pomegranate
v1.1.0
REMARQUE IMPORTANT: La grenade V1.0.0 est une réécriture de la grenade en utilisant Pytorch comme backend informatique au lieu de Cython. Bien que la même fonctionnalité soit prise en charge, l'API est significativement différente. Veuillez consulter les tutoriels et les dossiers d'exemples pour aider à réécrire votre code.
Lecturethedocs | Tutoriels | Exemples
La grenade est une bibliothèque de modélisation probabiliste définie par sa mise en œuvre modulaire et son traitement de tous les modèles comme les distributions de probabilité qu'elles sont. La mise en œuvre modulaire permet à un seul déposer des distributions normales dans un modèle de mélange pour créer un modèle de mélange gaussien tout aussi facilement que de laisser tomber un gamma et une distribution de Poisson dans un modèle de mélange pour créer un mélange hétérogène. Mais ce n'est pas tout! Étant donné que chaque modèle est traité comme une distribution de probabilité, les réseaux bayésiens peuvent être déposés dans un mélange tout aussi facilement qu'une distribution normale, et les modèles de Markov cachés peuvent être déposés dans les classificateurs de Bayes pour faire un classificateur sur des séquences. Ensemble, ces deux choix de conception permettent une flexibilité que l'on ne voit dans aucun autre ensemble de modélisation probabiliste.
Récemment, la grenade (V1.0.0) a été réécrite à partir de zéro en utilisant Pytorch pour remplacer le backend cython obsolète. Cette réécriture m'a donné l'occasion de réparer de nombreux mauvais choix de conception que j'ai fait en tant qu'ingénieur logiciel BB. Malheureusement, bon nombre de ces changements ne sont pas compatibles en arrière et perturberont les workflows. D'un autre côté, ces changements ont considérablement accéléré la plupart des méthodes, amélioré et simplifié le code, résolu de nombreux problèmes soulevés par la communauté au fil des ans et facilite la contribution. J'ai écrit plus ci-dessous, mais vous êtes probablement ici maintenant parce que votre code est cassé et c'est le TL; DR.
Un cri spécial à Numfocus pour soutenir ce travail avec une subvention de développement spéciale.
pip install pomegranate
Si vous avez besoin de la dernière version de cython avant la réécriture, utilisez pip install pomegranate==0.14.8 . Vous devrez peut-être installer manuellement une version de Cython avant V3.
Cette réécriture a été motivée par quatre raisons principales:
torch.nn.Moduletorch.masked.MaskedTensor objetsNormalDistribution soit désormais NormalFactorGraph est désormais soutenu en tant que citoyens de première classe, avec toutes les méthodes de prédiction et de formationDenseHMM et SparseHMM qui diffèrent dans la façon dont la matrice de transition est codée, les objets DenseHMM étant considérablement plus rapides sur des graphiques vraiment densesNaiveBayes a été enlevé en permanence car il est redondant avec BayesClassifierMarkovNetwork n'a pas encore été implémenté La plupart des modèles et méthodes dans la grenade V1.0.0 sont plus rapides que leurs homologues dans les versions antérieures. Cela évolue généralement par complexité, où l'on ne voit que de petites accélérations pour des distributions simples sur de petits ensembles de données mais des accélérations beaucoup plus importantes pour des modèles plus complexes sur les ensembles de big data, par exemple la formation de modèle de Markov caché ou l'inférence du réseau bayésien. L'exception notable pour l'instant est que l'apprentissage de la structure du réseau bayésien, autre que le bâtiment des arbres Chow-Liu, est toujours incomplet et pas beaucoup plus rapide. Dans les exemples ci-dessous, torchegranate fait référence au référentiel temporairement utilisé pour développer la grenade V1.0.0 et pomegranate fait référence à la grenade V0.14.8.
Qui sait ce qui se passe ici? Sauvage.
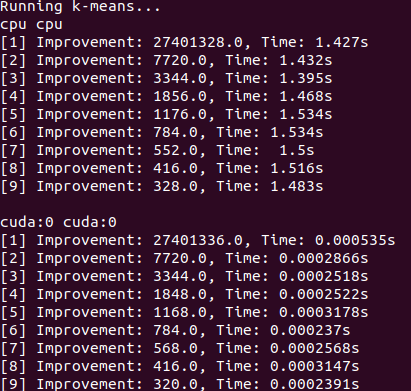
Matrice de transition dense (CPU)
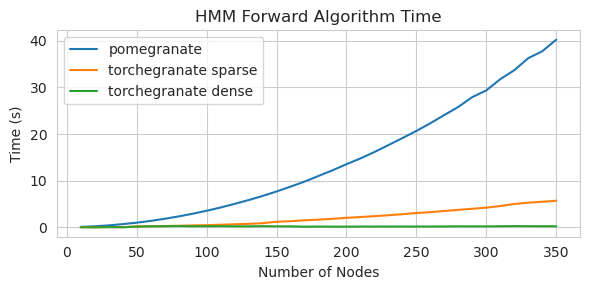
Matrice de transition clairsemée (CPU)
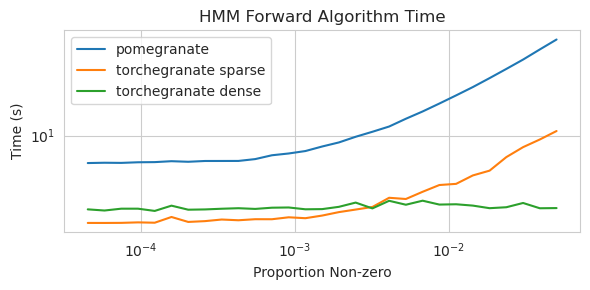
Formation d'un modèle de nœud 125 avec une matrice de transition dense
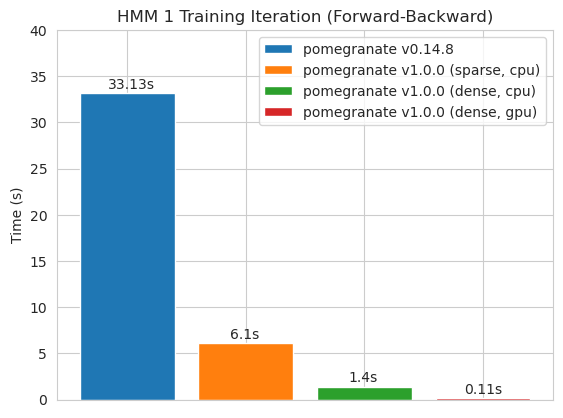
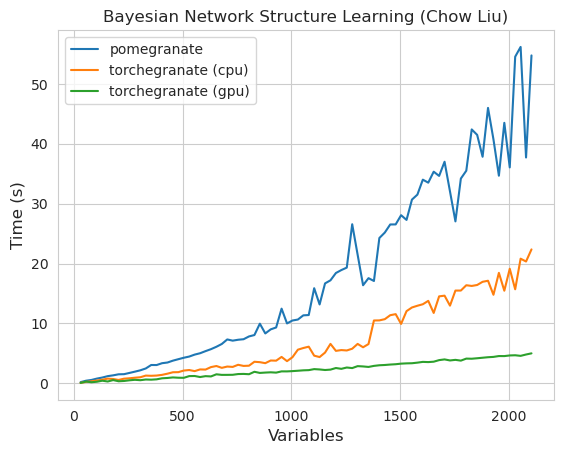
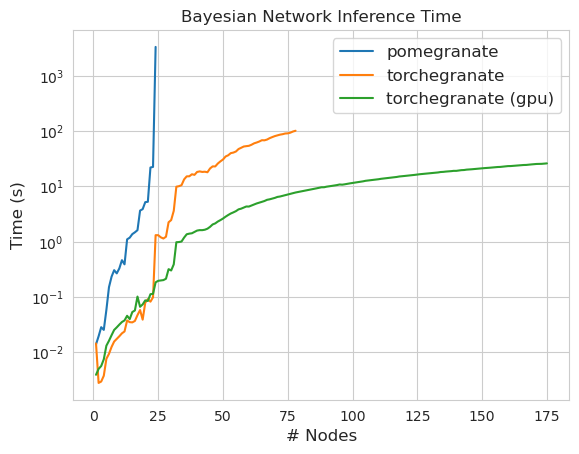
Remarque Veuillez consulter le dossier Tutorials pour les exemples de code.
Le passage d'un backend Cython à un backend Pytorch a permis ou étendu un grand nombre de fonctionnalités. Parce que la réécriture est un emballage mince sur Pytorch, à mesure que de nouvelles fonctionnalités sont publiées pour Pytorch, elles peuvent être appliquées aux modèles de grenade sans avoir besoin d'une nouvelle version de moi.
Toutes les distributions et méthodes dans la grenade ont désormais un support GPU. Étant donné que chaque distribution est un objet torch.nn.Module , l'utilisation est identique à d'autres code écrits en pytorch. Cela signifie que le modèle et les données doivent être déplacés vers le GPU par l'utilisateur. Par exemple:
> >> X = torch . exp ( torch . randn ( 50 , 4 ))
# Will execute on the CPU
> >> d = Exponential (). fit ( X )
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ])
# Will execute on a GPU
> >> d = Exponential (). cuda (). fit ( X . cuda ())
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ], device = 'cuda:0' )De même, tous les modèles sont des distributions et peuvent donc être utilisés sur le GPU de la même manière. Lorsqu'un modèle est déplacé vers le GPU, tous les modèles qui y sont associés (par exemple les distributions) sont également déplacés vers le GPU.
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()]). cuda ()
> >> model . fit ( X )
[ 1 ] Improvement : 1.26068115234375 , Time : 0.001134 s
[ 2 ] Improvement : 0.168121337890625 , Time : 0.001097 s
[ 3 ] Improvement : 0.037841796875 , Time : 0.001095 s
>> > model . distributions [ 0 ]. scales
Parameter containing :
>> > model . distributions [ 1 ]. scales
tensor ([ 0.9141 , 1.0835 , 2.7503 , 2.2475 ], device = 'cuda:0' )
Parameter containing :
tensor ([ 1.9902 , 2.3871 , 0.8984 , 1.2215 ], device = 'cuda:0' )Les modèles de grenade peuvent, en théorie, fonctionner dans les mêmes régimes mixtes ou à faible précision que les autres modules Pytorch. Cependant, comme la grenade utilise des opérations plus complexes que la plupart des réseaux de neurones, cela ne fonctionne parfois ni ne fonctionne dans la pratique car ces opérations n'ont pas été optimisées ou mises en œuvre dans le régime de faible précision. Donc, j'espère que cette fonctionnalité deviendra plus utile au fil du temps.
> >> X = torch . randn ( 100 , 4 )
> >> d = Normal ( covariance_type = 'diag' )
> >>
>> > with torch . autocast ( 'cuda' , dtype = torch . bfloat16 ):
> >> d . fit ( X ) Les distributions de grenade sont toutes des cas de torch.nn.Module et donc la sérialisation est la même que tout autre modèle Pytorch.
Économie:
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()], verbose = True )
> >> model . cuda ()
> >> model . fit ( X )
> >> torch . save ( model , "test.torch" )Chargement:
> >> model = torch . load ( "test.torch" )Remarque
torch.compileest en cours de développement actif par l'équipe Pytorch et peut rapidement s'améliorer. Pour l'instant, vous devrez peut-être passer danscheck_data=Falselors de l'initialisation des modèles pour éviter un problème de compatibilité.
Dans Pytorch v2.0.0, torch.compile a été introduit comme un wrapper flexible autour d'outils qui fusionneraient les opérations ensemble, utiliseraient les graphiques CUDA et essaient généralement de supprimer les goulots d'étranglement d'E / S dans l'exécution du GPU. Étant donné que ces goulots d'étranglement peuvent être extrêmement significatifs dans les paramètres de données de petite à moyen de taille que de nombreux utilisateurs de grenade sont confrontés, torch.compile semble être extrêmement précieux. Plutôt que de cibler des modèles entiers, qui compile principalement la méthode forward , vous devez compiler des méthodes individuelles à partir de vos objets.
# Create your object as normal
> >> mu = torch . exp ( torch . randn ( 100 ))
> >> d = Exponential ( mu ). cuda ()
# Create some data
> >> X = torch . exp ( torch . randn ( 1000 , 100 ))
> >> d . log_probability ( X )
# Compile the `log_probability` method!
> >> d . log_probability = torch . compile ( d . log_probability , mode = 'reduce-overhead' , fullgraph = True )
> >> d . log_probability ( X ) Malheureusement, j'ai eu du mal à faire fonctionner torch.compile lorsque les méthodes sont appelées de manière imbriquée, par exemple, lors de la compilation de la méthode predict pour un modèle de mélange qui, à l'intérieur, appelle la méthode log_probability de chaque distribution. J'ai essayé d'organiser le code d'une manière qui évite certaines de ces erreurs, mais parce que les messages d'erreur sont maintenant opaques, j'ai eu des difficultés.
Pomegranate prend en charge la gestion des données avec des valeurs manquantes via torch.masked.MaskedTensor objets. Simplement, il faut simplement mettre un masque sur les valeurs qui manquent.
> >> X = < your tensor with NaN for the missing values >
> >> mask = ~ torch . isnan ( X )
>> > X_masked = torch . masked . MaskedTensor ( X , mask = mask )
>> > d = Normal ( covariance_type = 'diag' ). fit ( X_masked )
>> > d . means
Parameter containing :
tensor ([ 0.2271 , 0.0290 , 0.0763 , 0.0135 ])Tous les algorithmes traitent actuellement la manque de la manque comme quelque chose à ignorer. Par exemple, lors du calcul de la moyenne d'une colonne avec des valeurs manquantes, la moyenne sera simplement la valeur moyenne des valeurs actuelles. Les valeurs manquantes ne sont pas imputées car une imputation incorrecte peut biaiser vos données, produire des estimations improbables qui déforment les distributions et réduire également la variance.
Parce que toutes les opérations ne sont pas encore disponibles pour Maskedtenseurs, les distributions suivantes ne sont pas encore prises en charge pour les valeurs manquantes: Bernoulli, catégorielle, normale avec une covariance complète, uniforme
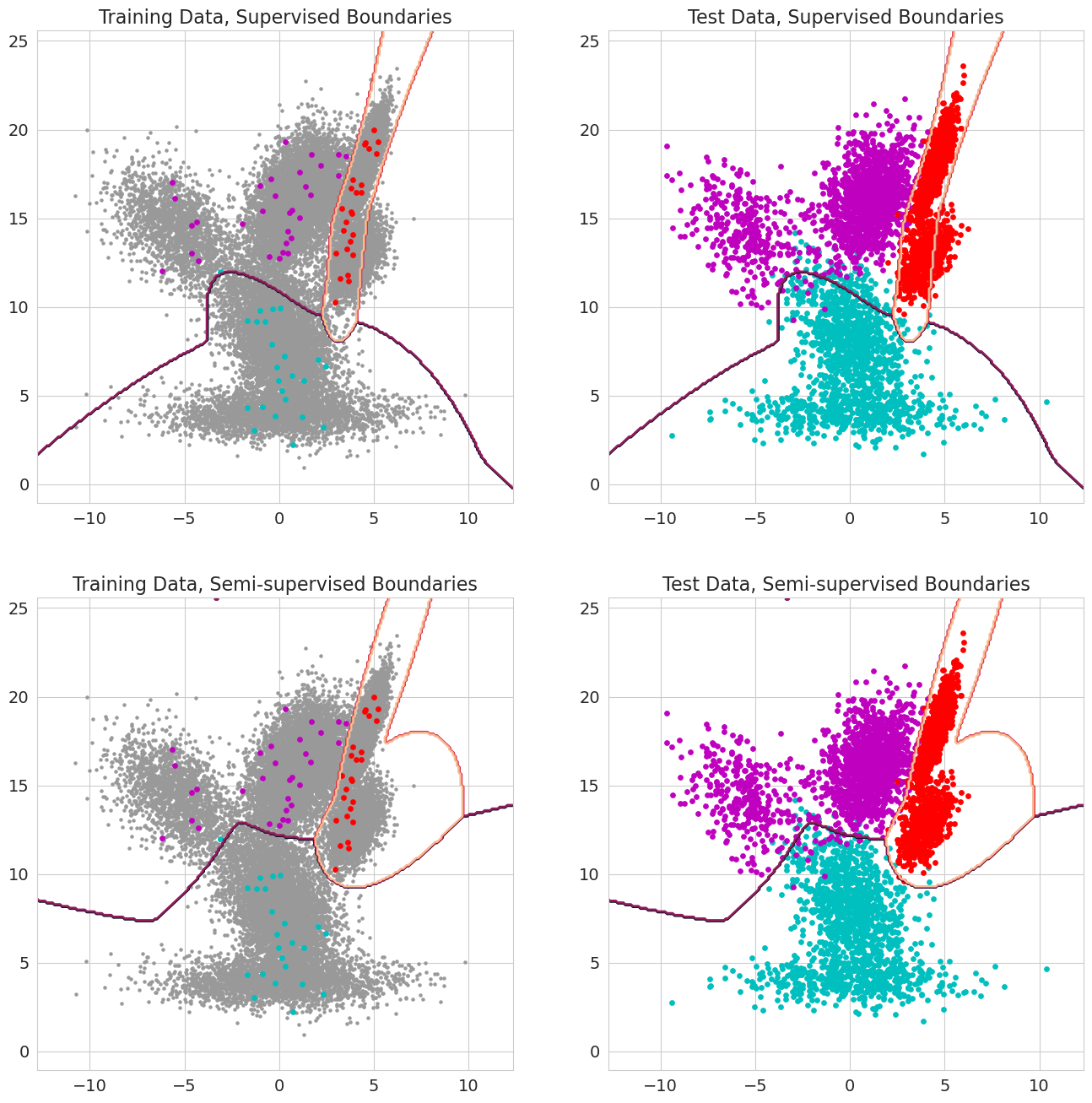
Une nouvelle fonctionnalité dans la grenade V1.0.0 est de pouvoir passer dans des probabilités antérieures pour chaque observation pour les modèles de mélange, les classificateurs de Bayes et les modèles de Markov cachés. Ce sont la probabilité préalable qu'une observation appartient à un composant du modèle avant d'évaluer la probabilité et devrait aller entre 0 et 1. Lorsque ces valeurs incluent un 1.0 pour une observation, elle est traitée comme une étiquette, car la probabilité n'a plus d'importance en termes d'attribution de cette observation à un état. Par conséquent, on peut utiliser ces probabilités antérieures pour effectuer une formation étiquetée lorsque chaque observation a un 1.0 pour certains états, un apprentissage semi-supervisé lorsqu'un sous-ensemble d'observations (y compris lorsque les séquences ne sont étiquetées partiellement que pour les modèles de Markov cachés), ou des formes de pondération plus sophistiquées lorsque les valeurs sont entre 0 et 1.