pomegranate
v1.1.0
Примечание Важно: гранат v1.0.0-это основополагающий переписывание граната с использованием pytorch в качестве вычислительного бэкэнда вместо цинтона. Хотя такая же функциональность поддерживается, API значительно отличается. Пожалуйста, смотрите учебные пособия и папки примеров для переписывания вашего кода.
Readthedocs | Учебные пособия | Примеры
Гранат - это библиотека для вероятностного моделирования, определяемого его модульной реализацией и обработкой всех моделей как распределения вероятностей. Модульная реализация позволяет легко сбрасывать нормальные распределения в модель смеси, чтобы создать гауссовую модель смеси так же легко, как сбрасывать гамма и распределение Пуассона в модель смеси, чтобы создать гетерогенную смесь. Но это еще не все! Поскольку каждая модель рассматривается как распределение вероятностей, байесовские сети можно сбрасывать в смесь так же легко, как обычное распределение, а скрытые модели Маркова могут быть сброшены в классификаторы Байеса, чтобы сделать классификатор по последовательностям. Вместе эти два варианта дизайна обеспечивают гибкость, не видную ни в каком другом вероятностном пакете моделирования.
Недавно гранат (v1.0.0) был переписан с нуля с использованием Pytorch для замены устаревшего бэкэнда цинтона. Этот переписываний дал мне возможность исправить множество плохих дизайнерских вариантов, которые я сделал в качестве инженера программного обеспечения BB. К сожалению, многие из этих изменений не совместимы назад и будут нарушать рабочие процессы. С другой стороны, эти изменения значительно ускорили большинство методов, улучшили и упростили код, исправили многие проблемы, поднятые сообществом на протяжении многих лет, и значительно облегчил вклад. Я написал больше ниже, но вы, вероятно, здесь сейчас, потому что ваш код сломлен, и это TL; DR.
Особое крик Numfocus за поддержку этой работы с помощью специального гранта на разработку.
pip install pomegranate
Если вам нужен последний выпуск цинтона перед переписыванием, используйте pip install pomegranate==0.14.8 . Возможно, вам потребуется вручную установить версию цинтона до V3.
Это переписывание было мотивировано четырьмя основными причинами:
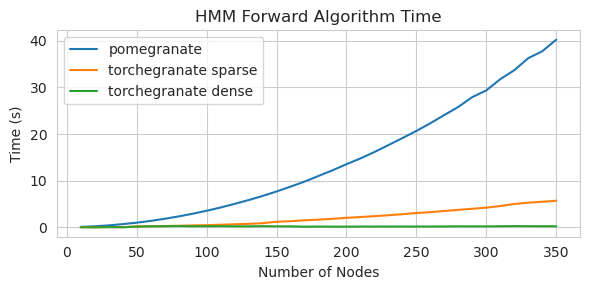
torch.nn.Moduletorch.masked.MaskedTensorNormalDistribution теперь NormalFactorGraph в настоящее время поддерживается как первоклассные граждане, со всеми методами прогнозирования и обученияDenseHMM и SparseHMM , которые различаются по тому, как кодируется матрица перехода, а объекты DenseHMM значительно быстрее на действительно плотных графикахNaiveBayes был навсегда удален, так как он избыточный с BayesClassifierMarkovNetwork еще не реализована Большинство моделей и методов в гранате v1.0.0 быстрее, чем их аналоги в более ранних версиях. Как правило, это масштабируется по сложности, когда можно увидеть только небольшие ускорения для простых распределений на небольших наборах данных, но гораздо более крупные ускорения для более сложных моделей на больших наборах данных, например, подготовку модели Маркова или вывод байесовской сети. На данный момент заметным исключением является то, что обучение структуре байесовской сети, кроме здания деревьев Чоу-Лиу, все еще неполно и не намного быстрее. В приведенных ниже примерах torchegranate относится к временно репозиторию, используемому для разработки граната V1.0.0, а pomegranate относится к гранату V0.14.8.
Кто знает, что здесь происходит? Дикий.
Матрица плотного перехода (ЦП)
Разреженная матрица перехода (ЦП)
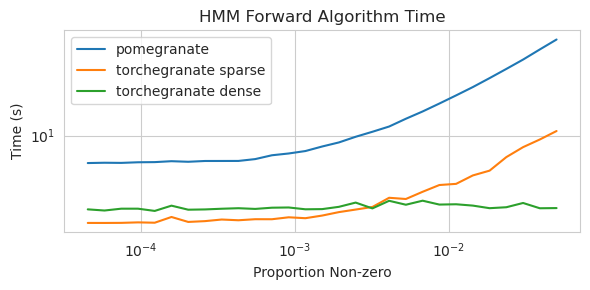
Обучение модели 125 узлов с плотной матрицей перехода
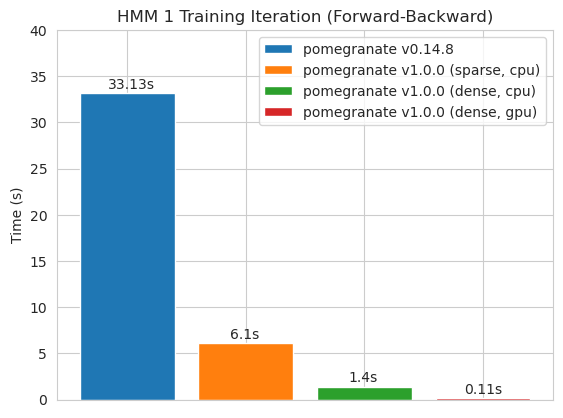
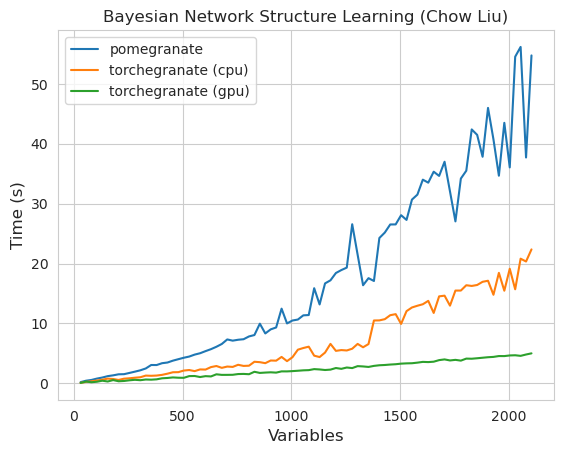
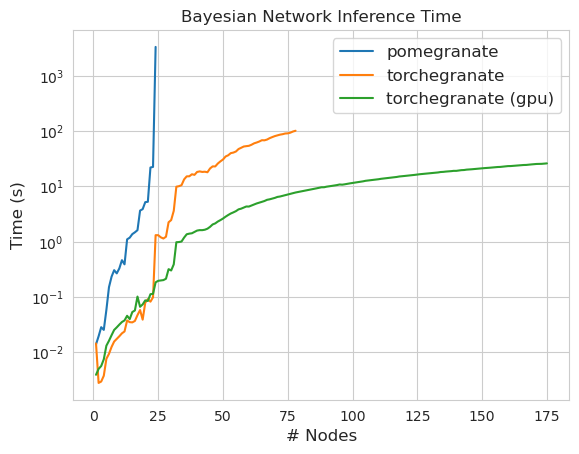
ПРИМЕЧАНИЕ, пожалуйста, см. В папке учебных пособий для примеров кода.
Переключение от бэкэнда цинтона на бэкэнд Pytorch позволил или расширило большое количество функций. Поскольку перезапись представляет собой тонкую обертку над Pytorch, поскольку новые функции выпускаются для Pytorch, они могут быть применены к моделям граната без необходимости нового выпуска от меня.
Все распределения и методы в гранате теперь имеют поддержку графического процессора. Поскольку каждое распределение является объектом torch.nn.Module , использование идентично другому коду, написанному в Pytorch. Это означает, что как модель, так и данные должны быть перемещены в GPU пользователем. Например:
> >> X = torch . exp ( torch . randn ( 50 , 4 ))
# Will execute on the CPU
> >> d = Exponential (). fit ( X )
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ])
# Will execute on a GPU
> >> d = Exponential (). cuda (). fit ( X . cuda ())
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ], device = 'cuda:0' )Аналогичным образом, все модели представляют собой распределения, и поэтому они могут использоваться на графическом процессоре. Когда модель перемещается в GPU, все связанные с ней модели (например, распределения) также перемещаются в GPU.
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()]). cuda ()
> >> model . fit ( X )
[ 1 ] Improvement : 1.26068115234375 , Time : 0.001134 s
[ 2 ] Improvement : 0.168121337890625 , Time : 0.001097 s
[ 3 ] Improvement : 0.037841796875 , Time : 0.001095 s
>> > model . distributions [ 0 ]. scales
Parameter containing :
>> > model . distributions [ 1 ]. scales
tensor ([ 0.9141 , 1.0835 , 2.7503 , 2.2475 ], device = 'cuda:0' )
Parameter containing :
tensor ([ 1.9902 , 2.3871 , 0.8984 , 1.2215 ], device = 'cuda:0' )Модели граната, теоретически, могут работать в тех же смешанных или низких режимах, что и другие модули питорха. Однако, поскольку гранат использует более сложные операции, чем большинство нейронных сетей, это иногда не работает или не помогает на практике, потому что эти операции не были оптимизированы или реализованы в режиме низкого определения. Итак, надеюсь, эта функция станет более полезной с течением времени.
> >> X = torch . randn ( 100 , 4 )
> >> d = Normal ( covariance_type = 'diag' )
> >>
>> > with torch . autocast ( 'cuda' , dtype = torch . bfloat16 ):
> >> d . fit ( X ) Распределения граната - все это примеры torch.nn.Module , и поэтому сериализация такая же, как и любая другая модель Pytorch.
Сохранение:
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()], verbose = True )
> >> model . cuda ()
> >> model . fit ( X )
> >> torch . save ( model , "test.torch" )Загрузка:
> >> model = torch . load ( "test.torch" )Примечание
torch.compileнаходится в активной разработке команды Pytorch и может быстро улучшить. На данный момент вам может потребоваться пройти вcheck_data=Falseпри инициализации моделей, чтобы избежать одной проблемы совместимости.
В Pytorch v2.0.0 torch.compile был представлен в качестве гибкой обертки вокруг инструментов, которые объединят работу вместе, используют графики CUDA и, как правило, пытаются удалить узкие места ввода/вывода в выполнении графического процессора. Поскольку эти узкие места могут быть чрезвычайно значимыми в настройках данных размером с малого и среднего класса, с которыми сталкиваются пользователи граната, torch.compile кажется, что это будет чрезвычайно ценным. Вместо того, чтобы ориентироваться на целые модели, которые в основном просто собирают метод forward , вы должны составлять отдельные методы из ваших объектов.
# Create your object as normal
> >> mu = torch . exp ( torch . randn ( 100 ))
> >> d = Exponential ( mu ). cuda ()
# Create some data
> >> X = torch . exp ( torch . randn ( 1000 , 100 ))
> >> d . log_probability ( X )
# Compile the `log_probability` method!
> >> d . log_probability = torch . compile ( d . log_probability , mode = 'reduce-overhead' , fullgraph = True )
> >> d . log_probability ( X ) К сожалению, у меня были трудности с тем, чтобы заставить torch.compile работать, когда методы вызываются вложенным образом, например, при составлении метода predict для модели смеси, которая внутри нее вызывает метод log_probability каждого распределения. Я пытался организовать код таким образом, чтобы избежать некоторых из этих ошибок, но потому, что сообщения об ошибках сейчас непрозрачны, у меня возникли трудности.
Гранат поддерживает обработку данных с отсутствующими значениями через torch.masked.MaskedTensor объектов. Проще говоря, нужно просто положить маску на пропавшие значения.
> >> X = < your tensor with NaN for the missing values >
> >> mask = ~ torch . isnan ( X )
>> > X_masked = torch . masked . MaskedTensor ( X , mask = mask )
>> > d = Normal ( covariance_type = 'diag' ). fit ( X_masked )
>> > d . means
Parameter containing :
tensor ([ 0.2271 , 0.0290 , 0.0763 , 0.0135 ])Все алгоритмы в настоящее время рассматривают пропавность как что -то, чтобы игнорировать. В качестве примера, при расчете среднего значения столбца с пропущенными значениями среднее будет просто средним значением настоящих значений. Пропущенные значения не вменены, потому что ненадлежащее вменение может смещать ваши данные, дать маловероятные оценки, которые искажают распределения, а также уменьшают дисперсию.
Поскольку не все операции еще доступны для маскированных денсоров, следующие распределения еще не поддерживаются для пропущенных значений: Бернулли, категориальная, нормальная с полной ковариацией, униформой
Новая функция в гранате v1.0.0 может проходить в предыдущих вероятностях для каждого наблюдения за моделями смесей, классификаторов Байеса и скрытых моделей Маркова. Это предшествующая вероятность того, что наблюдение принадлежит компоненту модели перед оценкой вероятности и должно варьироваться от 0 до 1. Когда эти значения включают 1,0 для наблюдения, оно рассматривается как метка, поскольку вероятность больше не имеет значения с точки зрения назначения этого наблюдения в состояние. Следовательно, можно использовать эти предыдущие вероятности для выполнения маркированных тренировок, когда каждое наблюдение имеет 1,0 для некоторого состояния, полупрофильное обучение, когда подмножество наблюдений (включая последовательности только частично помечены для моделей скрытых марков) или более сложных форм веса, когда значения находятся от 0 до 1.