pomegranate
v1.1.0
Nota importante: la granada V1.0.0 es una reescritura de granada con Pytorch como backend computacional en lugar de Cython. Aunque es compatible con la misma funcionalidad, la API es significativamente diferente. Consulte las carpetas de tutoriales y ejemplos para obtener ayuda para reescribir su código.
Readthedocs | Tutoriales | Ejemplos
La granada es una biblioteca para el modelado probabilístico definido por su implementación modular y tratamiento de todos los modelos como las distribuciones de probabilidad que son. La implementación modular permite que uno elimine fácilmente las distribuciones normales en un modelo de mezcla para crear un modelo de mezcla gaussiano con la misma facilidad como dejar una gamma y una distribución de Poisson en un modelo de mezcla para crear una mezcla heterogénea. ¡Pero eso no es todo! Debido a que cada modelo se trata como una distribución de probabilidad, las redes bayesianas se pueden dejar en una mezcla tan fácilmente como una distribución normal, y los modelos ocultos de Markov se pueden dejar en clasificadores Bayes para hacer un clasificador sobre secuencias. Juntos, estas dos opciones de diseño permiten una flexibilidad que no se ve en ningún otro paquete de modelado probabilístico.
Recientemente, la granada (V1.0.0) se reescribió desde cero usando Pytorch para reemplazar el backend obsoleto de Cython. Esta reescritura me dio la oportunidad de arreglar muchas opciones de diseño malas que hice como ingeniero de software de BB. Desafortunadamente, muchos de estos cambios no son compatibles hacia atrás e interrumpirán los flujos de trabajo. Por otro lado, estos cambios han acelerado significativamente la mayoría de los métodos, mejoraron y simplificaron el código, solucionaron muchos problemas planteados por la comunidad a lo largo de los años y facilitaron significativamente la contribución. He escrito más a continuación, pero es probable que ya esté aquí porque su código está roto y este es el TL; DR.
Shout-Out especial a Numfocus por apoyar este trabajo con una beca de desarrollo especial.
pip install pomegranate
Si necesita la última liberación de Cython antes de reescribir, use pip install pomegranate==0.14.8 . Es posible que deba instalar manualmente una versión de Cython antes de V3.
Esta reescritura fue motivada por cuatro razones principales:
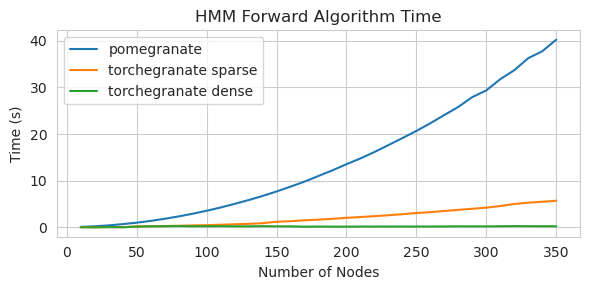
torch.nn.Moduletorch.masked.MaskedTensor ObjectsNormalDistribution ahora sea NormalFactorGraph ahora es compatible como ciudadanos de primera clase, con todos los métodos de predicción y capacitaciónDenseHMM y SparseHMM que difieren en cómo se codifica la matriz de transición, con objetos DenseHMM que son significativamente más rápidos en gráficos verdaderamente densosNaiveBayes ha sido eliminado permanentemente, ya que es redundante con BayesClassifierMarkovNetwork aún no se ha implementado La mayoría de los modelos y métodos en la granada V1.0.0 son más rápidos que sus homólogos en versiones anteriores. Esto generalmente escala por complejidad, donde solo se ve pequeñas aceleraciones para distribuciones simples en pequeños conjuntos de datos, pero aceleras mucho más grandes para modelos más complejos en conjuntos de big data, por ejemplo, entrenamiento de modelo Markov oculto o inferencia de red bayesiana. La notable excepción por ahora es que el aprendizaje de la estructura de red bayesiana, aparte del edificio de árboles Chow-Liu, sigue siendo incompleto y no mucho más rápido. En los ejemplos a continuación, torchegranate se refiere al repositorio temporal utilizado para desarrollar la granada V1.0.0 y pomegranate se refiere a la granada V0.14.8.
¿Quién sabe lo que está pasando aquí? Salvaje.
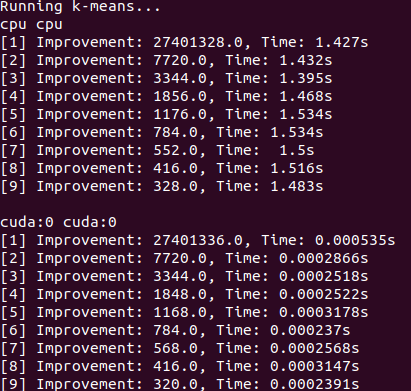
Matriz de transición densa (CPU)
Matriz de transición dispersa (CPU)
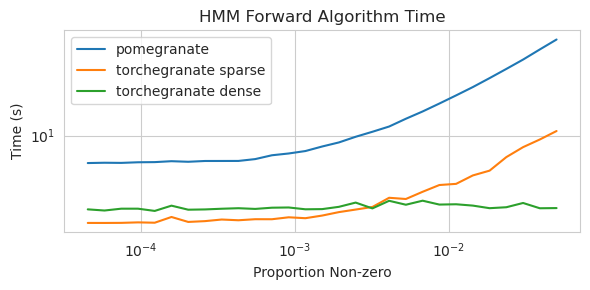
Entrenamiento de un modelo de nodo 125 con una matriz de transición densa
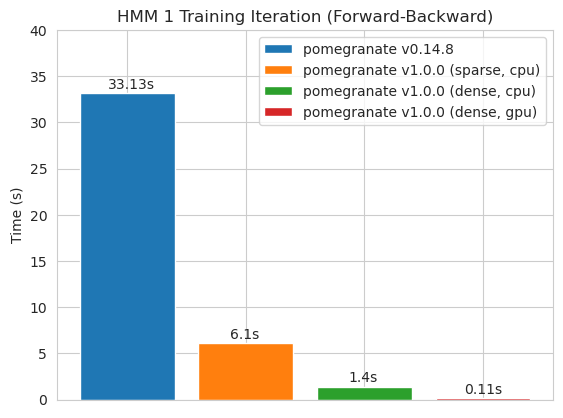
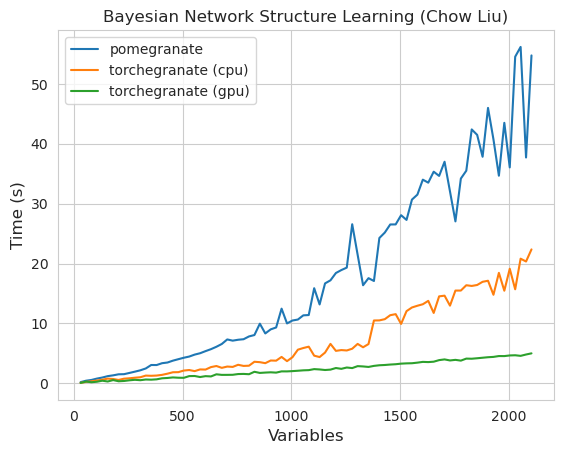
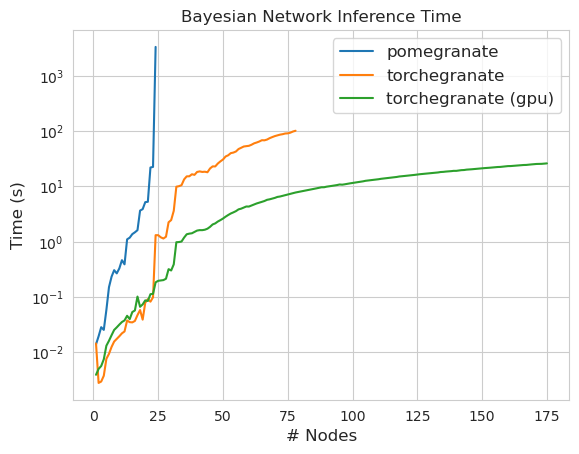
Nota Consulte la carpeta de tutoriales para ver ejemplos de código.
Cambiar de un backend de Cython a un backend de Pytorch ha habilitado o expandido una gran cantidad de características. Debido a que la reescritura es una envoltura delgada sobre Pytorch, ya que se lanzan nuevas características para Pytorch, se pueden aplicar a los modelos de granada sin la necesidad de una nueva versión de mí.
Todas las distribuciones y métodos en granada ahora tienen soporte de GPU. Debido a que cada distribución es un objeto torch.nn.Module , el uso es idéntico a otro código escrito en Pytorch. Esto significa que tanto el modelo como los datos deben ser trasladados a la GPU por el usuario. Por ejemplo:
> >> X = torch . exp ( torch . randn ( 50 , 4 ))
# Will execute on the CPU
> >> d = Exponential (). fit ( X )
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ])
# Will execute on a GPU
> >> d = Exponential (). cuda (). fit ( X . cuda ())
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ], device = 'cuda:0' )Del mismo modo, todos los modelos son distribuciones y, por lo tanto, se pueden usar en la GPU de manera similar. Cuando se mueve un modelo a la GPU, todos los modelos asociados con él (por ejemplo, distribuciones) también se trasladan a la GPU.
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()]). cuda ()
> >> model . fit ( X )
[ 1 ] Improvement : 1.26068115234375 , Time : 0.001134 s
[ 2 ] Improvement : 0.168121337890625 , Time : 0.001097 s
[ 3 ] Improvement : 0.037841796875 , Time : 0.001095 s
>> > model . distributions [ 0 ]. scales
Parameter containing :
>> > model . distributions [ 1 ]. scales
tensor ([ 0.9141 , 1.0835 , 2.7503 , 2.2475 ], device = 'cuda:0' )
Parameter containing :
tensor ([ 1.9902 , 2.3871 , 0.8984 , 1.2215 ], device = 'cuda:0' )Los modelos de granada pueden, en teoría, operar en los mismos regímenes mixtos o de baja precisión que otros módulos de Pytorch. Sin embargo, debido a que la granada usa operaciones más complejas que la mayoría de las redes neuronales, esto a veces no funciona o ayuda en la práctica porque estas operaciones no se han optimizado o implementado en el régimen de baja precisión. Entonces, con suerte, esta característica se vuelve más útil con el tiempo.
> >> X = torch . randn ( 100 , 4 )
> >> d = Normal ( covariance_type = 'diag' )
> >>
>> > with torch . autocast ( 'cuda' , dtype = torch . bfloat16 ):
> >> d . fit ( X ) Las distribuciones de granada son todas las instancias de torch.nn.Module y, por lo tanto, la serialización es las mismas que cualquier otro modelo de Pytorch.
Ahorro:
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()], verbose = True )
> >> model . cuda ()
> >> model . fit ( X )
> >> torch . save ( model , "test.torch" )Cargando:
> >> model = torch . load ( "test.torch" )Nota
torch.compileestá bajo desarrollo activo por el equipo de Pytorch y puede mejorar rápidamente. Por ahora, es posible que deba pasar encheck_data=Falseal inicializar modelos para evitar un problema de compatibilidad.
En Pytorch v2.0.0, torch.compile se introdujo como un envoltorio flexible alrededor de las herramientas que fusionarían las operaciones, usaría gráficos CUDA y, en general, trataría de eliminar los cuellos de botella de E/S en la ejecución de GPU. Debido a que estos cuellos de botella pueden ser extremadamente significativos en la configuración de datos de tamaño pequeño a mediano que enfrentan muchos usuarios de granados, torch.compile parece que será extremadamente valioso. En lugar de dirigirse a modelos enteros, que en su mayoría solo compila el método forward , debe compilar métodos individuales de sus objetos.
# Create your object as normal
> >> mu = torch . exp ( torch . randn ( 100 ))
> >> d = Exponential ( mu ). cuda ()
# Create some data
> >> X = torch . exp ( torch . randn ( 1000 , 100 ))
> >> d . log_probability ( X )
# Compile the `log_probability` method!
> >> d . log_probability = torch . compile ( d . log_probability , mode = 'reduce-overhead' , fullgraph = True )
> >> d . log_probability ( X ) Desafortunadamente, he tenido dificultades para log_probability predict torch.compile . He tratado de organizar el código de una manera que evite algunos de estos errores, pero debido a que los mensajes de error en este momento son opacos, he tenido alguna dificultad.
La granada admite el manejo de datos con valores faltantes a través de torch.masked.MaskedTensor Objects. Simplemente, uno solo debe poner una máscara sobre los valores que faltan.
> >> X = < your tensor with NaN for the missing values >
> >> mask = ~ torch . isnan ( X )
>> > X_masked = torch . masked . MaskedTensor ( X , mask = mask )
>> > d = Normal ( covariance_type = 'diag' ). fit ( X_masked )
>> > d . means
Parameter containing :
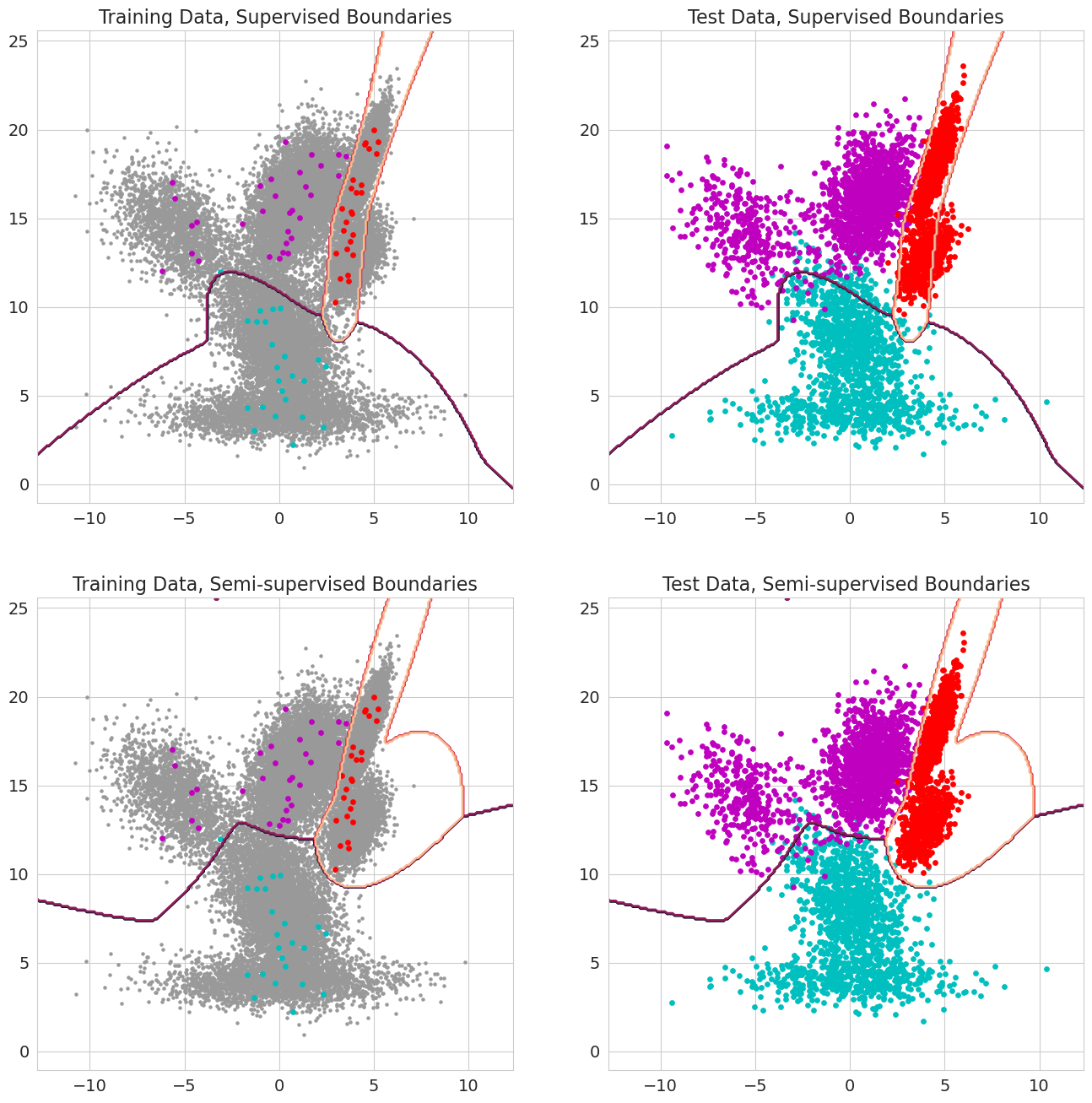
tensor ([ 0.2271 , 0.0290 , 0.0763 , 0.0135 ])Todos los algoritmos actualmente tratan la falta de falta como algo para ignorar. Como ejemplo, al calcular la media de una columna con valores faltantes, la media será simplemente el valor promedio de los valores actuales. Los valores faltantes no se imputan porque la imputación inadecuada puede sesgar sus datos, producir estimaciones poco probables que distorsionan las distribuciones y también reduzca la varianza.
Debido a que no todas las operaciones aún están disponibles para MaskedTensors, las siguientes distribuciones aún no son compatibles con los valores faltantes: Bernoulli, categórico, normal con covarianza completa, uniforme
Una nueva característica en la granada V1.0.0 es poder aprobar probabilidades previas para cada observación para modelos de mezcla, clasificadores Bayes y modelos ocultos de Markov. Estas son la probabilidad previa de que una observación pertenezca a un componente del modelo antes de evaluar la probabilidad y debe variar entre 0 y 1. Cuando estos valores incluyen un 1.0 para una observación, se trata como una etiqueta, porque la probabilidad no es importante en términos de asignar esa observación a un estado. Por lo tanto, uno puede usar estas probabilidades previas para realizar el entrenamiento etiquetado cuando cada observación tiene un 1.0 para algún estado, aprendizaje semi-supervisado cuando un subconjunto de observaciones (incluso cuando las secuencias solo están parcialmente marcadas para modelos ocultos de Markov), o formas de ponderación más sofisticadas cuando los valores están entre 0 y 1.