pomegranate
v1.1.0
注意重要的是:石榴v1.0.0是使用Pytorch作為計算後端而不是Cython的石榴的地面改寫。儘管支持相同的功能,但API卻顯著不同。請參閱教程和示例文件夾以幫助重寫您的代碼。
readthedocs |教程|例子
石榴是用於概率建模的庫,其模塊化實施和對所有模型作為其概率分佈的處理定義。模塊化實現使人們可以輕鬆地將正常分佈置於混合模型中,以創建高斯混合模型,就像將伽瑪和泊松分佈掉入混合物模型中以創建異質混合物一樣容易。但這不是全部!由於每個模型都被視為概率分佈,因此可以像正態分佈一樣容易地將貝葉斯網絡掉入混合物中,並且可以將隱藏的Markov模型放入貝葉斯分類器中,以使分類器通過序列製作分類器。這兩個設計選擇共同使在任何其他概率建模軟件包中都看不到靈活性。
最近,石榴(v1.0.0)使用Pytorch從頭開始重寫,以取代過時的Cython後端。這種改寫使我有機會解決我作為BB軟件工程師做出的許多不良設計選擇。不幸的是,這些更改中的許多都不是向後兼容的,並且會破壞工作流程。另一方面,這些變化顯著加強了大多數方法,改進和簡化了代碼,修復了多年來社區提出的許多問題,並使貢獻變得更加容易。我在下面寫了更多文章,但是您現在很可能在這裡,因為您的代碼被打破了,這是TL; DR。
特別向Numfocus大喊大叫,以通過特殊的開發贈款來支持這項工作。
pip install pomegranate
如果您需要在重寫之前的最後一個Cython版本,請使用pip install pomegranate==0.14.8 。您可能需要在V3之前手動安裝Cython版本。
這一重寫是由四個主要原因引起的:
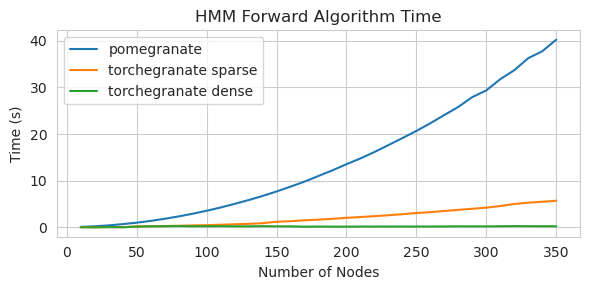
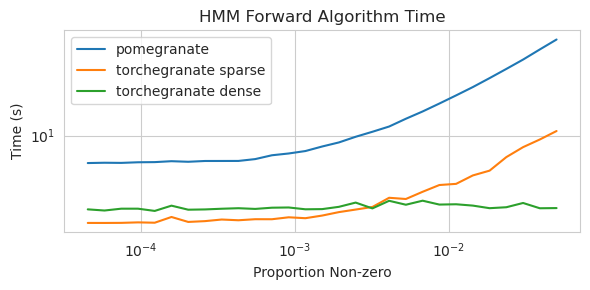
torch.nn.Module的實例torch.masked.MaskedTensor對象支持丟失值NormalDistribution現在是NormalFactorGraph作為一流的公民DenseHMM和SparseHMM模型,這些模型在過渡矩陣的編碼方式上有所不同,在真正的密集圖上, DenseHMM對像明顯更快NaiveBayes已被永久刪除,因為它與BayesClassifier是多餘的MarkovNetwork尚未實施石榴v1.0.0中的大多數模型和方法比早期版本中的模型和方法要快。這通常是按複雜性擴展的,在小型數據集上,只需看到小速度即可進行簡單的分佈,但是在大數據集中,更複雜的模型,例如隱藏的馬爾可夫模型培訓或貝葉斯網絡推斷。目前值得注意的例外是,除了Chow-liu樹建築以外,貝葉斯網絡結構學習仍然不完整,而且速度並不快。在下面的示例中, torchegranate是指用於開發石榴v1.0.0和pomegranate暫時存儲庫,是指石榴v0.14.8。
誰知道這裡發生了什麼?荒野。
緻密過渡矩陣(CPU)
稀疏過渡矩陣(CPU)
訓練具有密集過渡矩陣的125個節點模型
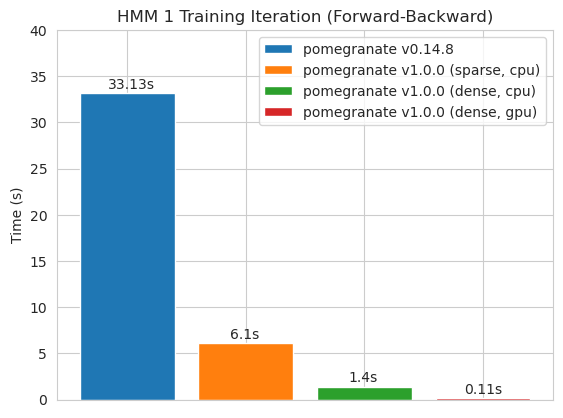
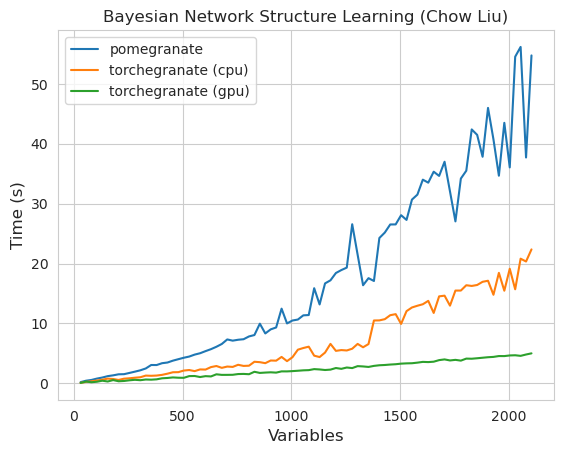
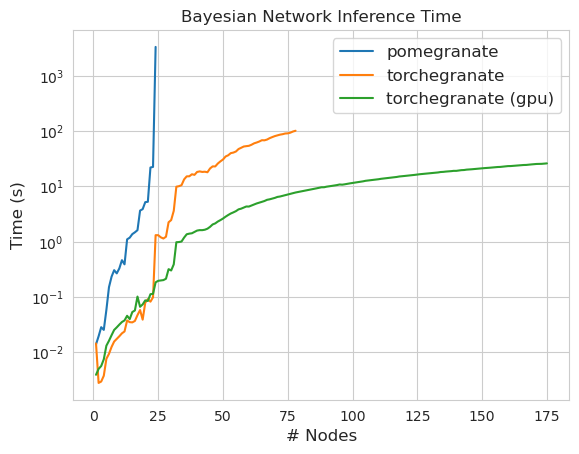
請注意,請參閱Tutorials文件夾以獲取代碼示例。
從Cython的後端切換到Pytorch後端已啟用或擴展了大量功能。由於重寫是Pytorch上的薄包裝器,因為新功能可以用於Pytorch,因此可以將其應用於石榴型號,而無需我的新版本。
石榴中的所有分佈和方法現在都有GPU支持。因為每個分佈都是torch.nn.Module 。這意味著模型和數據都必須由用戶移至GPU。例如:
> >> X = torch . exp ( torch . randn ( 50 , 4 ))
# Will execute on the CPU
> >> d = Exponential (). fit ( X )
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ])
# Will execute on a GPU
> >> d = Exponential (). cuda (). fit ( X . cuda ())
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ], device = 'cuda:0' )同樣,所有模型均為分佈,因此可以在GPU上使用。當模型移至GPU時,與IT相關的所有模型(例如分佈)也將移至GPU。
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()]). cuda ()
> >> model . fit ( X )
[ 1 ] Improvement : 1.26068115234375 , Time : 0.001134 s
[ 2 ] Improvement : 0.168121337890625 , Time : 0.001097 s
[ 3 ] Improvement : 0.037841796875 , Time : 0.001095 s
>> > model . distributions [ 0 ]. scales
Parameter containing :
>> > model . distributions [ 1 ]. scales
tensor ([ 0.9141 , 1.0835 , 2.7503 , 2.2475 ], device = 'cuda:0' )
Parameter containing :
tensor ([ 1.9902 , 2.3871 , 0.8984 , 1.2215 ], device = 'cuda:0' )從理論上講,石榴模型可以與其他Pytorch模塊相同的混合或低精度製度運行。但是,由於石榴比大多數神經網絡使用更複雜的操作,因此這有時在實踐中無效或沒有幫助,因為這些操作尚未在低精度製度中進行優化或實施。因此,希望此功能會隨著時間的流逝而變得更加有用。
> >> X = torch . randn ( 100 , 4 )
> >> d = Normal ( covariance_type = 'diag' )
> >>
>> > with torch . autocast ( 'cuda' , dtype = torch . bfloat16 ):
> >> d . fit ( X )石榴分佈都是torch.nn.Module的所有實例,因此序列化與任何其他Pytorch模型相同。
保存:
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()], verbose = True )
> >> model . cuda ()
> >> model . fit ( X )
> >> torch . save ( model , "test.torch" )載入中:
> >> model = torch . load ( "test.torch" )請注意,
torch.compile正在由Pytorch團隊積極開發,並可能會迅速改善。目前,您可能需要傳遞check_data=False初始化模型以避免兼容性問題。
在Pytorch v2.0.0中, torch.compile被引入了圍繞工具的靈活包裝紙,該工具將操作融合在一起,使用CUDA圖,並通常嘗試在GPU執行中刪除I/O瓶頸。由於這些瓶頸在小型至中等大小的數據設置中可能非常重要,因此許多石榴用戶都面臨著,因此torch.compile似乎非常有價值。您不應針對整個模型(主要是編譯forward方法),而是應該從對像中編譯單個方法。
# Create your object as normal
> >> mu = torch . exp ( torch . randn ( 100 ))
> >> d = Exponential ( mu ). cuda ()
# Create some data
> >> X = torch . exp ( torch . randn ( 1000 , 100 ))
> >> d . log_probability ( X )
# Compile the `log_probability` method!
> >> d . log_probability = torch . compile ( d . log_probability , mode = 'reduce-overhead' , fullgraph = True )
> >> d . log_probability ( X )不幸的是,當以嵌套方式調用方法時,我很難在編譯混合模型的predict方法時,在其中調用了每個分佈的log_probability方法時,我torch.compile工作。我試圖以避免其中一些錯誤的方式組織代碼,但是由於現在的錯誤消息是不透明的,所以我遇到了一些困難。
石榴支持通過torch.masked.MaskedTensor對象處理具有缺失值的數據。簡而言之,只需對丟失的值戴口罩即可。
> >> X = < your tensor with NaN for the missing values >
> >> mask = ~ torch . isnan ( X )
>> > X_masked = torch . masked . MaskedTensor ( X , mask = mask )
>> > d = Normal ( covariance_type = 'diag' ). fit ( X_masked )
>> > d . means
Parameter containing :
tensor ([ 0.2271 , 0.0290 , 0.0763 , 0.0135 ])當前所有算法都將失踪性視為要忽略的東西。例如,當計算具有缺失值的列的平均值時,平均值將僅是當前值的平均值。不估算缺失值,因為不當的插補會偏向您的數據,產生不太可能估計哪些分佈扭曲的分佈以及縮小差異。
因為並非所有操作都適用於蒙版,所以尚未支持以下分佈缺失值:伯努利,分類,正常,完全協方差,統一
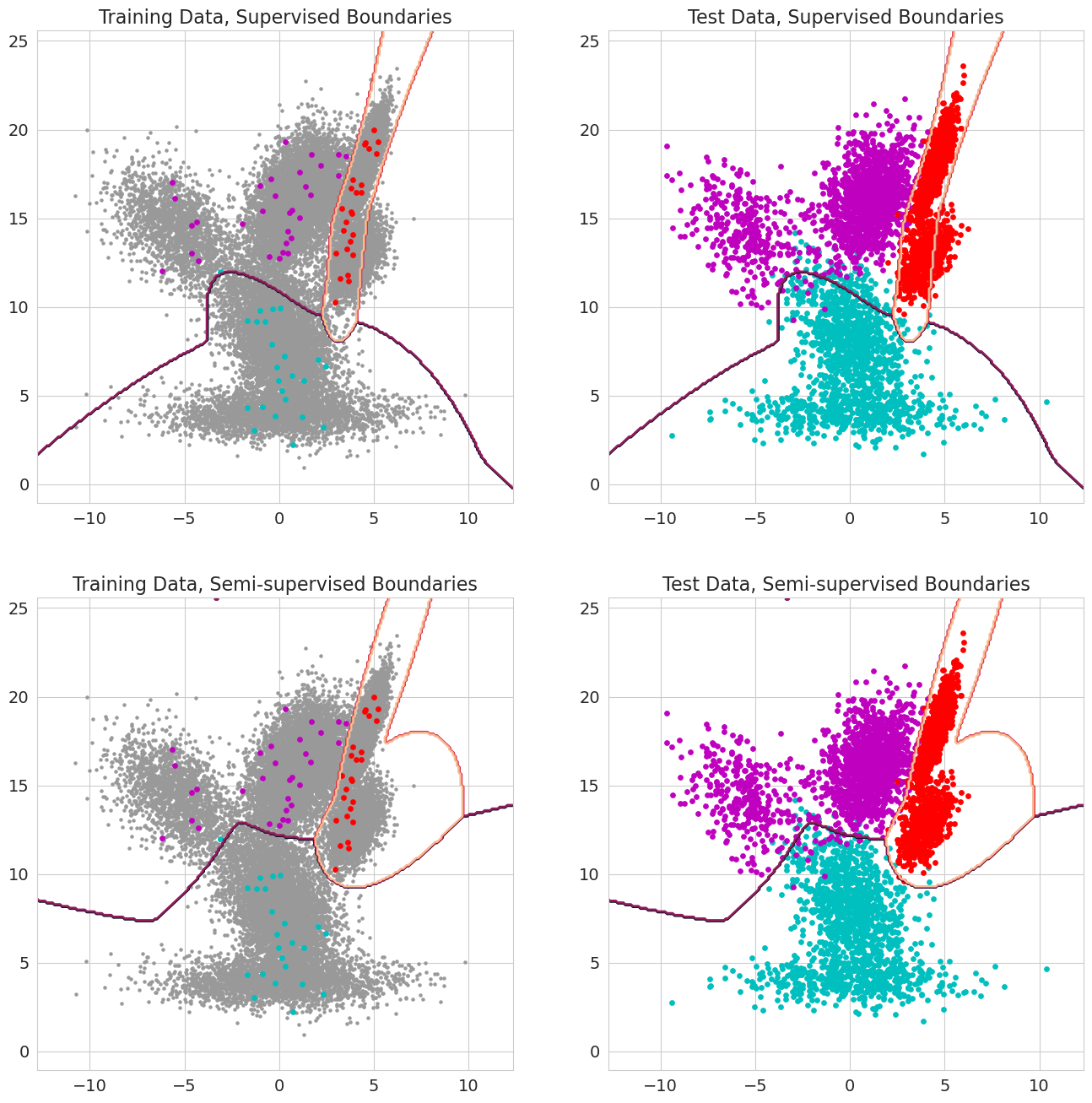
石榴v1.0.0中的一項新功能能夠通過混合模型,貝葉斯分類器和隱藏的馬爾可夫模型的每個觀察結果傳遞先前的概率。在評估可能性之前,觀察結果屬於模型的一部分,並且應在0到1之間。當這些值包括1.0以進行觀察時,它被視為標籤,因為它被視為標籤,因為可能的可能性不再重要,因為將觀察結果分配給州。因此,當每個觀測值對某些狀態,半監督的學習均為1.0時,可以使用這些先前的概率進行標記的訓練,而當觀察值的子集(包括僅在序列中僅針對隱藏的馬可比模型部分標記序列),或者在值為0和1之間的更複雜的權重形式。