kernl
v0.2.2
Kernl vous permet d'exécuter des modèles de transformateur Pytorch plusieurs fois plus rapidement sur GPU avec une seule ligne de code, et est conçu pour être facilement piratable.
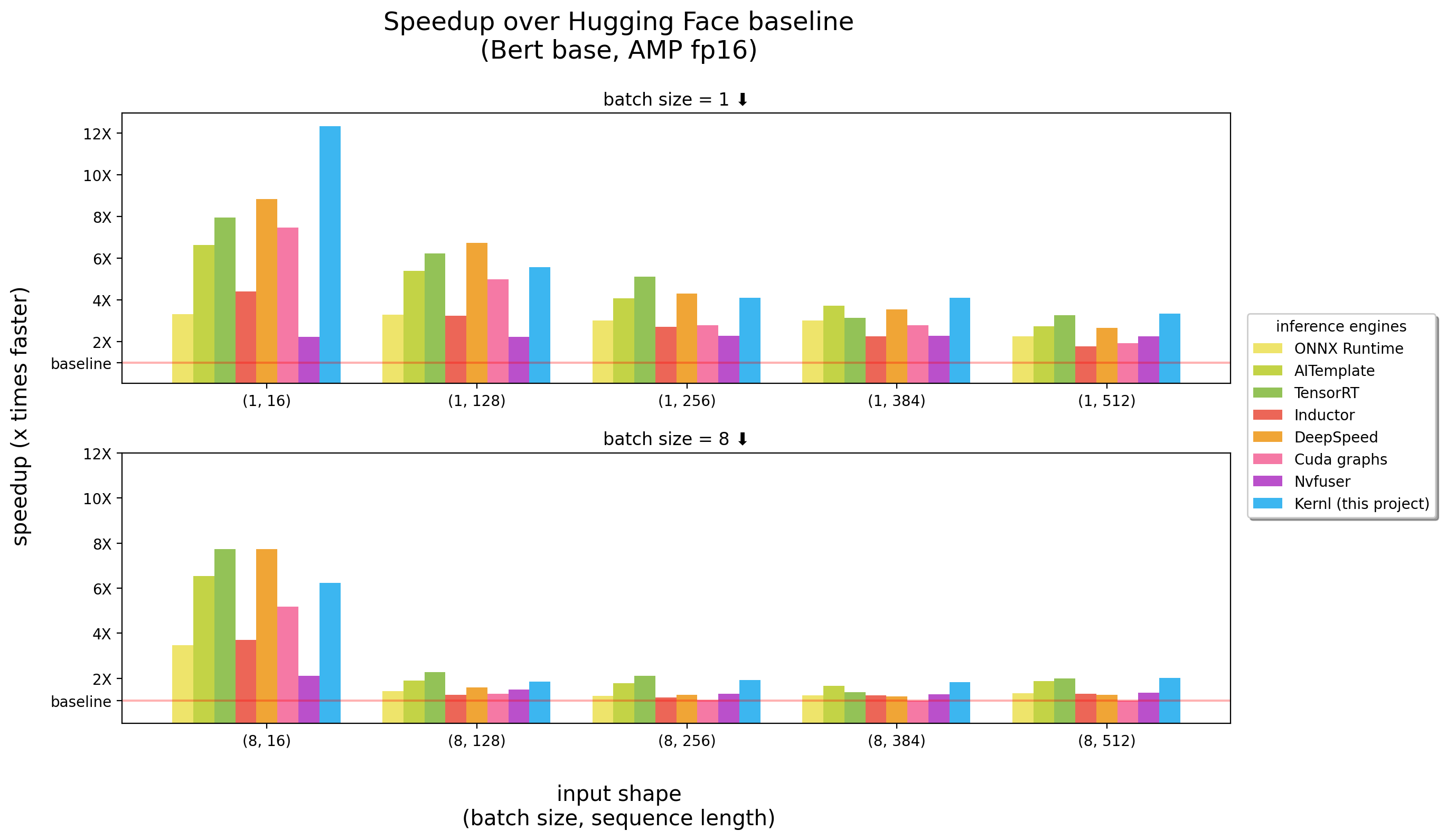
Benchmarks a couru sur un 3090 RTX
Kernl est le premier moteur d'inférence OSS écrit en Cuda c Openai Triton, une nouvelle langue conçue par Openai pour faciliter l'écriture des noyaux GPU.
Chaque noyau est inférieur à 200 lignes de code et est facile à comprendre et à modifier.
Une liste d'exemples contient comment utiliser Kernl avec pytorch.
| Sujet | Carnet de notes |
|---|---|
Matmul carrelé : implémentation de multiplication matricielle dans le style CUDA | lien |
| Matmul Offsets : Explications détaillées liées à une astuce de performance utilisée dans la mise en œuvre de Triton Matmul | lien |
Softmax en ligne : calcul de softmax parallélisé, un ingrédient clé de Flash Attention | lien |
Flash Attention : calcul de l'attention sans enregistrer la matrice d'attention à la mémoire globale | lien |
Classification XNLI : Classification avec / sans optimisations (tâche de classification Roberta + XNLI ) | lien |
Génération de texte : avec / sans optimisations ( T5 ) | lien |
Génération de transcription : avec / sans optimisations ( Whisper ) | lien |
| ** LLAMA Version 2 Optimisation par le noyau Fusion | lien |
IMPORTANT : Ce package nécessite l'installation pytorch .
Veuillez l'installer d'abord.
pip install ' git+https://github.com/ELS-RD/kernl '
# or for local dev, after git clone ...
pip install -e . Ce projet nécessite Python > = 3,9. De plus, la bibliothèque nécessite une installation d'un GPU et de CUDA.
Si vous préférez Docker :
# build
DOCKER_BUILDKIT=1 docker build -t kernl .
# run
docker run --rm -it --gpus all -v $( pwd ) :/kernl kernl import torch
from transformers import AutoModel
from kernl . model_optimization import optimize_model
model = AutoModel . from_pretrained ( "model_name" ). eval (). cuda ()
optimize_model ( model )
inputs = ...
with torch . inference_mode (), torch . cuda . amp . autocast ():
outputs = model ( ** inputs )Pour les cas d'utilisation de bout en bout, vous voudrez peut-être vérifier:
test_benchmark_implementation param # tada!
pytestIl y a plus de 2 000 repères, et ils mettent un certain temps à courir.
Certaines règles sur le fonctionnement PyTest , en particulier pour les repères:
-k pour filtrer les tests / repères par leur nom comme pytest -k benchmark pour exécuter uniquement les tests avec benchmark dans leur nompytest -k "benchmark and not bert" si vous voulez exécuter tous les repères sauf ceux liés à Bertpytest -k benchmark --benchmark-group-by ... :pytest -k benchmark --benchmark-group-by fullfuncpytest -k benchmark --benchmark-group-by param:implementation,param:shapeparam:x , x est le nom du paramètre dans @pytest.mark.parametrizepytest -k benchmark --benchmark-group-by fullfunc,param:implementation-s pour voir la sortie des tests (imprimer, etc.)-v pour voir la sortie verbale des tests AVERTISSEMENT : param:X fera un crash de Pytest si X n'est pas un paramètre d'au moins une des fonctions exécutées.
Quelques commandes utiles:
# only benchmarks
pytest -k benchmark
# no benchmarks
pytest -k " not benchmark "
# only linear layers benchmark, group by shape and if the input is contiguous or not
pytest test/test_linear_layer.py --benchmark-group-by fullfunc,param:shape,param:contiguous La première étape pour remplacer les appels de fonction / module dans le graphique consiste à créer le modèle qui sera remplacé. La façon la plus simple de le faire est de convertir le modèle en graphique FX, puis de l'imprimer avec utils.graph_report ou en imprimant le code print(you_graph_module.code)
Ensuite, vous pouvez utiliser Replace_Pattern pour remplacer le motif du graphique. Nous avons notre propre version de replace_pattern par quelques améliorations pour travailler avec des modules, par exemple. Vous pouvez en trouver des exemples dans le dossier optimizer .
Nous utilisons black / isort / flake8 pour formater le code. Vous pouvez les exécuter avec:
make source_code_format
make source_code_check_formatChez Lefebvre Sarrut, nous dirigeons plusieurs transformateurs en production, dont certains étant sensibles à la latence (recherche et Recsys principalement).
Nous utilisons onnxruntime et Tensorrt et avons même créé un déploiement de transformateur une bibliothèque OSS pour partager nos connaissances avec la communauté.
Récemment, nous testions des langues génératives et nous avons essayé de les accélérer. Cela s'avère très difficile avec les outils traditionnels.
Fondamentalement, et pour le faire court, il nous semble que ONNX (le format principal pour alimenter ces outils) est un format intéressant avec une prise en charge du matériel à large gamme.
Cependant, son écosystème (et principalement des moteurs d'inférence) a plusieurs limites lorsque nous traitons avec de nouvelles architectures LLM:
Une chose très ennuyeuse est le fait que les nouveaux modèles ne sont jamais accélérés, vous devez attendre que quelqu'un écrive des grains Cuda personnalisés pour cela.
Cela ne veut pas dire que les solutions sont mauvaises, une grande chose avec onnxruntime est son support multi-matériel.
En ce qui concerne Tensorrt, c'est vraiment rapide.
Nous voulions donc quelque chose d'aussi vite que Tensorrt et sur Python / Pytorch, c'est pourquoi nous avons construit Kernl.
La règle simple est que la bande passante de mémoire est souvent le goulot d'étranglement de l'apprentissage en profondeur, pour accélérer l'inférence, la réduction de l'accès à la mémoire est généralement une bonne stratégie. Sur la séquence d'entrée courte, le goulot d'étranglement est souvent lié à la surcharge du CPU, il doit également être supprimé. Contre-intuitivement, pour rendre les choses plus rapides, vous n'avez pas besoin d'être plus rapide dans le calcul.
Nous levons principalement de 3 technologies:
Openai Triton: C'est une langue pour écrire des noyaux GPU comme Cuda (à ne pas confondre avec le serveur d'inférence Nvidia Triton), mais beaucoup plus productif (du moins pour nous). L'amélioration est due à la fusion de plusieurs OP, ce qui nous rend capables de chaîner des calculs sans enregistrer des résultats intermédiaires dans la mémoire du GPU. Nous l'utilisons pour réécrire:
Graphiques CUDA: Vous avez peut-être entendu dire que Python est lent, Blablabla et pour limiter les frais généraux C ++ / Rust devrait être la solution. C'est vrai mais mieux que les frais généraux faibles ne sont pas du tout des frais généraux. Ce sont les graphiques Cuda! Au cours d'une étape d'échauffement, il sauvera chaque noyau lancé et leurs paramètres, puis, avec une seule instruction GPU, nous pouvons rejouer toute l'inférence.
TORCHDAMO: Ce prototype de Meta nous aide à faire face à un comportement dynamique. Il est décrit ici, et en quelques mots pendant une étape d'échauffement, il retrace le modèle et fournit un graphique FX (un graphique de calcul statique). Nous remplaçons certaines opérations de ce graphique par nos noyaux et le recompilt dans Python. Nous le faisons pour tout comportement dynamique possible que nous prévoyons avoir. Pendant l'inférence, les entrées sont analysées et le graphique statique correct est utilisé. C'est vraiment un projet génial, vérifiez leur dépôt pour en savoir plus.
Le code des noyaux Openai Triton s'inspire des exemples de tutoriels Openai Triton ou de la bibliothèque XFORMERS.
Si vous souhaitez contribuer, par exemple au code ou à la documentation, veuillez consulter notre guide de contribution.
Veuillez consulter notre code de conduite pour toutes les questions sur la communauté que nous essayons de construire et que faire si vous avez besoin d'aide avec quelqu'un qui agit de manière non professionnelle.


