kernl
v0.2.2
Kernl позволяет запускать модели трансформаторов Pytorch несколько раз быстрее на графическом процессоре с одной строкой кода и предназначен для легко взлома.
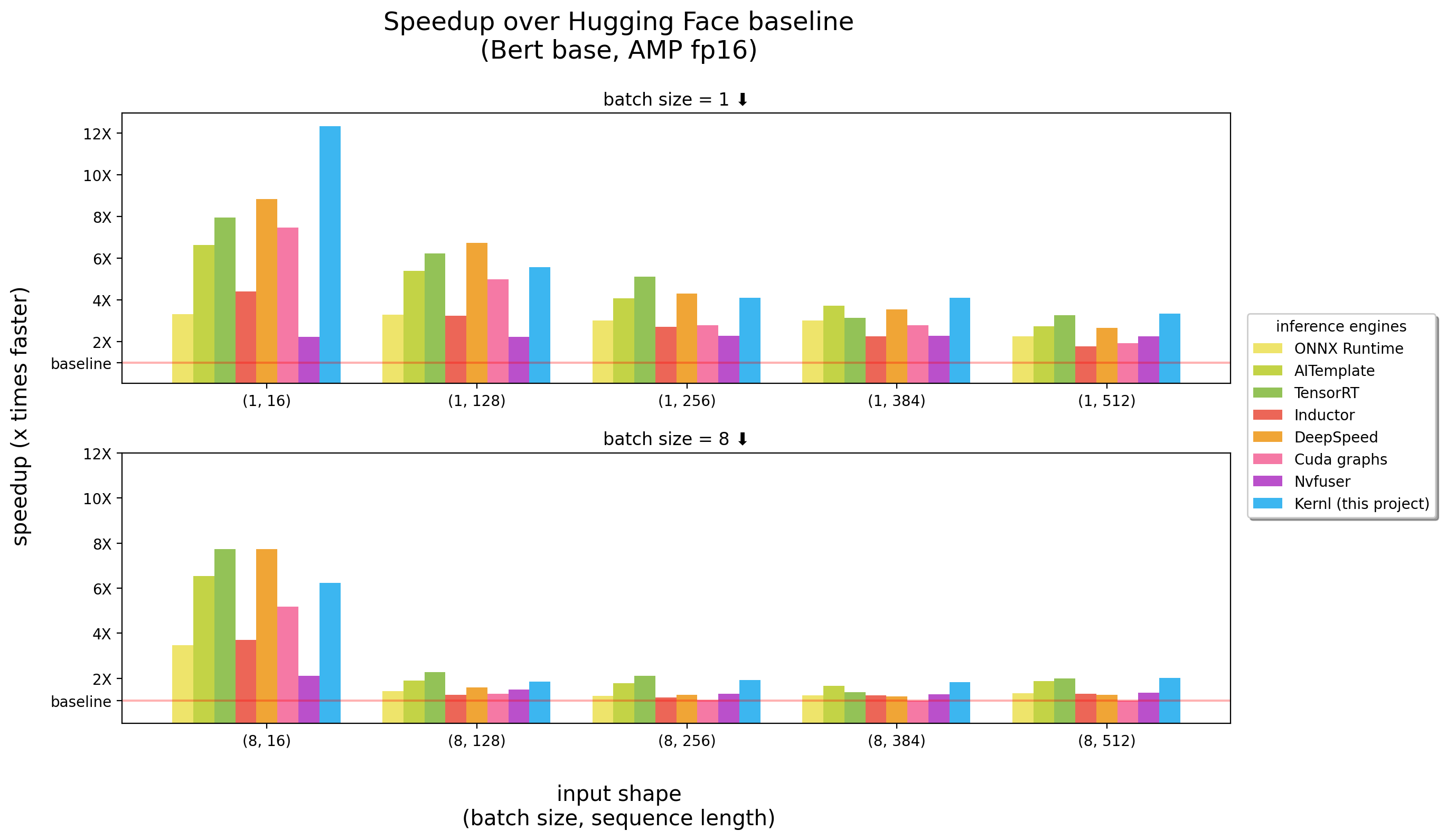
тесты бегали на 3090 RTX
Kernl - первый механизм вывода OSS, написанный в Cuda c Openai Triton, новый язык, разработанный Openai, чтобы облегчить писать ядра графического процессора.
Каждое ядро составляет менее 200 строк кода и легко понять и изменить.
Список примеров содержит, как использовать Kernl с Pytorch.
| Тема | Блокнот |
|---|---|
Шаренная мамул : реализация умножения матрицы в стиле CUDA | связь |
| Matmul смещения : подробные объяснения, связанные с трюком производительности, используемой в реализации Triton Matmul | связь |
Онлайн Softmax : параллелизированное вычисление Softmax, ключевой ингредиент Flash Attention | связь |
Flash Attention : вычисление внимания без сохранения матрицы внимания в глобальную память | связь |
Классификация XNLI : классификация с / без оптимизации (задача классификации Roberta + XNLI ) | связь |
Генерация текста : с/без оптимизации ( T5 ) | связь |
Генерация транскрипции : с/без оптимизации ( Whisper ) | связь |
| ** Llama версия 2 Оптимизация с помощью ядра Fusion | связь |
Важно : этот пакет требует установки pytorch .
Пожалуйста, установите его первым.
pip install ' git+https://github.com/ELS-RD/kernl '
# or for local dev, after git clone ...
pip install -e . Этот проект требует Python > = 3,9. Кроме того, библиотека требует установки графического процессора Ampere и CUDA.
Если вы предпочитаете Docker :
# build
DOCKER_BUILDKIT=1 docker build -t kernl .
# run
docker run --rm -it --gpus all -v $( pwd ) :/kernl kernl import torch
from transformers import AutoModel
from kernl . model_optimization import optimize_model
model = AutoModel . from_pretrained ( "model_name" ). eval (). cuda ()
optimize_model ( model )
inputs = ...
with torch . inference_mode (), torch . cuda . amp . autocast ():
outputs = model ( ** inputs )Для получения сквозных вариантов использования вы можете проверить:
test_benchmark_implementation при сравнительном сравнении одной и той же операции, используя различную стратегию # tada!
pytestСуществует более 2 тыс. Бессмы, и им нужно время, чтобы бежать.
Некоторые правила о том, как работает PyTest , в частности для критериев:
-k в фильтрование тестов/тестов по их названию, как pytest -k benchmark чтобы запустить только тесты с benchmark на их названиеpytest -k "benchmark and not bert" если вы хотите запустить все тесты, кроме тех, которые связаны с Бертомpytest -k benchmark --benchmark-group-by ... :pytest -k benchmark --benchmark-group-by fullfuncpytest -k benchmark --benchmark-group-by param:implementation,param:shapeparam:x , x - имя параметра в @pytest.mark.parametrizepytest -k benchmark --benchmark-group-by fullfunc,param:implementation-s , чтобы увидеть вывод тестов (печать и т. Д.)-v , чтобы увидеть многословный выход тестов ПРЕДУПРЕЖДЕНИЕ : param:X сделает Pytest Crash, если X не является параметром, по крайней мере, одной из выполнений функции.
Некоторые полезные команды:
# only benchmarks
pytest -k benchmark
# no benchmarks
pytest -k " not benchmark "
# only linear layers benchmark, group by shape and if the input is contiguous or not
pytest test/test_linear_layer.py --benchmark-group-by fullfunc,param:shape,param:contiguous Первый шаг для замены вызовов функции/модулей на графике - создать шаблон, который будет заменен. Самый простой способ сделать это - преобразовать модель в график FX, а затем распечатать ее с помощью utils.graph_report или print(you_graph_module.code)
Затем вы можете использовать replace_pattern, чтобы заменить шаблон на графике. У нас есть собственная версия replace_pattern с некоторыми улучшениями для работы с модулями, например. Вы можете найти примеры этого в папке optimizer .
Мы используем black / isort / flake8 для форматирования кода. Вы можете запустить их с:
make source_code_format
make source_code_check_formatВ Lefebvre Sarrut мы управляем несколькими трансформаторами в производстве, некоторые из которых являются чувствительными к задержке (в основном поиск и перерывы).
Мы используем Onnxruntime и Tensorrt и даже создали Transformer-Deploy библиотеку OSS, чтобы поделиться своими знаниями с сообществом.
Недавно мы тестировали генеративные языки, и мы пытались ускорить их. Это очень сложно с традиционными инструментами.
По сути, и сделать это коротким, нам кажется, что ONNX (основной формат для подачи этих инструментов) является интересным форматом с широким диапазоном поддержки аппаратного обеспечения.
Тем не менее, его экосистема (и в основном двигатели вывода) имеет несколько ограничений, когда мы имеем дело с новыми архитектурами LLM:
Одна вещь очень раздражает тот факт, что новые модели никогда не ускоряются, вам нужно подождать, пока кто -то напишет для этого пользовательские ядра Cuda.
Нельзя сказать, что решения плохие, одна важная вещь с Onnxruntime - это его многоуниверситетская поддержка.
Что касается Tensorrt, это действительно быстро.
Таким образом, мы хотели что -то так быстро, как Tensorrt и на Python / Pytorch, поэтому мы построили Kernl.
Простое правило заключается в том, что пропускная способность памяти часто является узким местом в глубоком обучении, для ускорения вывода, уменьшение доступа к памяти обычно является хорошей стратегией. На короткой входной последовательности узкое место часто связано с накладными расходами на ЦП, его также нужно удалить. Противостоятельно, чтобы сделать вещи быстрее, вам не нужно быть быстрее в вычислениях.
Мы используем в основном 3 технологии:
Openai Triton: Это язык для написания ядра графических процессоров, таких как CUDA (не путать с сервером вывода Nvidia Triton), но гораздо более продуктивным (по крайней мере для нас). Улучшение обусловлено слиянием нескольких OPS, что делает нас способными к цепным вычислениям без сохранения промежуточных результатов в памяти графических процессоров. Мы используем это для переписывания:
Графики CUDA: Возможно, вы слышали, что Python медленный, Blablabla и ограничение накладных расходов C ++/ржавчина должно быть решением. Это правда, но лучше, чем низкие накладные расходы, вообще не накладные расходы. Это графики CUDA! Во время шага разминки он спасет каждое запуск ядра и их параметры, а затем, с одной инструкцией GPU, мы можем воспроизвести весь вывод.
TOCHDYNAMO: Этот прототип от Meta помогает нам справиться с динамическим поведением. Он описан здесь, и в нескольких словах во время шага разминки он прослеживает модель и обеспечивает график FX (график статического вычисления). Мы заменяем некоторые операции этого графика нашими ядрами и перекомпилируем его в Python. Мы делаем это для любого возможного динамического поведения, которое мы ожидаем. Во время вывода анализируются входы, и используется правильный статический график. Это действительно потрясающий проект, проверьте их репо, чтобы узнать больше.
Код Openai Triton ядра черпает вдохновение из примеров из учебных пособий Openai Triton или библиотеки Xformers.
Если вы хотите внести свой вклад, например, в код или документацию, см. Наше руководство по взносу.
Пожалуйста, обратитесь к нашему кодексу поведения по любым вопросам о сообществе, которое мы пытаемся создать и что делать, если вам нужна помощь с кем -то, кто действует непрофессионально.


