pomegranate
v1.1.0
重要なこと:ザクロv1.0.0は、サイトンの代わりにPytorchを計算バックエンドとして使用するザクロの概要の書き直しです。同じ機能がサポートされていますが、APIは大きく異なります。コードを書き換えるヘルプについては、チュートリアルと例フォルダーをご覧ください。
readthedocs |チュートリアル|例
ザクロは、すべてのモデルのモジュール式実装と処理によって定義される確率分布として定義される確率的モデリングのライブラリです。モジュラー実装により、通常の分布を混合モデルに簡単にドロップして、ガウス混合モデルを作成して、ガンマとポアソン分布を混合モデルにドロップして不均一な混合物を作成することができます。しかし、それだけではありません!各モデルは確率分布として扱われるため、ベイジアンネットワークは正規分布と同じくらい簡単に混合物にドロップでき、隠されたマルコフモデルをベイズ分類器にドロップしてシーケンス上に分類器を作成できます。一緒に、これら2つの設計の選択により、他の確率的モデリングパッケージには見られない柔軟性が可能になります。
最近、ザクロ(v1.0.0)がPytorchを使用してゼロから書き直され、時代遅れのCythonバックエンドを置き換えました。この書き直しは、私がBBソフトウェアエンジニアとして行った多くの悪いデザインの選択を修正する機会を与えてくれました。残念ながら、これらの変更の多くは後方互換性がなく、ワークフローを混乱させます。反対に、これらの変更により、ほとんどの方法が大幅に増加し、コードが改善および簡素化され、長年にわたってコミュニティによって提起された多くの問題を修正し、貢献しやすくなりました。以下にもっと書きましたが、あなたのコードが壊れていて、これがTL; DRであるため、今ここにいる可能性があります。
特別な開発助成金でこの作業をサポートするためのNumfocusへの特別な叫び。
pip install pomegranate
書き換え前に最後のCythonリリースが必要な場合は、 pip install pomegranate==0.14.8を使用してください。 V3の前にCythonのバージョンを手動でインストールする必要がある場合があります。
この書き直しは、4つの主な理由によって動機付けられました。
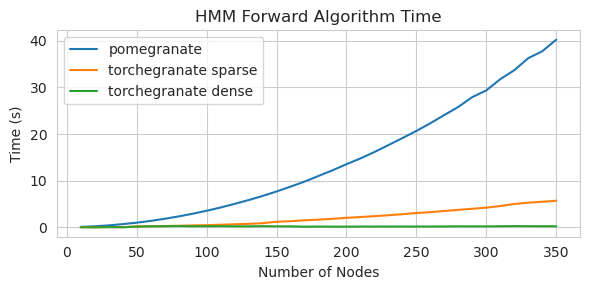
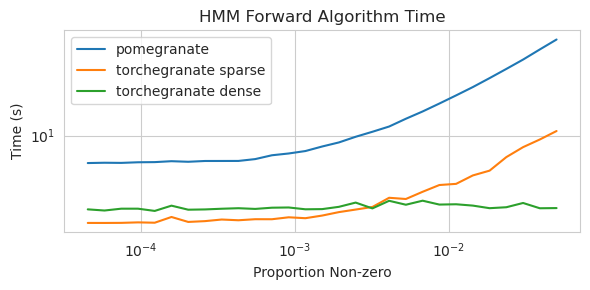
torch.nn.Moduleのインスタンスですtorch.masked.MaskedTensorオブジェクトを介してサポートされていますNormalDistributionがNormalなりますFactorGraphは現在、すべての予測とトレーニングの方法で、一流の市民としてサポートされていますDenseHMMおよびSparseHMMモデルに分割されており、 DenseHMMオブジェクトは本当に濃いグラフでは大幅に高速ですNaiveBayes BayesClassifierで冗長であるため、永久に削除されましたMarkovNetworkまだ実装されていませんザクロV1.0.0のほとんどのモデルと方法は、以前のバージョンのカウンターパートよりも速いです。これは通常、複雑さによってスケーリングされます。ここでは、小さなデータセット上の単純な分布のための小さなスピードアップのみが表示されますが、ビッグデータセットのより複雑なモデルでははるかに大きなスピードアップ(Hidden Markovモデルトレーニングやベイジアンネットワークの推論などがはるかに大きくなります。今のところ注目すべき例外は、チョウリウの木の建物以外のベイジアンネットワーク構造学習がまだ不完全であり、それほど高速ではないことです。以下の例では、 torchegranateザクロV1.0.0の発達に使用される一時的にリポジトリを指し、 pomegranateザクロV0.14.8を指します。
ここで何が起こっているのか誰が知っていますか?野生。
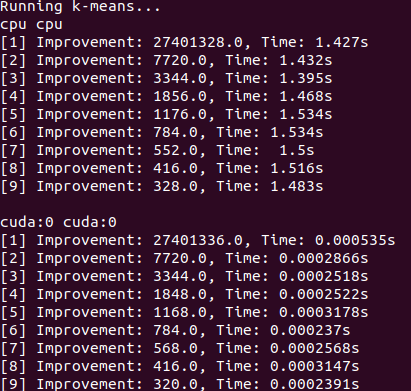
高密度遷移マトリックス(CPU)
スパース遷移マトリックス(CPU)
密な遷移マトリックスで125ノードモデルをトレーニングする
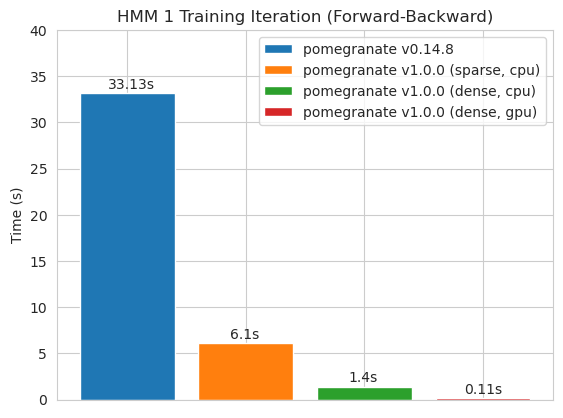
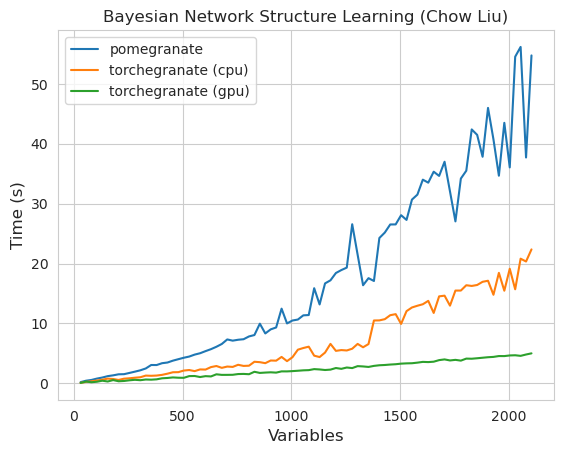
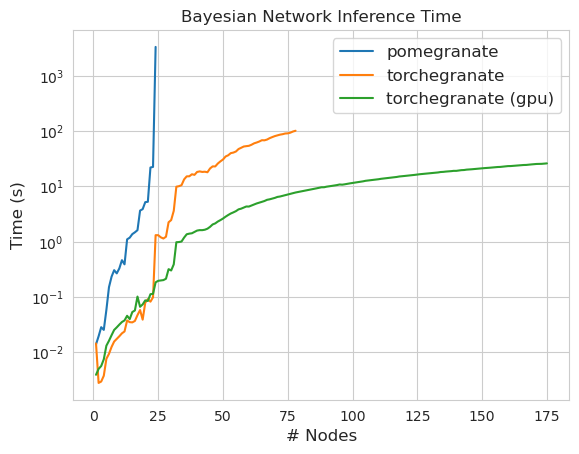
注コードの例については、チュートリアルフォルダーをご覧ください。
CythonバックエンドからPytorchバックエンドに切り替えることで、多数の機能が有効または拡張されました。書き直しはPytorchをめぐる薄いラッパーであるため、Pytorchの新機能がリリースされるため、私からの新しいリリースを必要とせずにザクロモデルに適用できます。
ザクロのすべての分布と方法には、GPUサポートがあります。各分布はtorch.nn.Moduleオブジェクトであるため、使用はpytorchで記述された他のコードと同じです。これは、モデルとデータの両方をユーザーがGPUに移動する必要があることを意味します。例えば:
> >> X = torch . exp ( torch . randn ( 50 , 4 ))
# Will execute on the CPU
> >> d = Exponential (). fit ( X )
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ])
# Will execute on a GPU
> >> d = Exponential (). cuda (). fit ( X . cuda ())
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ], device = 'cuda:0' )同様に、すべてのモデルは分布であるため、同様にGPUで使用できます。モデルをGPUに移動すると、それに関連付けられたすべてのモデル(分布など)もGPUに移動されます。
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()]). cuda ()
> >> model . fit ( X )
[ 1 ] Improvement : 1.26068115234375 , Time : 0.001134 s
[ 2 ] Improvement : 0.168121337890625 , Time : 0.001097 s
[ 3 ] Improvement : 0.037841796875 , Time : 0.001095 s
>> > model . distributions [ 0 ]. scales
Parameter containing :
>> > model . distributions [ 1 ]. scales
tensor ([ 0.9141 , 1.0835 , 2.7503 , 2.2475 ], device = 'cuda:0' )
Parameter containing :
tensor ([ 1.9902 , 2.3871 , 0.8984 , 1.2215 ], device = 'cuda:0' )ザクロモデルは、理論的には、他のPytorchモジュールと同じ混合または低精度レジームで動作することができます。ただし、ザクロはほとんどのニューラルネットワークよりも複雑な操作を使用しているため、これらの操作が低精度体制で最適化または実装されていないため、これは時々機能したり、実践的に役立ちません。したがって、この機能が時間とともにより便利になることを願っています。
> >> X = torch . randn ( 100 , 4 )
> >> d = Normal ( covariance_type = 'diag' )
> >>
>> > with torch . autocast ( 'cuda' , dtype = torch . bfloat16 ):
> >> d . fit ( X )ザクロの分布はすべてtorch.nn.Moduleのインスタンスであるため、シリアル化は他のPytorchモデルと同じです。
節約:
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()], verbose = True )
> >> model . cuda ()
> >> model . fit ( X )
> >> torch . save ( model , "test.torch" )読み込み:
> >> model = torch . load ( "test.torch" )
torch.compileは、 Pytorchチームによる積極的な開発中であり、急速に改善する可能性があります。とりあえず、モデルを初期化するときにcheck_data=Falseに渡す必要があるかもしれません。
Pytorch v2.0.0では、 torch.compile 、操作を融合し、CUDAグラフを使用し、一般的にGPU実行でI/Oボトルネックを削除するツールをめぐる柔軟なラッパーとして導入されました。これらのボトルネックは、多くのザクロのユーザーが直面している小規模から中程度のサイズのデータ設定で非常に重要である可能性があるため、 torch.compile非常に価値があるようです。主にforwardメソッドをコンパイルするだけのモデル全体をターゲットにするのではなく、オブジェクトから個々のメソッドをコンパイルする必要があります。
# Create your object as normal
> >> mu = torch . exp ( torch . randn ( 100 ))
> >> d = Exponential ( mu ). cuda ()
# Create some data
> >> X = torch . exp ( torch . randn ( 1000 , 100 ))
> >> d . log_probability ( X )
# Compile the `log_probability` method!
> >> d . log_probability = torch . compile ( d . log_probability , mode = 'reduce-overhead' , fullgraph = True )
> >> d . log_probability ( X )残念ながら、たとえば、各分布のlog_probabilityメソッドを呼び出す混合モデルのpredictメソッドをコンパイルするとき、メソッドがネストされた方法で呼び出されたときに、 torch.compile機能させるのが困難でした。これらのエラーの一部を回避する方法でコードを整理しようとしましたが、今のところエラーメッセージは不透明であるため、いくつかの困難がありました。
ザクロは、 torch.masked.MaskedTensorオブジェクトを介して欠損値を持つデータの取り扱いをサポートしています。簡単に言えば、欠落している値にマスクを置くだけです。
> >> X = < your tensor with NaN for the missing values >
> >> mask = ~ torch . isnan ( X )
>> > X_masked = torch . masked . MaskedTensor ( X , mask = mask )
>> > d = Normal ( covariance_type = 'diag' ). fit ( X_masked )
>> > d . means
Parameter containing :
tensor ([ 0.2271 , 0.0290 , 0.0763 , 0.0135 ])現在、すべてのアルゴリズムは、欠落を無視するものとして扱っています。例として、欠損値を持つ列の平均を計算する場合、平均は単に現在の値の平均値になります。不適切な代入はあなたのデータにバイアスをかけ、どの分布を歪めたか、分散を縮小する可能性が低いため、欠損値は帰属しません。
すべての操作がMaskedTensorsでまだ利用可能であるわけではないため、次の分布は欠損値についてまだサポートされていません:Bernoulli、カテゴリー、完全な共分散、ユニフォーム、ユニフォーム
ザクロv1.0.0の新機能は、混合モデル、ベイズ分類器、および隠されたマルコフモデルの各観測の事前の確率に合格できることです。これらは、観測が尤度を評価する前にモデルのコンポーネントに属するという事前の確率であり、0〜1の範囲です。これらの値には観測のために1.0が含まれる場合、状態にその観測を割り当てるという点で尤度がもはや重要ではないため、ラベルとして扱われます。したがって、これらの以前の確率を使用して、各観測には、観測値のサブセット(シーケンスが隠されたマルコフモデルに対して部分的にラベル付けされている場合を含む)、または値が0〜1の間のより洗練された形式の場合を含む、一部の状態、半監視学習の1.0がある場合、ラベル付きトレーニングを行うことができます。