat membandingkan operasi yang sama menggunakan strategi yang berbeda # tada!
pytestAda lebih dari 2K tolok ukur, dan mereka membutuhkan waktu untuk berlari.
Beberapa aturan tentang bagaimana PyTest bekerja, khususnya untuk tolok ukur:
-k untuk memfilter tes/tolok ukur dengan nama mereka seperti pytest -k benchmark untuk menjalankan hanya tes dengan benchmark dalam nama merekapytest -k "benchmark and not bert" jika Anda ingin menjalankan semua tolok ukur kecuali yang terkait dengan Bertpytest -k benchmark --benchmark-group-by ... :pytest -k benchmark --benchmark-group-by fullfuncpytest -k benchmark --benchmark-group-by param:implementation,param:shapeparam:x , x adalah nama parameter di @pytest.mark.parametrizepytest -k benchmark --benchmark-group-by fullfunc,param:implementation-s untuk melihat output dari tes (cetak, dll.)-v untuk melihat output verbose dari tes PERINGATAN : param:X akan membuat pytest macet jika X bukan parameter setidaknya salah satu fungsi berjalan.
Beberapa perintah yang berguna:
# only benchmarks
pytest -k benchmark
# no benchmarks
pytest -k " not benchmark "
# only linear layers benchmark, group by shape and if the input is contiguous or not
pytest test/test_linear_layer.py --benchmark-group-by fullfunc,param:shape,param:contiguous Langkah pertama untuk mengganti panggilan fungsi/modul dalam grafik adalah membuat pola yang akan diganti. Cara termudah untuk melakukan ini adalah dengan mengonversi model ke grafik fx, dan kemudian mencetaknya dengan utils.graph_report atau dengan mencetak print(you_graph_module.code)
Kemudian Anda dapat menggunakan Replikan_Pattern untuk mengganti pola dalam grafik. Kami memiliki versi sendiri dari replace_pattern dengan beberapa peningkatan untuk bekerja dengan modul, misalnya. Anda dapat menemukan contohnya di folder optimizer .
Kami menggunakan black / isort / flake8 untuk memformat kode. Anda dapat menjalankannya dengan:
make source_code_format
make source_code_check_formatDi Lefebvre Sarrut, kami menjalankan beberapa transformator dalam produksi, beberapa di antaranya sensitif terhadap latensi (pencarian dan recsys kebanyakan).
Kami menggunakan onnxruntime dan TensorRT dan bahkan menciptakan transformator-menggunakan perpustakaan OSS untuk berbagi pengetahuan kami dengan komunitas.
Baru -baru ini, kami menguji bahasa generatif, dan kami mencoba mempercepatnya. Ini terbukti sangat sulit dengan alat tradisional.
Pada dasarnya, dan untuk membuatnya pendek, bagi kita tampaknya ONNX (format utama untuk memberi makan alat -alat itu) adalah format yang menarik dengan berbagai dukungan perangkat keras.
Namun, ekosistemnya (dan sebagian besar mesin inferensi) memiliki beberapa batasan ketika kita berurusan dengan arsitektur LLM baru:
Satu hal yang sangat menjengkelkan adalah kenyataan bahwa model baru tidak pernah dipercepat, Anda perlu menunggu seseorang untuk menulis kernel cuda khusus untuk itu.
Ini bukan untuk mengatakan solusinya buruk, satu hal besar dengan onnxruntime adalah dukungan multi perangkat kerasnya.
Mengenai Tensorrt, ini sangat cepat.
Jadi kami menginginkan sesuatu secepat Tensorrt dan di Python / Pytorch, itu sebabnya kami membangun Kernl.
Aturan sederhananya adalah bandwidth memori sering kali merupakan hambatan dalam pembelajaran yang mendalam, untuk mempercepat inferensi, pengurangan akses memori biasanya merupakan strategi yang baik. Pada urutan input pendek, bottleneck sering terkait dengan overhead CPU, itu harus dihapus juga. Secara berlawanan, untuk membuat segalanya lebih cepat, Anda tidak perlu lebih cepat dalam perhitungan.
Kami memanfaatkan sebagian besar 3 teknologi:
Openai Triton: Ini adalah bahasa untuk menulis kernel GPU seperti CUDA (jangan bingung dengan Nvidia Triton Inference Server), tetapi jauh lebih produktif (setidaknya untuk kita). Peningkatan disebabkan oleh perpaduan beberapa OP, membuat kami dapat menghitung perhitungan tanpa menyimpan hasil perantara dalam memori GPU. Kami menggunakannya untuk menulis ulang:
Grafik CUDA: Anda mungkin pernah mendengar bahwa Python lambat, blablabla dan untuk membatasi overhead C ++/karat harus menjadi solusinya. Memang benar tetapi lebih baik daripada overhead rendah tidak ada overhead sama sekali. Itu grafik CUDA! Selama langkah pemanasan, itu akan menyimpan setiap kernel yang diluncurkan dan parameternya, dan kemudian, dengan satu instruksi GPU, kita dapat memutar ulang seluruh inferensi.
Torchdynamo: Prototipe dari meta ini membantu kita mengatasi perilaku dinamis. Ini dijelaskan di sini, dan dalam beberapa kata selama langkah pemanasan itu melacak model dan menyediakan grafik FX (grafik komputasi statis). Kami mengganti beberapa operasi grafik ini dengan kernel kami dan mengkompilasi ulangnya di Python. Kami melakukan itu untuk segala kemungkinan perilaku dinamis yang kami harapkan. Selama inferensi, input dianalisis, dan grafik statis yang benar digunakan. Ini benar -benar proyek yang luar biasa, periksa repo mereka untuk mengetahui lebih banyak.
Kode Kernel Openai Triton mengambil inspirasi dari contoh -contoh dari tutorial Openai Triton atau perpustakaan xformers.
Jika Anda ingin berkontribusi, misalnya kode atau dokumentasi, silakan lihat Panduan Kontribusi kami.
Silakan lihat kode perilaku kami untuk pertanyaan tentang komunitas yang kami coba bangun dan apa yang harus dilakukan jika Anda membutuhkan bantuan dengan seseorang yang bertindak tidak profesional.


