kernl
v0.2.2
KERNL可让您使用单行代码在GPU上几次运行Pytorch Transformer模型,并且设计为易于黑客入侵。
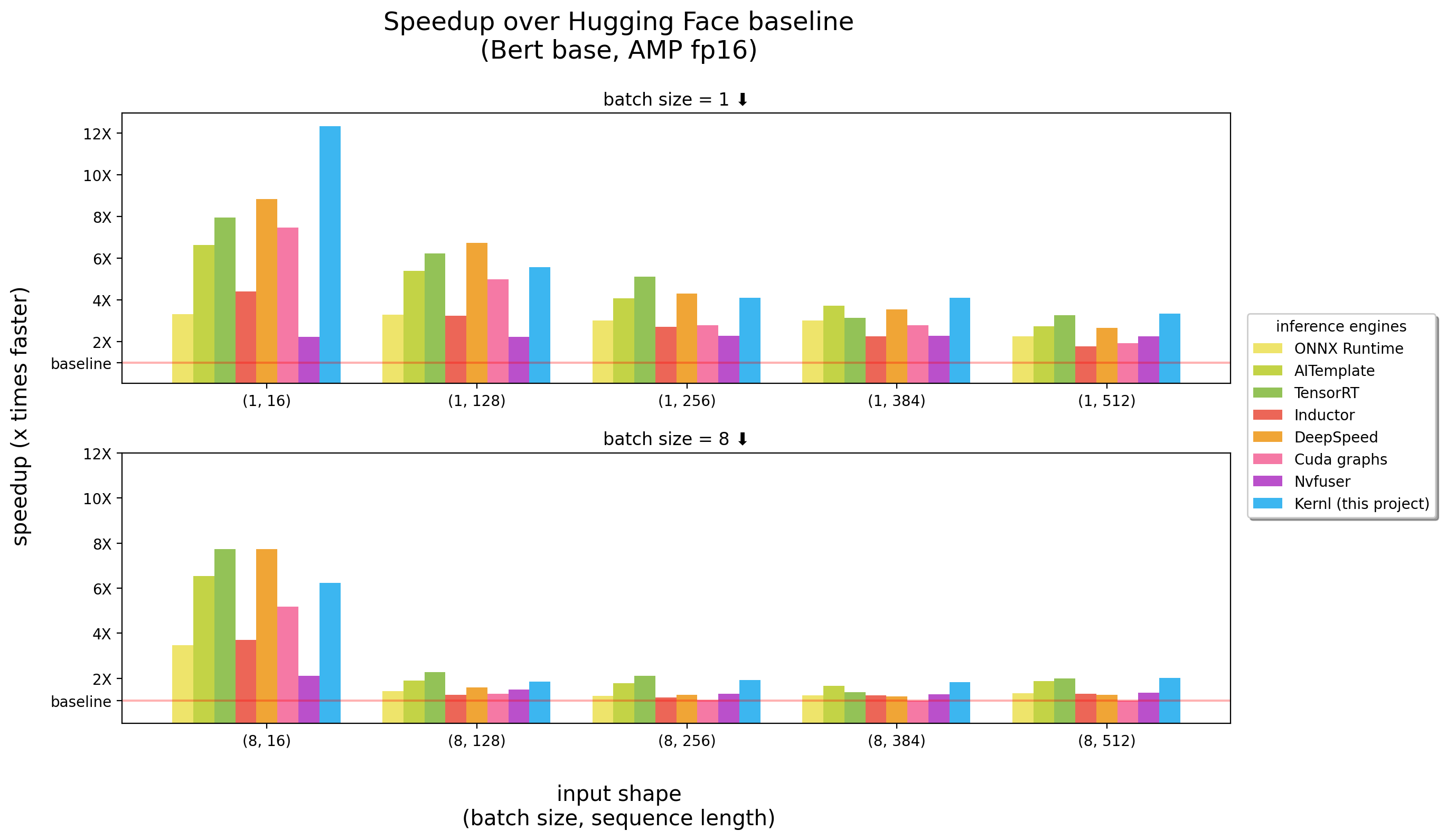
基准在3090 RTX上运行
Kernl是第一个写的推理引擎cuda c Openai Triton,由Openai设计的一种新语言,旨在使编写GPU内核变得更容易。
每个内核的代码少于200行,并且易于理解和修改。
示例列表包含如何将Kernl与Pytorch一起使用。
| 话题 | 笔记本 |
|---|---|
瓷砖matmul :以CUDA样式的矩阵乘法实现 | 关联 |
| MatMul偏移:与Triton Matmul实现中使用的性能技巧有关的详细说明 | 关联 |
在线SoftMax :并行的软磁计算, Flash Attention的关键要素 | 关联 |
Flash Attention :注意计算而无需将注意力矩阵保存到全球内存 | 关联 |
XNLI分类:具有 /没有优化的分类( Roberta + XNLI分类任务) | 关联 |
文本生成:具有/没有优化( T5 ) | 关联 |
转录生成:没有/没有优化( Whisper ) | 关联 |
| ** Llama版本2优化内核融合 | 关联 |
重要的是:此软件包需要安装pytorch 。
请先安装。
pip install ' git+https://github.com/ELS-RD/kernl '
# or for local dev, after git clone ...
pip install -e .该项目需要Python > = 3.9。此外,库需要安装安培的GPU和CUDA。
如果您喜欢Docker :
# build
DOCKER_BUILDKIT=1 docker build -t kernl .
# run
docker run --rm -it --gpus all -v $( pwd ) :/kernl kernl import torch
from transformers import AutoModel
from kernl . model_optimization import optimize_model
model = AutoModel . from_pretrained ( "model_name" ). eval (). cuda ()
optimize_model ( model )
inputs = ...
with torch . inference_mode (), torch . cuda . amp . autocast ():
outputs = model ( ** inputs )对于端到端用例,您可能需要检查:
test_benchmark_开头的名称implementation参数 # tada!
pytest有超过2k的基准测试,它们需要一段时间才能运行。
关于PyTest工作原理的一些规则,特别是对于基准:
-k添加到过滤器测试/基准测试名称(例如pytest -k benchmark ,以仅以其名称运行benchmark测试pytest -k "benchmark and not bert"如果要运行所有基准测试,除了与bert相关的基准之外pytest -k benchmark --benchmark-group-by ... ::pytest -k benchmark --benchmark-group-by fullfuncpytest -k benchmark --benchmark-group-by param:implementation,param:shapeparam:x , x是@pytest.mark.parametrize中的参数名称pytest -k benchmark --benchmark-group-by fullfunc,param:implementation-s查看测试的输出(打印等)-v要查看测试的详细输出警告: param:X如果X不是至少一个函数ran的参数,则X会造成Pytest崩溃。
一些有用的命令:
# only benchmarks
pytest -k benchmark
# no benchmarks
pytest -k " not benchmark "
# only linear layers benchmark, group by shape and if the input is contiguous or not
pytest test/test_linear_layer.py --benchmark-group-by fullfunc,param:shape,param:contiguous图表中替换功能/模块调用的第一步是创建将要替换的模式。最简单的方法是将模型转换为FX图,然后使用utils.graph_report或通过打印代码打印print(you_graph_module.code)将其打印出来。
然后,您可以使用repent_pattern替换图中的模式。例如,我们拥有自己的replace_pattern版本,并具有一些可与模块一起使用的增强功能。您可以在optimizer文件夹中找到该示例。
我们使用black / isort / flake8格式化代码。您可以运行它们:
make source_code_format
make source_code_check_format在Lefebvre Sarrut,我们在生产中运行了几个变压器,其中一些是延迟敏感的(主要是搜索和收获)。
我们正在使用Onnxruntime和Tensorrt,甚至创建了Transformer-Deploy一个OSS库与社区分享我们的知识。
最近,我们正在测试生成语言,并试图加速它们。传统工具证明这很困难。
基本上,简而言之,在我们看来,Onnx(喂养这些工具的主要格式)是一种有趣的格式,具有对硬件的广泛支持。
但是,当我们处理新的LLM体系结构时,其生态系统(和主要是推理引擎)有一些局限性:
非常烦人的一件事是,新模型永远不会加速,您需要等待某人为此编写自定义CUDA内核。
并不是说解决方案很糟糕,OnnxRuntime的一件大事是其多硬件支持。
关于张力,这真的很快。
因此,我们想要像Tensorrt和Python / Pytorch一样快的东西,这就是我们建造Kernl的原因。
简单的规则是,内存带宽通常是深度学习中的瓶颈,为了加速推断,减少内存访问通常是一个很好的策略。简而言之,瓶颈通常与CPU开销有关,也必须将其删除。违反直觉,为了使事情更快,您无需更快地计算。
我们主要利用3种技术:
Openai Triton:这是一种编写诸如CUDA之类的GPU内核的语言(不要与Nvidia Triton推理服务器相混淆),但生产力更高(至少对我们来说)。改进是由于多个操作的融合,使我们能够链接计算而无需保存中间结果在GPU内存中。我们正在使用它来重写:
CUDA图:您可能已经听说Python很慢,Blablabla且限制开销的C ++/Rust应该是解决方案。这是真的,但比低顶的开销更好。那是库达图!在热身步骤中,它将节省每个内核及其参数,然后通过单个GPU指示,我们可以重新推断整个推断。
Torchdynamo:该原型来自META,有助于我们应对动态行为。它在此处进行了描述,在热身步骤中用几句话可以追踪模型并提供FX图(静态计算图)。我们用我们的内核代替了该图的某些操作,并将其重新编译为Python。我们为我们期望拥有的任何可能的动态行为做到这一点。在推论过程中,分析输入,并使用正确的静态图。这确实是一个很棒的项目,请检查他们的回购以了解更多。
Openai Triton内核代码从OpenAI Triton教程或Xformers库中的示例中汲取灵感。
如果您想为代码或文档做出贡献,请参阅我们的贡献指南。
有关我们要建立的社区的任何疑问,请参阅我们的行为守则,如果您需要与非专业行为的人需要帮助,该怎么办。


