pomegranate
v1.1.0
หมายเหตุ สำคัญ: Pomegranate v1.0.0 เป็นการเขียนทับทิมของทับทิมโดยใช้ pytorch เป็นแบ็กเอนด์การคำนวณแทน cython แม้ว่าจะรองรับฟังก์ชั่นเดียวกัน แต่ API นั้นแตกต่างกันอย่างมีนัยสำคัญ โปรดดูบทช่วยสอนและตัวอย่างโฟลเดอร์สำหรับความช่วยเหลือในการเขียนรหัสของคุณใหม่
readthedocs | บทเรียน ตัวอย่าง
Pomegranate เป็นไลบรารีสำหรับการสร้างแบบจำลองความน่าจะเป็นที่กำหนดโดยการใช้งานแบบแยกส่วนและการรักษาแบบจำลองทั้งหมดเป็นการแจกแจงความน่าจะเป็น การใช้งานแบบแยกส่วนช่วยให้การแจกแจงแบบปกติลงในแบบจำลองส่วนผสมเพื่อสร้างแบบจำลองส่วนผสมแบบเกาส์เซียนได้อย่างง่ายดายเช่นเดียวกับการปล่อยแกมม่าและการกระจายแบบปัวซองลงในแบบจำลองผสมเพื่อสร้างส่วนผสมที่แตกต่างกัน แต่นั่นไม่ใช่ทั้งหมด! เนื่องจากแต่ละรุ่นได้รับการปฏิบัติเป็นการกระจายความน่าจะเป็นเครือข่ายแบบเบย์สามารถลดลงในส่วนผสมได้อย่างง่ายดายเช่นเดียวกับการแจกแจงแบบปกติและโมเดลมาร์คอฟที่ซ่อนอยู่สามารถลดลงในตัวจําแนกเบย์เพื่อสร้างตัวแยกประเภทเหนือลำดับ ตัวเลือกการออกแบบทั้งสองนี้ช่วยให้มีความยืดหยุ่นที่ไม่เห็นในแพ็คเกจการสร้างแบบจำลองความน่าจะเป็นอื่น ๆ
เมื่อเร็ว ๆ นี้ Pomegranate (v1.0.0) ถูกเขียนใหม่จากพื้นดินโดยใช้ Pytorch เพื่อแทนที่แบ็กเอนด์ Cython ที่ล้าสมัย การเขียนใหม่นี้ให้โอกาสฉันในการแก้ไขตัวเลือกการออกแบบที่ไม่ดีมากมายที่ฉันทำในฐานะวิศวกรซอฟต์แวร์ BB น่าเสียดายที่การเปลี่ยนแปลงเหล่านี้จำนวนมากไม่เข้ากันได้และจะขัดขวางเวิร์กโฟลว์ ในทางกลับกันการเปลี่ยนแปลงเหล่านี้ได้เร่งวิธีการส่วนใหญ่อย่างมีนัยสำคัญปรับปรุงและทำให้โค้ดง่ายขึ้นแก้ไขปัญหาต่าง ๆ ที่เกิดขึ้นจากชุมชนในช่วงหลายปีที่ผ่านมาและทำให้การมีส่วนร่วมง่ายขึ้นอย่างมีนัยสำคัญ ฉันเขียนเพิ่มเติมด้านล่าง แต่ตอนนี้คุณน่าจะมาที่นี่เพราะรหัสของคุณเสียและนี่คือ TL; DR
ตะโกนพิเศษไปยัง Numfocus สำหรับการสนับสนุนงานนี้ด้วยเงินช่วยเหลือการพัฒนาพิเศษ
pip install pomegranate
หากคุณต้องการการเปิดตัว Cython ล่าสุดก่อนที่จะเขียนใหม่ให้ใช้ pip install pomegranate==0.14.8 คุณอาจต้องติดตั้ง Cython รุ่นก่อน V3 ด้วยตนเอง
การเขียนใหม่นี้ได้รับแรงบันดาลใจจากเหตุผลหลักสี่ประการ:
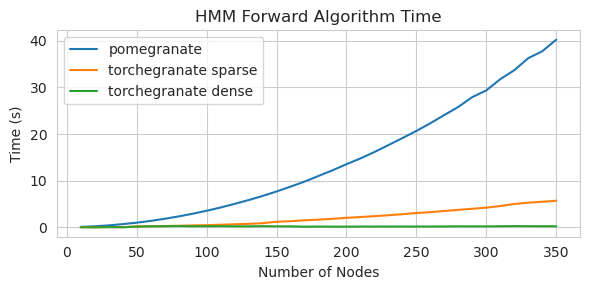
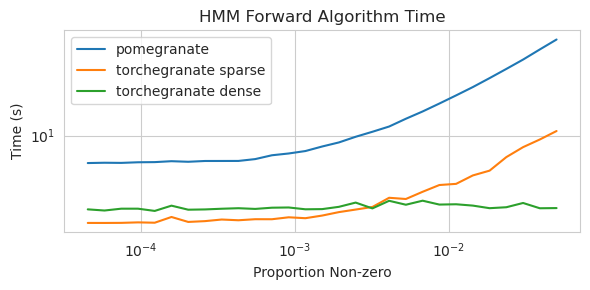
torch.nn.Moduletorch.masked.MaskedTensor ObjectsNormalDistribution เป็น NormalFactorGraph ได้รับการสนับสนุนในฐานะพลเมืองชั้นหนึ่งด้วยวิธีการทำนายและการฝึกอบรมทั้งหมดDenseHMM และ SparseHMM ซึ่งแตกต่างกันในการเข้ารหัสเมทริกซ์การเปลี่ยนผ่านโดยมีวัตถุ DenseHMM เร็วขึ้นอย่างมีนัยสำคัญบนกราฟหนาแน่นอย่างแท้จริงอย่างแท้จริงNaiveBayes ถูกลบออกอย่างถาวรเนื่องจากมีการซ้ำซ้อนกับ BayesClassifierMarkovNetwork ยังไม่ได้ดำเนินการ แบบจำลองและวิธีการส่วนใหญ่ในทับทิม v1.0.0 เร็วกว่าคู่ของพวกเขาในรุ่นก่อนหน้า โดยทั่วไปแล้วจะปรับขนาดโดยความซับซ้อนโดยที่หนึ่งเห็นการเร่งความเร็วเพียงเล็กน้อยสำหรับการแจกแจงแบบง่าย ๆ ในชุดข้อมูลขนาดเล็ก แต่การเร่งความเร็วที่ใหญ่ขึ้นสำหรับรุ่นที่ซับซ้อนมากขึ้นในชุดข้อมูลขนาดใหญ่เช่นการฝึกอบรมแบบจำลอง Markov ที่ซ่อนอยู่หรือการอนุมานเครือข่ายแบบเบย์ ข้อยกเว้นที่น่าสังเกตในตอนนี้คือการเรียนรู้โครงสร้างเครือข่ายแบบเบย์นอกเหนือจากการสร้างต้นไม้ Chow-Liu ยังคงไม่สมบูรณ์และไม่เร็วนัก ในตัวอย่างด้านล่าง torchegranate หมายถึงที่เก็บชั่วคราวที่ใช้ในการพัฒนาทับทิม v1.0.0 และ pomegranate หมายถึงทับทิม v0.14.8
ใครจะรู้ว่าเกิดอะไรขึ้นที่นี่? ป่า.
เมทริกซ์การเปลี่ยนแปลงหนาแน่น (CPU)
เมทริกซ์การเปลี่ยนแปลงแบบเบาบาง (CPU)
ฝึกอบรมโมเดลโหนด 125 ด้วยเมทริกซ์การเปลี่ยนแปลงที่หนาแน่น
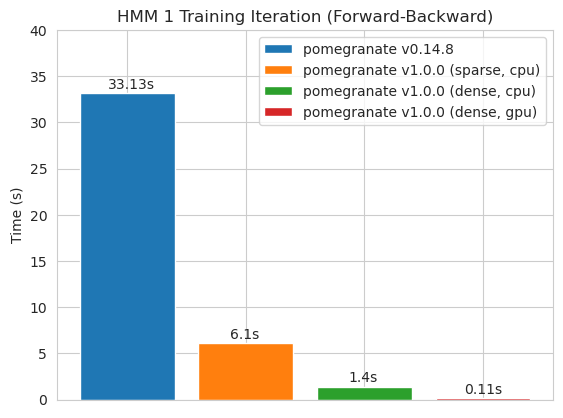
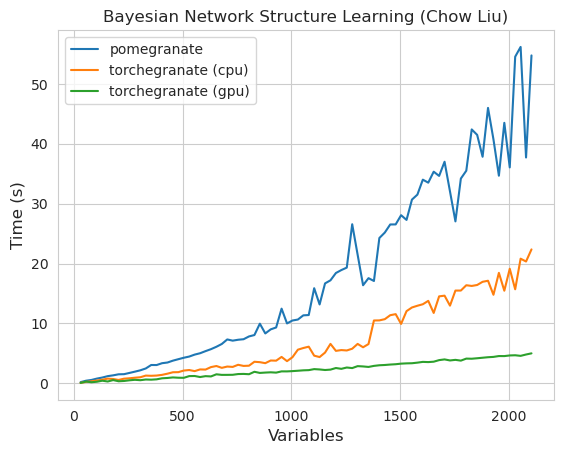
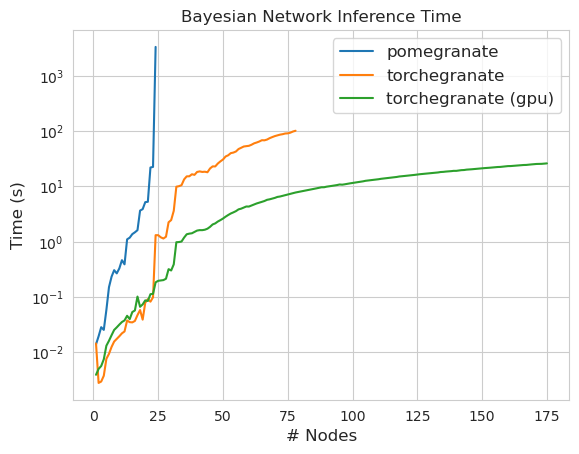
หมายเหตุ โปรดดูโฟลเดอร์แบบฝึกหัดสำหรับตัวอย่างรหัส
การเปลี่ยนจากแบ็กเอนด์ Cython เป็นแบ็กเอนด์ Pytorch ได้เปิดใช้งานหรือขยายคุณสมบัติจำนวนมาก เนื่องจากการเขียนใหม่เป็น wrapper บาง ๆ เหนือ pytorch เนื่องจากคุณสมบัติใหม่ได้รับการปล่อยตัวสำหรับ pytorch พวกเขาสามารถนำไปใช้กับรุ่นทับทิมโดยไม่จำเป็นต้องมีการเปิดตัวใหม่จากฉัน
การแจกแจงและวิธีการทั้งหมดในทับทิมในขณะนี้มีการสนับสนุน GPU เนื่องจากการแจกแจงแต่ละครั้งเป็นวัตถุ torch.nn.Module การใช้งานจึงเหมือนกับรหัสอื่นที่เขียนใน Pytorch ซึ่งหมายความว่าทั้งโมเดลและข้อมูลจะต้องถูกย้ายไปยัง GPU โดยผู้ใช้ ตัวอย่างเช่น:
> >> X = torch . exp ( torch . randn ( 50 , 4 ))
# Will execute on the CPU
> >> d = Exponential (). fit ( X )
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ])
# Will execute on a GPU
> >> d = Exponential (). cuda (). fit ( X . cuda ())
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ], device = 'cuda:0' )ในทำนองเดียวกันทุกรุ่นเป็นการแจกแจงและสามารถใช้กับ GPU ได้ในทำนองเดียวกัน เมื่อโมเดลถูกย้ายไปยัง GPU โมเดลทั้งหมดที่เกี่ยวข้อง (เช่นการแจกแจง) จะถูกย้ายไปยัง GPU
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()]). cuda ()
> >> model . fit ( X )
[ 1 ] Improvement : 1.26068115234375 , Time : 0.001134 s
[ 2 ] Improvement : 0.168121337890625 , Time : 0.001097 s
[ 3 ] Improvement : 0.037841796875 , Time : 0.001095 s
>> > model . distributions [ 0 ]. scales
Parameter containing :
>> > model . distributions [ 1 ]. scales
tensor ([ 0.9141 , 1.0835 , 2.7503 , 2.2475 ], device = 'cuda:0' )
Parameter containing :
tensor ([ 1.9902 , 2.3871 , 0.8984 , 1.2215 ], device = 'cuda:0' )ในทางทฤษฎีโมเดล Pomegranate สามารถใช้งานได้ในระบอบการปกครองแบบผสมหรือมีความแม่นยำต่ำเช่นเดียวกับโมดูล pytorch อื่น ๆ อย่างไรก็ตามเนื่องจากทับทิมใช้การดำเนินงานที่ซับซ้อนกว่าเครือข่ายประสาทส่วนใหญ่บางครั้งสิ่งนี้ไม่ได้ทำงานหรือช่วยในทางปฏิบัติเนื่องจากการดำเนินการเหล่านี้ยังไม่ได้รับการปรับให้เหมาะสมหรือดำเนินการในระบอบการปกครองที่มีความแม่นยำต่ำ ดังนั้นหวังว่าคุณสมบัตินี้จะมีประโยชน์มากขึ้นเมื่อเวลาผ่านไป
> >> X = torch . randn ( 100 , 4 )
> >> d = Normal ( covariance_type = 'diag' )
> >>
>> > with torch . autocast ( 'cuda' , dtype = torch . bfloat16 ):
> >> d . fit ( X ) การแจกแจงทับทิมเป็นทุกกรณีของ torch.nn.Module และการทำให้เป็นอนุกรมนั้นเหมือนกับรุ่น pytorch อื่น ๆ
ประหยัด:
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()], verbose = True )
> >> model . cuda ()
> >> model . fit ( X )
> >> torch . save ( model , "test.torch" )กำลังโหลด:
> >> model = torch . load ( "test.torch" )Note
torch.compileอยู่ภายใต้การพัฒนาที่ใช้งานอยู่โดยทีม Pytorch และอาจปรับปรุงอย่างรวดเร็ว สำหรับตอนนี้คุณอาจต้องผ่านcheck_data=Falseเมื่อเริ่มต้นโมเดลเพื่อหลีกเลี่ยงปัญหาความเข้ากันได้หนึ่ง
ใน Pytorch v2.0.0, torch.compile ได้รับการแนะนำให้รู้จักกับ wrapper ที่ยืดหยุ่นรอบเครื่องมือที่จะหลอมรวมการดำเนินงานเข้าด้วยกันใช้กราฟ CUDA และโดยทั่วไปพยายามที่จะลบคอขวด I/O ในการดำเนินการ GPU เนื่องจากคอขวดเหล่านี้มีความสำคัญอย่างยิ่งในการตั้งค่าข้อมูลขนาดเล็กถึงขนาดกลางผู้ใช้ทับทิมจำนวนมากที่ต้องเผชิญกับ torch.compile ดูเหมือนว่ามันจะมีค่าอย่างยิ่ง แทนที่จะกำหนดเป้าหมายทั้งแบบจำลองซึ่งส่วนใหญ่เพียงแค่รวบรวมวิธี forward คุณควรรวบรวมวิธีการแต่ละวิธีจากวัตถุของคุณ
# Create your object as normal
> >> mu = torch . exp ( torch . randn ( 100 ))
> >> d = Exponential ( mu ). cuda ()
# Create some data
> >> X = torch . exp ( torch . randn ( 1000 , 100 ))
> >> d . log_probability ( X )
# Compile the `log_probability` method!
> >> d . log_probability = torch . compile ( d . log_probability , mode = 'reduce-overhead' , fullgraph = True )
> >> d . log_probability ( X ) น่าเสียดายที่ฉันมีปัญหาในการรับ torch.compile ทำงานเมื่อมีการเรียกวิธีการในลักษณะที่ซ้อนกันเช่นเมื่อรวบรวมวิธี predict สำหรับแบบจำลองส่วนผสมซึ่งภายในนั้นเรียกใช้วิธี log_probability ของการแจกแจงแต่ละครั้ง ฉันพยายามจัดระเบียบรหัสในลักษณะที่หลีกเลี่ยงข้อผิดพลาดเหล่านี้ แต่เนื่องจากข้อความแสดงข้อผิดพลาดตอนนี้ทึบแสงฉันมีปัญหาบางอย่าง
ทับทิมรองรับการจัดการข้อมูลที่มีค่าที่หายไปผ่านวัตถุ torch.masked.MaskedTensor วัตถุ เพียงแค่เราต้องใส่หน้ากากเหนือค่าที่ขาดหายไป
> >> X = < your tensor with NaN for the missing values >
> >> mask = ~ torch . isnan ( X )
>> > X_masked = torch . masked . MaskedTensor ( X , mask = mask )
>> > d = Normal ( covariance_type = 'diag' ). fit ( X_masked )
>> > d . means
Parameter containing :
tensor ([ 0.2271 , 0.0290 , 0.0763 , 0.0135 ])อัลกอริทึมทั้งหมดในปัจจุบันถือว่าการขาดหายไปเป็นสิ่งที่จะเพิกเฉย ตัวอย่างเช่นเมื่อคำนวณค่าเฉลี่ยของคอลัมน์ที่มีค่าที่หายไปค่าเฉลี่ยจะเป็นค่าเฉลี่ยของค่าปัจจุบัน ค่าที่ขาดหายไปจะไม่ได้รับการกำหนดเนื่องจากการใส่ข้อมูลที่ไม่เหมาะสมสามารถอคติข้อมูลของคุณสร้างการประมาณการที่ไม่น่าจะบิดเบือนการแจกแจงและลดความแปรปรวน
เนื่องจากยังไม่มีการดำเนินการทั้งหมดสำหรับ MaskedTensors การแจกแจงต่อไปนี้ยังไม่ได้รับการสนับสนุนสำหรับค่าที่ขาดหายไป: Bernoulli, categorical, ปกติด้วยความแปรปรวนร่วมเต็มรูปแบบ, เครื่องแบบ
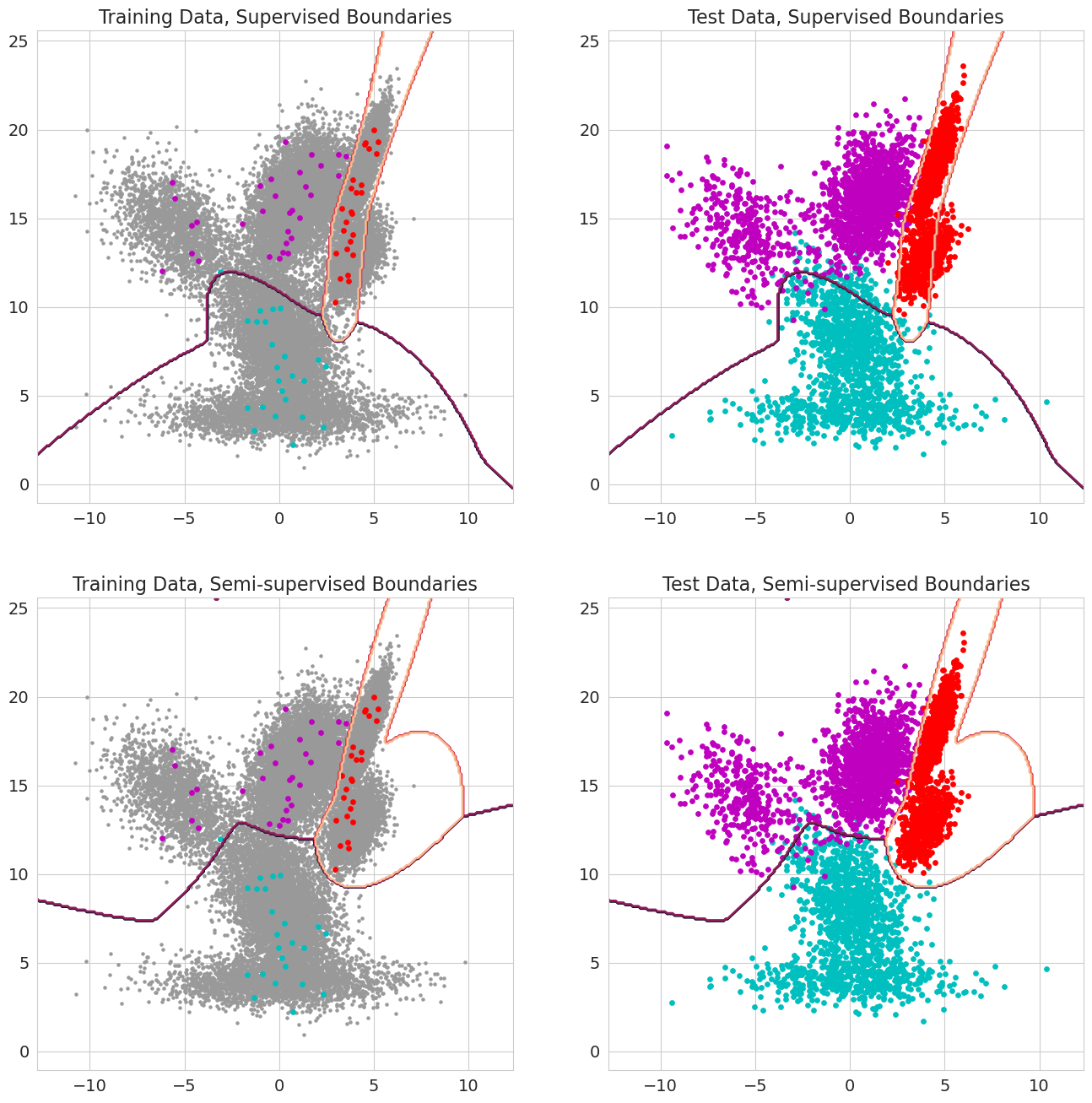
คุณสมบัติใหม่ในทับทิม v1.0.0 สามารถผ่านความน่าจะเป็นก่อนหน้านี้สำหรับการสังเกตแต่ละแบบจำลองผสม, ตัวแยกประเภทเบย์และรุ่นมาร์คอฟที่ซ่อนอยู่ สิ่งเหล่านี้เป็นความน่าจะเป็นก่อนหน้านี้ที่การสังเกตเป็นส่วนประกอบของโมเดลก่อนที่จะประเมินความน่าจะเป็นและควรอยู่ระหว่าง 0 ถึง 1 เมื่อค่าเหล่านี้รวมถึง 1.0 สำหรับการสังเกตมันได้รับการปฏิบัติเป็นฉลากเพราะความน่าจะเป็นไม่สำคัญอีกต่อไปในแง่ของการกำหนดรัฐ ดังนั้นเราสามารถใช้ความน่าจะเป็นก่อนหน้านี้เพื่อทำการฝึกอบรมที่ติดฉลากเมื่อการสังเกตแต่ละครั้งมี 1.0 สำหรับบางรัฐการเรียนรู้แบบกึ่งผู้ดูแลเมื่อชุดย่อยของการสังเกต (รวมถึงเมื่อลำดับจะถูกระบุไว้เพียงบางส่วนสำหรับโมเดล Markov ที่ซ่อนอยู่)