kernl
v0.2.2
يتيح لك Kernl تشغيل نماذج محول Pytorch Models عدة مرات على GPU مع سطر واحد من التعليمات البرمجية ، وهو مصمم ليكون قابلاً للاختراق بسهولة.
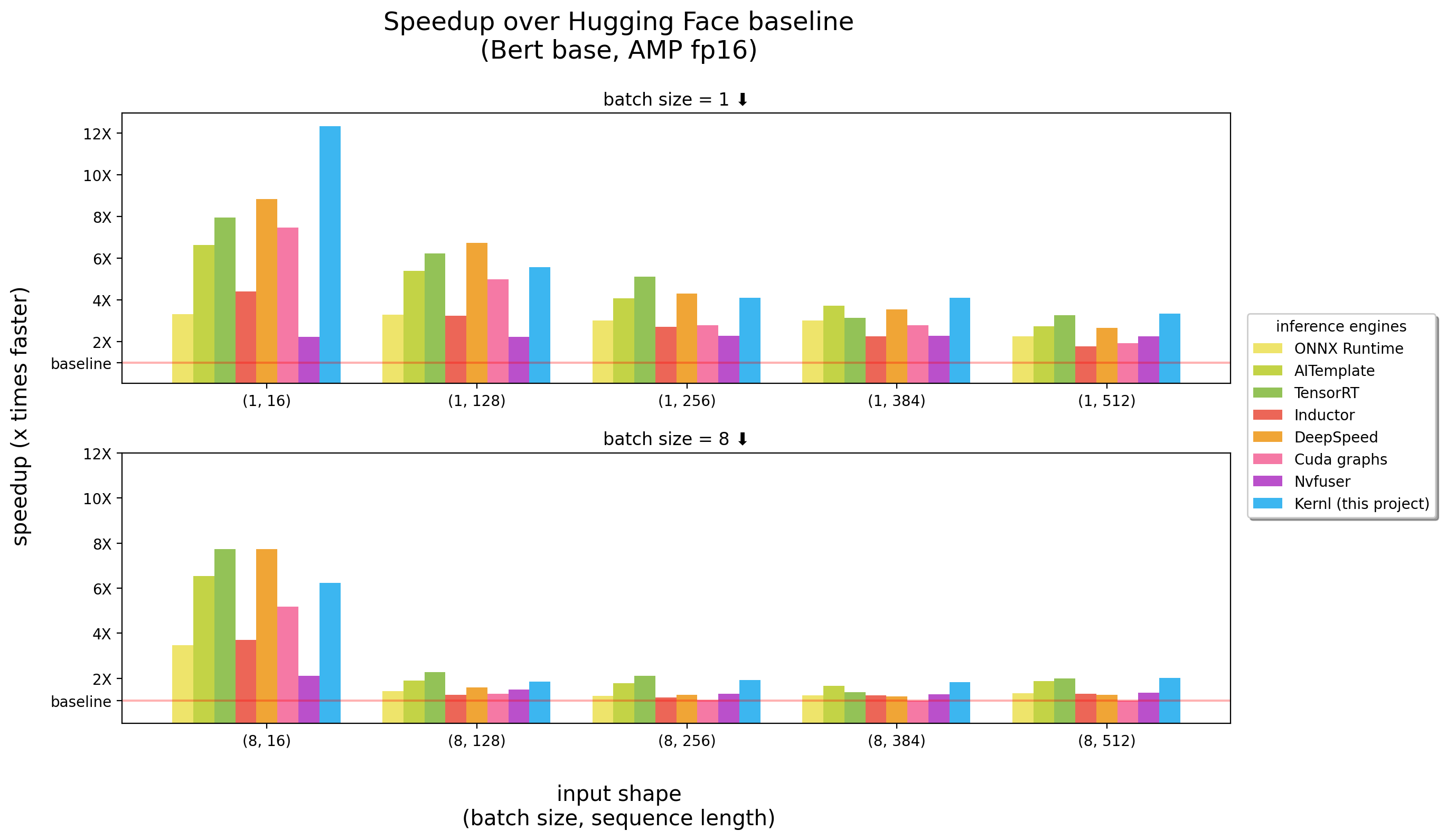
تم تشغيل المعايير على 3090 RTX
Kernl هو أول محرك استنتاج OSS مكتوب في كودا ج Openai Triton ، وهي لغة جديدة صممها Openai لتسهيل كتابة حبات GPU.
كل نواة أقل من 200 سطر من التعليمات البرمجية ، ويسهل فهمها وتعديلها.
تحتوي قائمة الأمثلة على كيفية استخدام kernl مع pytorch.
| عنوان | دفتر |
|---|---|
Matmul Tiled : تنفيذ مضاعف المصفوفة بأسلوب CUDA | وصلة |
| عوامل Matmul : تفسيرات مفصلة تتعلق بخدعة الأداء المستخدمة في تنفيذ Triton Matmul | وصلة |
softmax عبر الإنترنت : حساب softmax المتوازي ، وهو مكون رئيسي Flash Attention | وصلة |
Flash Attention : حساب الانتباه دون توفير مصفوفة الانتباه للذاكرة العالمية | وصلة |
تصنيف Xnli : التصنيف مع / بدون تحسينات (مهمة تصنيف Roberta + XNLI ) | وصلة |
توليد النص : مع/بدون تحسينات ( T5 ) | وصلة |
توليد النسخ : مع/بدون تحسينات ( Whisper ) | وصلة |
| ** تحسين الإصدار 2 من Llama بواسطة kernel Fusion | وصلة |
هام : تتطلب هذه الحزمة تثبيت pytorch .
الرجاء تثبيته أولاً.
pip install ' git+https://github.com/ELS-RD/kernl '
# or for local dev, after git clone ...
pip install -e . يتطلب هذا المشروع Python > = 3.9. علاوة على ذلك ، تتطلب المكتبة تثبيت GPU و CUDA.
إذا كنت تفضل Docker :
# build
DOCKER_BUILDKIT=1 docker build -t kernl .
# run
docker run --rm -it --gpus all -v $( pwd ) :/kernl kernl import torch
from transformers import AutoModel
from kernl . model_optimization import optimize_model
model = AutoModel . from_pretrained ( "model_name" ). eval (). cuda ()
optimize_model ( model )
inputs = ...
with torch . inference_mode (), torch . cuda . amp . autocast ():
outputs = model ( ** inputs )لحالات الاستخدام الشامل ، قد ترغب في التحقق:
test_benchmark_implementation عند قياس نفس العملية باستخدام استراتيجية مختلفة # tada!
pytestهناك أكثر من 2K معايير ، ويستغرقون بعض الوقت للركض.
بعض القواعد حول كيفية عمل PyTest ، لا سيما بالنسبة للمعايير:
-k لتصفية الاختبارات/المعايير باسمها مثل pytest -k benchmark لتشغيل الاختبارات فقط مع benchmark في اسمهمpytest -k "benchmark and not bert" إذا كنت ترغب في تشغيل جميع المعايير باستثناء تلك المتعلقة بيرتpytest -k benchmark --benchmark-group-by ... :::pytest -k benchmark --benchmark-group-by fullfuncpytest -k benchmark --benchmark-group-by param:implementation,param:shapeparam:x ، x هو اسم المعلمة في @pytest.mark.parametrizepytest -k benchmark --benchmark-group-by fullfunc,param:implementation-s لترى إخراج الاختبارات (الطباعة ، إلخ)-v لرؤية الإخراج المطول للاختبارات تحذير : param:X سيجعل تصادم pytest إذا لم يكن X معلمة لواحدة واحدة على الأقل من الوظائف.
بعض الأوامر المفيدة:
# only benchmarks
pytest -k benchmark
# no benchmarks
pytest -k " not benchmark "
# only linear layers benchmark, group by shape and if the input is contiguous or not
pytest test/test_linear_layer.py --benchmark-group-by fullfunc,param:shape,param:contiguous تتمثل الخطوة الأولى لاستبدال مكالمات الوظيفة/الوحدة النمطية في الرسم البياني في إنشاء النمط الذي سيتم استبداله. أسهل طريقة للقيام بذلك هي تحويل النموذج إلى رسم بياني FX ، ثم طباعته باستخدام utils.graph_report أو عن طريق print(you_graph_module.code)
ثم يمكنك استخدام استبدال _pattern لاستبدال النمط في الرسم البياني. لدينا نسختنا الخاصة من replace_pattern ببعض التحسينات للعمل مع الوحدات النمطية ، على سبيل المثال. يمكنك العثور على أمثلة على ذلك في مجلد optimizer .
نستخدم black / isort / flake8 لتنسيق الكود. يمكنك تشغيلها مع:
make source_code_format
make source_code_check_formatفي Lefebvre Sarrut ، نقوم بتشغيل العديد من المحولات في الإنتاج ، وبعضها يكون حساسًا (بحث و Recsys في الغالب).
نحن نستخدم onnxruntime و tensorrt وحتى أنشأنا محولًا-مكتبة OSS لتبادل معرفتنا مع المجتمع.
في الآونة الأخيرة ، كنا نختبر اللغات التوليدية ، وحاولنا تسريعها. إنه يثبت صعبة للغاية مع الأدوات التقليدية.
في الأساس ، ولجعلها قصيرة ، يبدو لنا أن ONNX (التنسيق الرئيسي لتغذية تلك الأدوات) هو تنسيق مثير للاهتمام مع دعم واسع من الأجهزة.
ومع ذلك ، فإن نظامه البيئي (ومعظم محركات الاستدلال) له العديد من القيود عندما نتعامل مع بنيات LLM الجديدة:
شيء واحد مزعج للغاية هو حقيقة أن النماذج الجديدة لم يتم تسريعها أبدًا ، فأنت بحاجة إلى انتظار أن يكتب شخص ما نواة Cuda المخصصة لذلك.
هذا لا يعني أن الحلول سيئة ، شيء واحد كبير مع OnNxRuntime هو دعمها متعدد الأجهزة.
بخصوص Tensorrt ، إنه سريع حقًا.
لذلك أردنا شيئًا سريعًا مثل Tensorrt وعلى Python / Pytorch ، ولهذا السبب قمنا ببناء kernl.
القاعدة البسيطة هي أن عرض النطاق الترددي للذاكرة هو عنق الزجاجة في التعلم العميق ، لتسريع الاستدلال ، عادةً ما يكون تقليل الوصول إلى الذاكرة استراتيجية جيدة. في تسلسل الإدخال القصير ، غالبًا ما يرتبط عنق الزجاجة بنفقات وحدة المعالجة المركزية ، يجب إزالته أيضًا. على نحو مضاد ، لجعل الأمور أسرع ، لا تحتاج إلى أن تكون أسرع في الحساب.
نحن نستفيد في الغالب 3 تقنيات:
Openai Triton: إنها لغة لكتابة نواة GPU مثل CUDA (لا ينبغي الخلط بينها مع خادم Nvidia Triton Inferfect) ، ولكن أكثر إنتاجية (على الأقل بالنسبة لنا). يرجع التحسين إلى اندماج العديد من العمليات ، مما يجعلنا قادرين على سلسلة من عمليات الحسابات دون حفظ نتائج وسيطة في ذاكرة GPU. نحن نستخدمه لإعادة كتابة:
الرسوم البيانية CUDA: ربما سمعت أن Python بطيئة ، blablabla ولتقصر النفقات العامة C ++/Rust يجب أن يكون الحل. هذا صحيح ولكن أفضل من النفقات العامة المنخفضة ليس النفقات العامة على الإطلاق. هذا هو الرسوم البيانية كودا! أثناء خطوة الاحماء ، سيوفر كل نواة يتم إطلاقها ومعلماتها ، وبعد ذلك ، مع تعليمات GPU واحدة ، يمكننا إعادة تشغيل الاستدلال بالكامل.
Torchdynamo: يساعدنا هذا النموذج الأولي من META على التعامل مع السلوك الديناميكي. تم وصفه هنا ، وفي بضع كلمات أثناء خطوة الاحماء ، يتتبع النموذج ويوفر رسم بياني FX (رسم بياني حساب ثابت). نستبدل بعض عمليات هذا الرسم البياني بنواةنا ونعيد ترجمة في بيثون. نحن نفعل ذلك لأي سلوك ديناميكي محتمل نتوقع أن نحصل عليه. أثناء الاستدلال ، يتم تحليل المدخلات ، ويتم استخدام الرسم البياني الثابت الصحيح. إنه حقًا مشروع رائع ، تحقق من ريبو لمعرفة المزيد.
يستلهم كود أوف أوف أوف تريتون الإلهام من أمثلة من البرامج التعليمية Openai Triton أو مكتبة Xformers.
إذا كنت ترغب في المساهمة ، على سبيل المثال إلى رمز أو وثائق ، يرجى الاطلاع على دليل المساهمة لدينا.
يرجى الاطلاع على مدونة قواعد سلوكنا عن أي أسئلة حول المجتمع الذي نحاول بناءه وما يجب القيام به إذا كنت بحاجة إلى مساعدة مع شخص يتصرف بشكل غير مهني.


