kernl
v0.2.2
Kernl permite executar modelos de transformador Pytorch várias vezes mais rápido na GPU com uma única linha de código e foi projetado para ser facilmente hackeável.
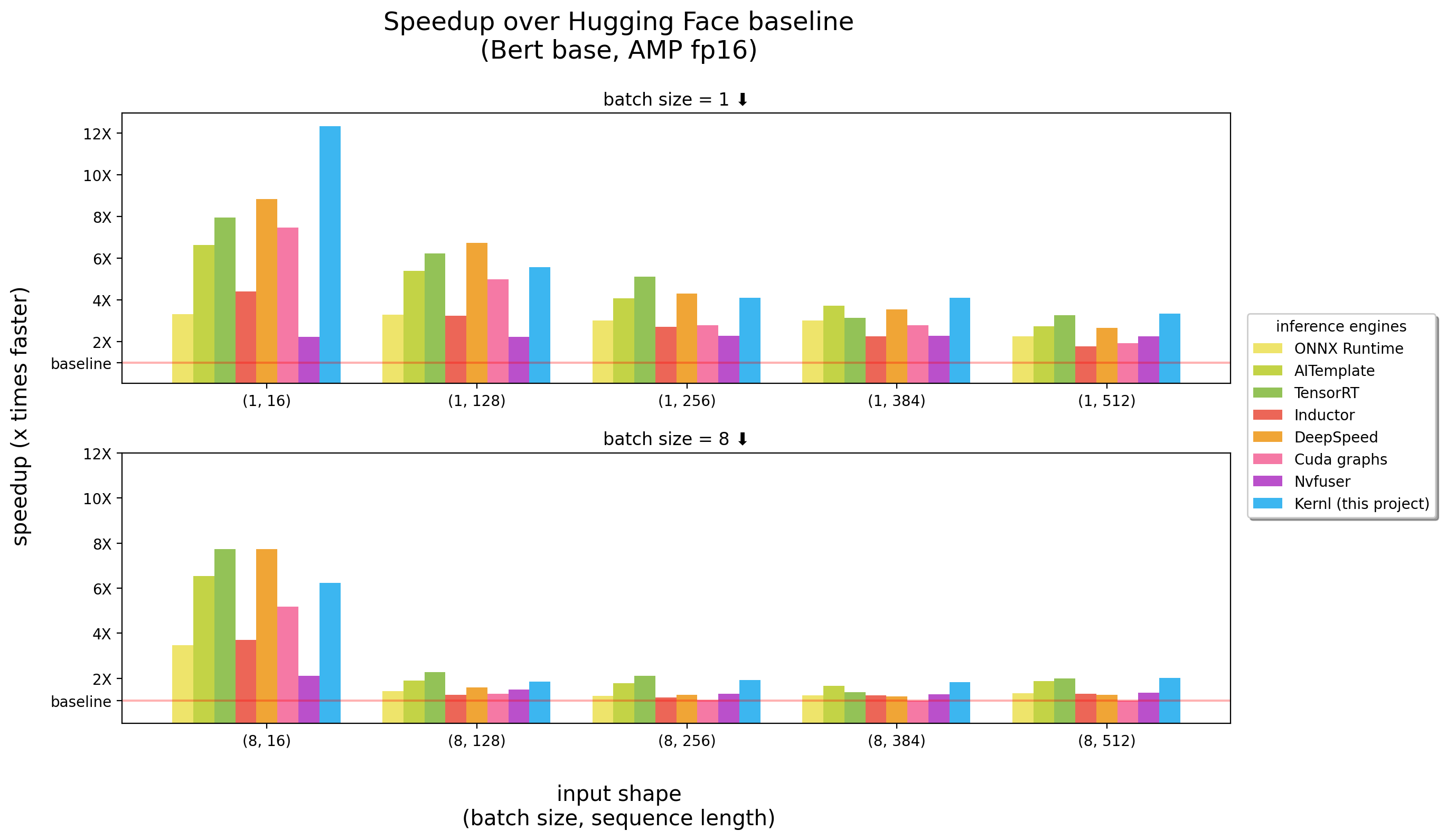
Os benchmarks foram executados em um 3090 RTX
Kernl é o primeiro mecanismo de inferência de OSS escrito em Cuda c Openai Triton, um novo idioma projetado pelo OpenAI para facilitar a redação de kernels da GPU.
Cada kernel tem menos de 200 linhas de código e é fácil de entender e modificar.
Uma lista de exemplos contém como usar o Kernl com Pytorch.
| Tópico | Caderno |
|---|---|
Matmul de azulejos : implementação de multiplicação de matrizes no estilo CUDA | link |
| Compensações de Matmul : explicações detalhadas relacionadas a um truque de desempenho usado na implementação de Triton Matmul | link |
Online Softmax : Computação Softmax paralela, um ingrediente -chave da Flash Attention | link |
Flash Attention : Atenção Computação sem economizar a Matriz de Atenção para a Memória Global | link |
CLASSIFICAÇÃO XNLI : Classificação com / sem otimizações ( Roberta + XNLI Classification Task) | link |
Geração de texto : com/sem otimizações ( T5 ) | link |
Geração de transcrição : com/sem otimizações ( Whisper ) | link |
| ** LLAMA VERSÃO 2 Otimização por fusão do kernel | link |
IMPORTANTE : Este pacote exige que pytorch seja instalado.
Por favor, instale -o primeiro.
pip install ' git+https://github.com/ELS-RD/kernl '
# or for local dev, after git clone ...
pip install -e . Este projeto requer Python > = 3.9. Além disso, a biblioteca exige que uma GPU e CUDA sejam instalados.
Se você preferir Docker :
# build
DOCKER_BUILDKIT=1 docker build -t kernl .
# run
docker run --rm -it --gpus all -v $( pwd ) :/kernl kernl import torch
from transformers import AutoModel
from kernl . model_optimization import optimize_model
model = AutoModel . from_pretrained ( "model_name" ). eval (). cuda ()
optimize_model ( model )
inputs = ...
with torch . inference_mode (), torch . cuda . amp . autocast ():
outputs = model ( ** inputs )Para casos de uso de ponta a ponta, convém verificar:
test_benchmark_implementation ao realizar a mesma operação usando estratégia diferente # tada!
pytestExistem mais de 2K de referência e eles demoram um pouco para correr.
Algumas regras sobre como PyTest funciona, em particular para benchmarks:
-k aos testes de filtro/benchmarks por seu nome como pytest -k benchmark para executar apenas testes com benchmark em seu nomepytest -k "benchmark and not bert" se quiser executar todos os benchmarks, exceto aqueles relacionados a Bertpytest -k benchmark --benchmark-group-by ... :pytest -k benchmark --benchmark-group-by fullfuncpytest -k benchmark --benchmark-group-by param:implementation,param:shapeparam:x , x é o nome do parâmetro em @pytest.mark.parametrizepytest -k benchmark --benchmark-group-by fullfunc,param:implementation-s para ver a saída dos testes (impressão, etc.)-v para ver a saída detalhada dos testes Aviso : param:X fará com que o pytest falhe se X não for um parâmetro de pelo menos uma das funções executadas.
Alguns comandos úteis:
# only benchmarks
pytest -k benchmark
# no benchmarks
pytest -k " not benchmark "
# only linear layers benchmark, group by shape and if the input is contiguous or not
pytest test/test_linear_layer.py --benchmark-group-by fullfunc,param:shape,param:contiguous A primeira etapa para substituir chamadas de função/módulo no gráfico é criar o padrão que será substituído. A maneira mais fácil de fazer isso é converter o modelo em um gráfico de FX e, em seguida, imprimi -lo com utils.graph_report ou imprimindo a print(you_graph_module.code)
Em seguida, você pode usar o substituto_pattern para substituir o padrão no gráfico. Temos nossa própria versão do replace_pattern com alguns aprimoramentos para trabalhar com módulos, por exemplo. Você pode encontrar exemplos disso na pasta optimizer .
Usamos black / isort / flake8 para formatar o código. Você pode executá -los com:
make source_code_format
make source_code_check_formatNo Lefebvre Sarrut, executamos vários transformadores na produção, alguns deles são sensíveis à latência (pesquisa e pesquisa principalmente).
Estamos usando o OnnxRuntime e o Tensorrt e até criamos o transformador de uma biblioteca OSS para compartilhar nosso conhecimento com a comunidade.
Recentemente, estávamos testando idiomas generativos e tentamos acelerá -los. Isso é muito difícil com as ferramentas tradicionais.
Basicamente, e para diminuir, parece -nos que o ONNX (o formato principal para alimentar essas ferramentas) é um formato interessante com um amplo suporte de hardware.
No entanto, seu ecossistema (e principalmente mecanismos de inferência) tem várias limitações quando lidamos com novas arquiteturas LLM:
Uma coisa muito irritante é o fato de que novos modelos nunca são acelerados, você precisa esperar alguém para escrever kernels personalizados para isso.
Não quer dizer que as soluções sejam ruins, uma coisa importante com o OnnxRuntime é seu suporte a vários hardware.
Em relação a Tensorrt, é muito rápido.
Então, queríamos algo tão rápido quanto Tensorrt e Python / Pytorch, é por isso que construímos Kernl.
A regra simples é que a largura de banda da memória geralmente é o gargalo no aprendizado profundo, para acelerar a inferência, a redução do acesso à memória geralmente é uma boa estratégia. Na sequência de entrada curta, o gargalo está frequentemente relacionado à sobrecarga da CPU, ela também deve ser removida. Contra -intuitivamente, para tornar as coisas mais rápidas, você não precisa ser mais rápido na computação.
Aproveitamos principalmente 3 tecnologias:
Openai Triton: É um idioma escrever kernels de GPU como Cuda (não deve ser confundido com o Nvidia Triton Inference Server), mas muito mais produtivo (pelo menos para nós). A melhoria se deve à fusão de várias OPs, tornando -nos capazes de encadear cálculos sem salvar resultados intermediários na memória da GPU. Estamos usando -o para reescrever:
Gráficos de CUDA: Você deve ter ouvido saber que o Python é lento, Blablabla e limitar a sobrecarga C ++/ferrugem deve ser a solução. É verdade, mas melhor que a baixa sobrecarga não é uma sobrecarga. São gráficos CUDA! Durante uma etapa de aquecimento, ele salvará todos os kernels lançados e seus parâmetros e, com uma única instrução de GPU, podemos reproduzir toda a inferência.
Torchdynamo: Este protótipo da Meta nos ajuda a lidar com o comportamento dinâmico. É descrito aqui e, em poucas palavras, durante uma etapa de aquecimento, traça o modelo e fornece um gráfico de FX (um gráfico de computação estática). Substituímos algumas operações deste gráfico por nossos kernels e o recompilamos no Python. Fazemos isso para qualquer comportamento dinâmico possível que esperamos ter. Durante a inferência, as entradas são analisadas e o gráfico estático correto é usado. É realmente um projeto incrível, verifique o repositório deles para saber mais.
Código de Kernels Triton Openai se inspira em exemplos da Openai Triton Tutoriais ou da Biblioteca Xformers.
Se você deseja contribuir, por exemplo, para codificar ou documentação, consulte nosso guia de contribuição.
Consulte nosso Código de Conduta para qualquer dúvida sobre a comunidade que estamos tentando construir e o que fazer se precisar de ajuda com alguém que está agindo de maneira não profissional.


