kernl
v0.2.2
Kernl ช่วยให้คุณเรียกใช้รุ่น Pytorch Transformer ได้เร็วขึ้นหลายเท่าบน GPU ด้วยรหัสบรรทัดเดียว และได้รับการออกแบบให้แฮ็กได้ง่าย
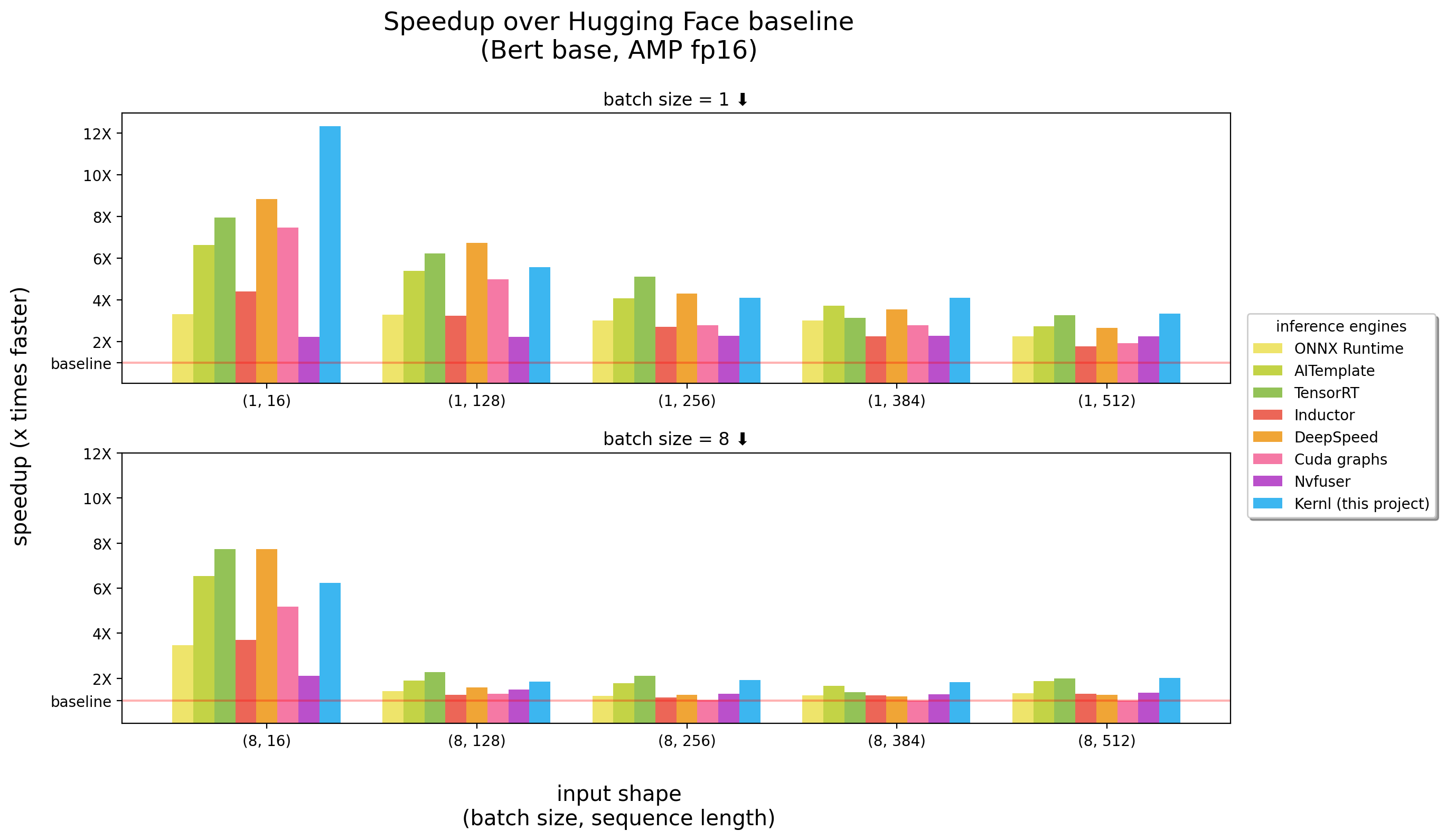
เกณฑ์มาตรฐานวิ่งบน 3090 RTX
Kernl เป็นเครื่องยนต์การอนุมาน OSS ตัวแรกที่เขียนขึ้น cuda c Openai Triton ซึ่งเป็นภาษาใหม่ที่ออกแบบโดย OpenAI เพื่อให้ง่ายต่อการเขียนเมล็ด GPU
เคอร์เนลแต่ละตัวมีรหัสน้อยกว่า 200 บรรทัดและ ง่ายต่อการเข้าใจ และแก้ไข
รายการตัวอย่างมีวิธีใช้ kernl กับ pytorch
| หัวข้อ | สมุดบันทึก |
|---|---|
Tiled Matmul : การเพิ่มการคูณเมทริกซ์ในสไตล์ CUDA | การเชื่อมโยง |
| Matmul Offsets : คำอธิบายโดยละเอียดที่เกี่ยวข้องกับเคล็ดลับประสิทธิภาพที่ใช้ในการใช้งาน Triton Matmul | การเชื่อมโยง |
softmax ออนไลน์ : การคำนวณ softmax แบบขนานซึ่งเป็นส่วนประกอบสำคัญของ Flash Attention | การเชื่อมโยง |
Flash Attention : การคำนวณความสนใจโดยไม่ต้องบันทึกเมทริกซ์ความสนใจไปยังหน่วยความจำทั่วโลก | การเชื่อมโยง |
การจำแนกประเภท XNLI : การจำแนกประเภทที่มี / ไม่มีการปรับให้เหมาะสม (งานการจำแนกประเภท Roberta + XNLI ) | การเชื่อมโยง |
การสร้างข้อความ : มี/ไม่มีการปรับให้เหมาะสม ( T5 ) | การเชื่อมโยง |
การสร้างการถอดความ : มี/ไม่มีการปรับให้เหมาะสม ( Whisper ) | การเชื่อมโยง |
| ** Llama เวอร์ชัน 2 การเพิ่มประสิทธิภาพโดยเคอร์เนลฟิวชั่น | การเชื่อมโยง |
สำคัญ : แพ็คเกจนี้ต้องมีการติดตั้ง pytorch
กรุณาติดตั้งก่อน
pip install ' git+https://github.com/ELS-RD/kernl '
# or for local dev, after git clone ...
pip install -e . โครงการนี้ต้องใช้ Python > = 3.9 นอกจากนี้ห้องสมุดต้องมีการติดตั้ง AMPERE GPU และ CUDA
หากคุณชอบ Docker :
# build
DOCKER_BUILDKIT=1 docker build -t kernl .
# run
docker run --rm -it --gpus all -v $( pwd ) :/kernl kernl import torch
from transformers import AutoModel
from kernl . model_optimization import optimize_model
model = AutoModel . from_pretrained ( "model_name" ). eval (). cuda ()
optimize_model ( model )
inputs = ...
with torch . inference_mode (), torch . cuda . amp . autocast ():
outputs = model ( ** inputs )สำหรับกรณีการใช้งานแบบ end-to-end คุณอาจต้องการตรวจสอบ:
test_benchmark_implementation เมื่อทำการเปรียบเทียบการดำเนินการเดียวกันโดยใช้กลยุทธ์ที่แตกต่างกัน # tada!
pytestมีมาตรฐานมากกว่า 2K และพวกเขาใช้เวลาสักครู่ในการวิ่ง
กฎบางอย่างเกี่ยวกับวิธีการทำงานของ PyTest โดยเฉพาะอย่างยิ่งสำหรับการวัดประสิทธิภาพ:
-k เพื่อกรองการทดสอบ/เกณฑ์มาตรฐานตามชื่อของพวกเขาเช่น pytest -k benchmark เพื่อเรียกใช้เฉพาะการทดสอบด้วย benchmark ในชื่อของพวกเขาpytest -k "benchmark and not bert" หากคุณต้องการเรียกใช้มาตรฐานทั้งหมดยกเว้นที่เกี่ยวข้องกับเบิร์ตpytest -k benchmark --benchmark-group-by ... ::pytest -k benchmark --benchmark-group-by fullfuncpytest -k benchmark --benchmark-group-by param:implementation,param:shapeparam:x , x เป็นชื่อพารามิเตอร์ใน @pytest.mark.parametrizepytest -k benchmark --benchmark-group-by fullfunc,param:implementation-s เพื่อดูผลลัพธ์ของการทดสอบ (พิมพ์ ฯลฯ )-v เพื่อดูเอาต์พุต verbose ของการทดสอบ คำเตือน : param:X จะทำให้การขัดข้อง pytest ถ้า X ไม่ใช่พารามิเตอร์ของฟังก์ชั่นอย่างน้อยหนึ่งฟังก์ชั่น
คำสั่งที่มีประโยชน์บางอย่าง:
# only benchmarks
pytest -k benchmark
# no benchmarks
pytest -k " not benchmark "
# only linear layers benchmark, group by shape and if the input is contiguous or not
pytest test/test_linear_layer.py --benchmark-group-by fullfunc,param:shape,param:contiguous ขั้นตอนแรกในการแทนที่การเรียกใช้ฟังก์ชัน/โมดูลในกราฟคือการสร้างรูปแบบที่จะถูกแทนที่ วิธีที่ง่ายที่สุดในการทำเช่นนี้คือการแปลงโมเดลเป็นกราฟ FX จากนั้นพิมพ์ด้วย utils.graph_report หรือพิมพ์รหัส print(you_graph_module.code)
จากนั้นคุณสามารถใช้ repong_pattern เพื่อแทนที่รูปแบบในกราฟ เรามีเวอร์ชันของตัวเองของตัวเองของ replace_pattern ที่มีการปรับปรุงบางอย่างเพื่อทำงานกับโมดูลตัวอย่างเช่น คุณสามารถค้นหาตัวอย่างของสิ่งนั้นในโฟลเดอร์ optimizer
เราใช้ black / isort / flake8 เพื่อจัดรูปแบบรหัส คุณสามารถเรียกใช้พวกเขาด้วย:
make source_code_format
make source_code_check_formatที่ Lefebvre Sarrut เราใช้หม้อแปลงหลายตัวในการผลิตบางส่วนมีความอ่อนไหวในเวลาแฝง (ค้นหาและ recsys ส่วนใหญ่)
เรากำลังใช้ onnxruntime และ tensorrt และแม้กระทั่งการสร้างหม้อแปลง deploy เป็นห้องสมุด OSS เพื่อแบ่งปันความรู้ของเรากับชุมชน
เมื่อเร็ว ๆ นี้เรากำลังทดสอบภาษากำเนิดและเราพยายามเร่งความเร็ว มันพิสูจน์ได้ยากมากด้วยเครื่องมือดั้งเดิม
โดยพื้นฐานแล้วและเพื่อให้สั้นดูเหมือนว่าเราจะ ONNX (รูปแบบหลักในการป้อนเครื่องมือเหล่านั้น) เป็นรูปแบบที่น่าสนใจพร้อมการรองรับฮาร์ดแวร์ที่หลากหลาย
อย่างไรก็ตามระบบนิเวศของมัน (และส่วนใหญ่เอ็นจิ้นการอนุมาน) มีข้อ จำกัด หลายประการเมื่อเราจัดการกับสถาปัตยกรรม LLM ใหม่:
สิ่งหนึ่งที่น่ารำคาญมากคือความจริงที่ว่ารุ่นใหม่ไม่เคยเร่งความเร็วคุณต้องรอให้ใครบางคนเขียนเมล็ด cuda ที่กำหนดเองสำหรับสิ่งนั้น
มันไม่ได้หมายความว่าวิธีแก้ปัญหาไม่ดีสิ่งหนึ่งที่ยิ่งใหญ่ที่มี onnxruntime คือการรองรับฮาร์ดแวร์ที่หลากหลาย
เกี่ยวกับ Tensorrt มันเร็วจริงๆ
ดังนั้นเราจึงต้องการบางสิ่งที่เร็วที่สุดเท่า Tensorrt และบน Python / Pytorch นั่นคือเหตุผลที่เราสร้าง Kernl
กฎง่ายๆคือแบนด์วิดท์หน่วยความจำมักจะเป็นคอขวดในการเรียนรู้อย่างลึกซึ้งเพื่อเร่งการอนุมานการลดการเข้าถึงหน่วยความจำมักเป็นกลยุทธ์ที่ดี ในลำดับการป้อนข้อมูลสั้น ๆ คอขวดมักเกี่ยวข้องกับค่าใช้จ่าย CPU จะต้องถูกลบออกเช่นกัน เพื่อให้สิ่งต่าง ๆ เร็วขึ้นคุณไม่จำเป็นต้องทำการคำนวณเร็วขึ้น
เราใช้ประโยชน์จากเทคโนโลยีส่วนใหญ่ 3 รายการ:
Openai Triton: เป็นภาษาที่เขียนเมล็ด GPU เช่น Cuda (ไม่ต้องสับสนกับเซิร์ฟเวอร์การอนุมาน Nvidia Triton) แต่มีประสิทธิผลมากขึ้น (อย่างน้อยสำหรับเรา) การปรับปรุงเกิดจากการหลอมรวมของ OPs หลายครั้งทำให้เราสามารถทำการคำนวณห่วงโซ่โดยไม่ต้องบันทึกผลลัพธ์ระดับกลางในหน่วยความจำ GPU เรากำลังใช้มันเพื่อเขียนใหม่:
กราฟ CUDA: คุณอาจเคยได้ยินว่า Python ช้า blablabla และเพื่อ จำกัด ค่าใช้จ่าย C ++/Rust ควรเป็นวิธีแก้ปัญหา มันเป็นความจริง แต่ดีกว่าค่าใช้จ่ายต่ำนั้นไม่มีค่าใช้จ่ายเลย นั่นคือกราฟ cuda! ในระหว่างขั้นตอนการอุ่นเครื่องมันจะบันทึกเคอร์เนลทุกชิ้นที่เปิดตัวและพารามิเตอร์ของพวกเขาจากนั้นด้วยคำสั่ง GPU เดียวเราสามารถเล่นซ้ำการอนุมานทั้งหมด
Torchdynamo: ต้นแบบนี้จาก Meta ช่วยให้เรารับมือกับพฤติกรรมแบบไดนามิก มันอธิบายไว้ที่นี่และในไม่กี่คำในระหว่างขั้นตอนการอุ่นเครื่องมันติดตามโมเดลและให้กราฟ FX (กราฟการคำนวณแบบคงที่) เราแทนที่การดำเนินการบางอย่างของกราฟนี้ด้วยเมล็ดของเราและคอมไพล์ใหม่ใน Python เราทำเช่นนั้นเพื่อพฤติกรรมแบบไดนามิกที่เป็นไปได้ที่เราคาดหวังว่าจะมี ในระหว่างการอนุมานอินพุตจะถูกวิเคราะห์และใช้กราฟคงที่ที่ถูกต้อง มันเป็นโครงการที่ยอดเยี่ยมจริงๆตรวจสอบ repo ของพวกเขาเพื่อรู้เพิ่มเติม
รหัสของ Openai Triton Kernels รับแรงบันดาลใจจากตัวอย่างจาก Openai Triton Tutorials หรือ Xformers Library
หากคุณต้องการมีส่วนร่วมตัวอย่างเช่นรหัสหรือเอกสารโปรดดูคู่มือการบริจาคของเรา
โปรดดูจรรยาบรรณของเราสำหรับคำถามใด ๆ เกี่ยวกับชุมชนที่เราพยายามสร้างและจะทำอย่างไรถ้าคุณต้องการความช่วยเหลือกับคนที่ทำหน้าที่อย่างไม่เป็นมืออาชีพ


