kernl
v0.2.2
Kernl le permite ejecutar modelos de transformador Pytorch varias veces más rápido en GPU con una sola línea de código, y está diseñado para ser fácilmente pirateable.
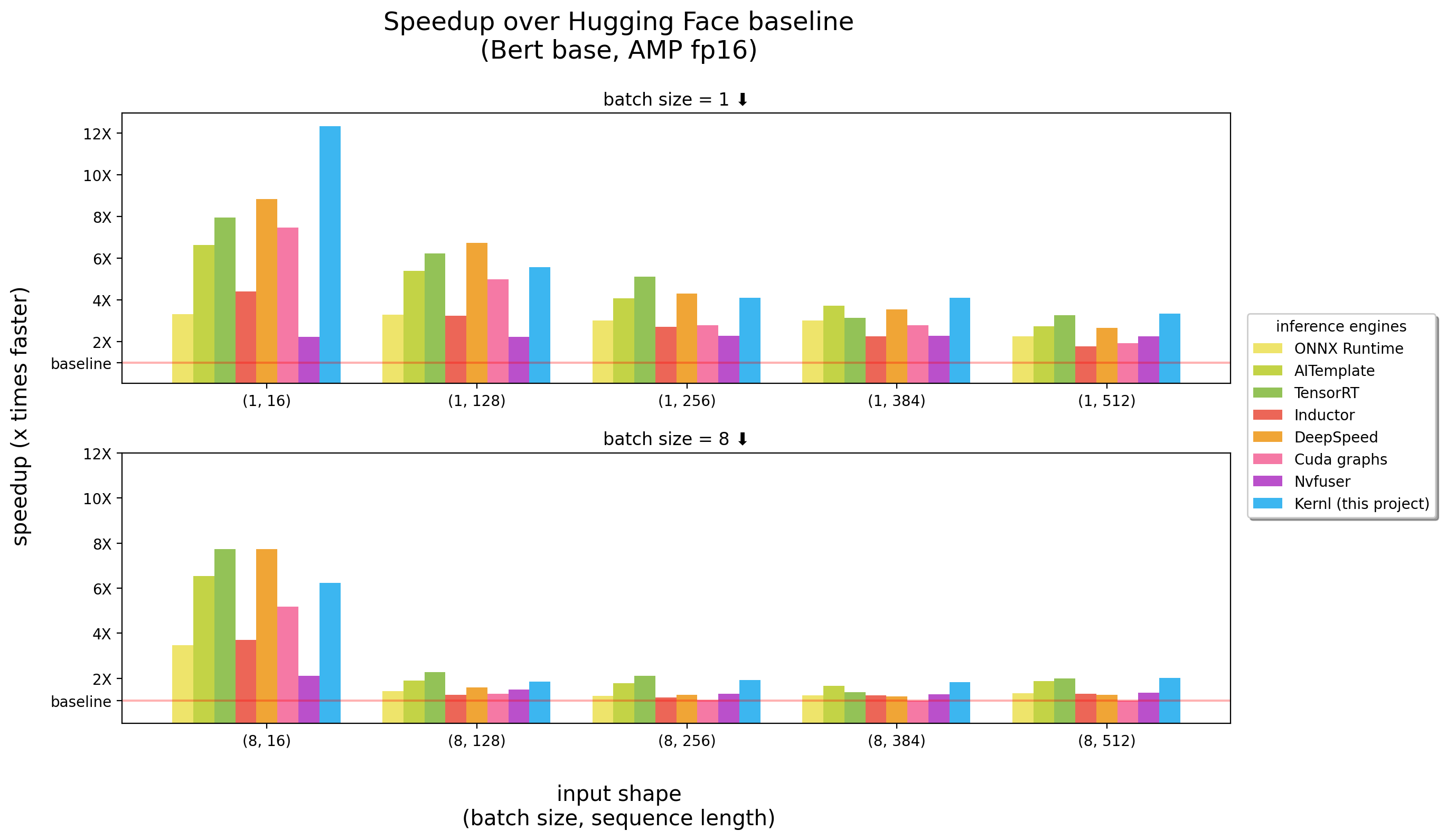
Los puntos de referencia se ejecutaron en un 3090 RTX
Kernl es el primer motor de inferencia OSS escrito en CUDA C Openai Triton, un nuevo idioma diseñado por OpenAI para facilitar la escritura de los núcleos GPU.
Cada núcleo tiene menos de 200 líneas de código, y es fácil de entender y modificar.
Una lista de ejemplos contiene cómo usar kernl con pytorch.
| Tema | Computadora portátil |
|---|---|
Malicada Matmul : Implementación de multiplicación de matriz en estilo CUDA | enlace |
| Offsets de Matmul : explicaciones detalladas relacionadas con un truco de rendimiento utilizado en la implementación de Triton Matmul | enlace |
Softmax en línea : computación softmax paralelo, un ingrediente clave de Flash Attention | enlace |
Flash Attention : Computación de atención sin guardar la matriz de atención a la memoria global | enlace |
Clasificación XNLI : Clasificación con / sin optimizaciones (Tarea de clasificación Roberta + XNLI ) | enlace |
Generación de texto : con/sin optimizaciones ( T5 ) | enlace |
Generación de transcripción : con/sin optimizaciones ( Whisper ) | enlace |
| ** Llama Versión 2 Optimización de Kernel Fusion | enlace |
IMPORTANTE : Este paquete requiere que se esté instalando pytorch .
Instálelo primero.
pip install ' git+https://github.com/ELS-RD/kernl '
# or for local dev, after git clone ...
pip install -e . Este proyecto requiere Python > = 3.9. Además, la biblioteca requiere que se instalen una GPU y CUDA de Ampere.
Si prefiere Docker :
# build
DOCKER_BUILDKIT=1 docker build -t kernl .
# run
docker run --rm -it --gpus all -v $( pwd ) :/kernl kernl import torch
from transformers import AutoModel
from kernl . model_optimization import optimize_model
model = AutoModel . from_pretrained ( "model_name" ). eval (). cuda ()
optimize_model ( model )
inputs = ...
with torch . inference_mode (), torch . cuda . amp . autocast ():
outputs = model ( ** inputs )Para casos de uso de extremo a extremo, es posible que desee verificar:
test_benchmark_implementation al evaluar la misma operación utilizando una estrategia diferente # tada!
pytestHay más de 2k puntos de referencia, y tardan un tiempo en correr.
Algunas reglas sobre cómo funciona PyTest , en particular para puntos de referencia:
-k para filtrar pruebas/puntos de referencia por su nombre como pytest -k benchmark para ejecutar solo las pruebas con benchmark en su nombrepytest -k "benchmark and not bert" si desea ejecutar todos los puntos de referencia, excepto los relacionados con Bertpytest -k benchmark --benchmark-group-by ... :pytest -k benchmark --benchmark-group-by fullfuncpytest -k benchmark --benchmark-group-by param:implementation,param:shapeparam:x , x es el nombre del parámetro en @pytest.mark.parametrizepytest -k benchmark --benchmark-group-by fullfunc,param:implementation-s para ver la salida de las pruebas (imprimir, etc.)-v para ver la salida detallada de las pruebas ADVERTENCIA : param:X hará que Pytest se bloquee si X no es un parámetro de al menos una de las funciones ejecutadas.
Algunos comandos útiles:
# only benchmarks
pytest -k benchmark
# no benchmarks
pytest -k " not benchmark "
# only linear layers benchmark, group by shape and if the input is contiguous or not
pytest test/test_linear_layer.py --benchmark-group-by fullfunc,param:shape,param:contiguous El primer paso para reemplazar las llamadas de función/módulo en el gráfico es crear el patrón que se reemplazará. La forma más fácil de hacer esto es convertir el modelo en un gráfico FX, y luego imprimirlo con utils.graph_report o imprimir el código print(you_graph_module.code)
Luego puede usar reemplazar_pattern para reemplazar el patrón en el gráfico. Tenemos nuestra propia versión de replace_pattern con algunas mejoras para funcionar con módulos, por ejemplo. Puede encontrar ejemplos de eso en la carpeta optimizer .
Usamos black / isort / flake8 para formatear el código. Puedes ejecutarlos con:
make source_code_format
make source_code_check_formatEn Lefebvre Sarrut, ejecutamos varios transformadores en producción, algunos de ellos son sensibles a la latencia (búsqueda y recsys principalmente).
Estamos utilizando onnxruntime y tensorrt e incluso creamos Transformer-Deploy una biblioteca OSS para compartir nuestro conocimiento con la comunidad.
Recientemente, estábamos probando idiomas generativos e intentamos acelerarlos. Resulta muy difícil con las herramientas tradicionales.
Básicamente, y para hacerlo corto, nos parece que ONNX (el formato principal para alimentar esas herramientas) es un formato interesante con un amplio soporte de hardware.
Sin embargo, su ecosistema (y en su mayoría motores de inferencia) tiene varias limitaciones cuando tratamos con nuevas arquitecturas LLM:
Una cosa muy molesta es el hecho de que los nuevos modelos nunca se aceleran, debe esperar a que alguien escriba núcleos CUDA personalizados para eso.
No quiere decir que las soluciones son malas, una gran cosa con Onnxruntime es su soporte de hardware múltiple.
En cuanto a Tensorrt, es realmente rápido.
Así que queríamos algo tan rápido como Tensorrt y en Python / Pytorch, por eso construimos Kernl.
La regla simple es que el ancho de banda de memoria es a menudo el cuello de botella en el aprendizaje profundo, para acelerar la inferencia, la reducción del acceso a la memoria suele ser una buena estrategia. En una secuencia de entrada corta, el cuello de botella a menudo está relacionado con la sobrecarga de la CPU, también debe eliminarse. Contraintuitivamente, para hacer las cosas más rápido, no necesita ser más rápido en el cálculo.
Aprovechamos principalmente 3 tecnologías:
OPERAI TRITON: Es un idioma para escribir núcleos de GPU como CUDA (que no debe confundirse con Nvidia Triton Inference Server), pero mucho más productivo (al menos para nosotros). La mejora se debe a la fusión de varios OP, lo que nos hace capaces de encadenar los cálculos sin ahorrar resultados intermedios en la memoria de GPU. Lo estamos usando para reescribir:
Gráficos CUDA: es posible que haya escuchado que Python es lento, blablabla y limitar la solución C ++/óxido debería ser la solución. Es cierto, pero mejor que la sobrecarga baja no es en absoluto. ¡Eso son gráficos CUDA! Durante un paso de calentamiento, guardará cada núcleo lanzado y sus parámetros, y luego, con una sola instrucción de GPU, podemos reproducir toda la inferencia.
Torchdynamo: Este prototipo de Meta nos ayuda a hacer frente al comportamiento dinámico. Se describe aquí, y en pocas palabras durante un paso de calentamiento traza el modelo y proporciona un gráfico FX (un gráfico de cálculo estático). Reemplazamos algunas operaciones de este gráfico con nuestros núcleos y lo recompilamos en Python. Hacemos eso para cualquier posible comportamiento dinámico que esperamos tener. Durante la inferencia, se analizan las entradas y se usa el gráfico estático correcto. Es realmente un proyecto increíble, consulte su repositorio para saber más.
El Código de los Kernels de Operai Triton se inspira en ejemplos de los tutoriales de Operai Triton o la Biblioteca Xformers.
Si desea contribuir, por ejemplo al código o documentación, consulte nuestra Guía de contribución.
Consulte nuestro código de conducta para cualquier pregunta sobre la comunidad que estamos tratando de construir y qué hacer si necesita ayuda con alguien que está actuando de manera no profesional.


