pomegranate
v1.1.0
ملاحظة مهمة: الرمان V1.0.0 هو إعادة كتابة من الرمان باستخدام Pytorch كواجهة خلفية حسابي بدلاً من Cython. على الرغم من دعم الوظيفة نفسها ، إلا أن واجهة برمجة التطبيقات تختلف اختلافًا كبيرًا. يرجى الاطلاع على مجلدات البرامج التعليمية والأمثلة للمساعدة في إعادة كتابة التعليمات البرمجية الخاصة بك.
readthedocs | دروس | أمثلة
Pomegranate هي مكتبة للنمذجة الاحتمالية المحددة من خلال تنفيذها المعياري وعلاجها لجميع النماذج باعتبارها توزيعات الاحتمالات. يسمح التنفيذ المعياري للمرء بسهولة بإسقاط التوزيعات العادية في نموذج الخليط لإنشاء نموذج خليط غاوسي بنفس السهولة مثل إسقاط غاما وتوزيع Poisson في نموذج الخليط لإنشاء خليط غير متجانس. لكن هذا ليس كل شيء! نظرًا لأن كل نموذج يتم التعامل معه على أنه توزيع احتمال ، يمكن إسقاط شبكات Bayesian في خليط بنفس السهولة مثل التوزيع العادي ، ويمكن إسقاط نماذج Markov المخفية إلى مصنفات Bayes لصنع المصنف على التسلسلات. معا ، يمكّن هذان الخياران للتصميم من المرونة التي لم يتم رؤيتها في أي حزمة نمذجة احتمالية أخرى.
في الآونة الأخيرة ، أعيد كتابة الرمان (v1.0.0) من الألف إلى الياء باستخدام Pytorch لاستبدال الواجهة الخلفية Cython القديمة. أعطتني إعادة الكتابة هذه فرصة لإصلاح العديد من خيارات التصميم السيئة التي قمت بها كمهندس برمجيات BB. لسوء الحظ ، فإن العديد من هذه التغييرات ليست متوافقة مع الوراء وسوف تعطل سير العمل. على الجانب الآخر ، تسببت هذه التغييرات في معظم الأساليب ، وتحسين وتبسيط الرمز ، وحدد العديد من المشكلات التي أثارها المجتمع على مر السنين ، وجعلت من الأسهل بكثير المساهمة. لقد كتبت المزيد أدناه ، لكن من المحتمل أن تكون هنا الآن لأن رمزك مكسور وهذا هو TL ؛ DR.
صيحة خاصة إلى NumFocus لدعم هذا العمل مع منحة تطوير خاصة.
pip install pomegranate
إذا كنت بحاجة إلى إصدار Cython الأخير قبل إعادة الكتابة ، فاستخدم pip install pomegranate==0.14.8 . قد تحتاج إلى تثبيت إصدار من Cython يدويًا قبل V3.
كانت هذه إعادة الكتابة مدفوعة بأربعة أسباب رئيسية:
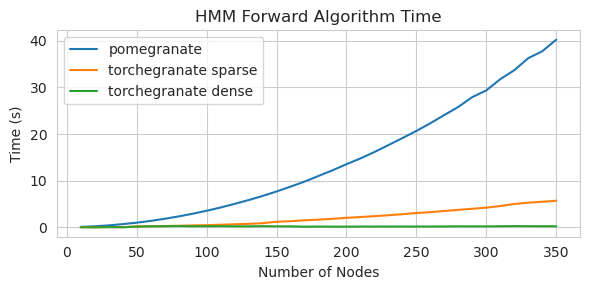
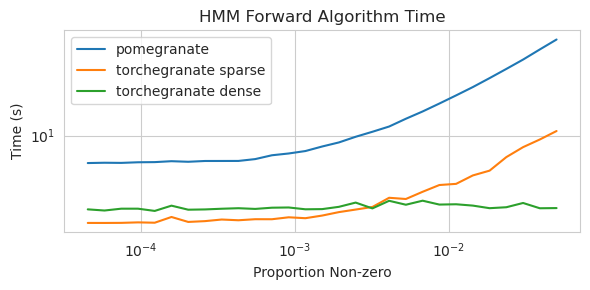
torch.nn.Moduletorch.masked.MaskedTensor ObjectsNormalDistribution Normal الآنFactorGraph كمواطنين من الدرجة الأولى ، مع كل أساليب التنبؤ والتدريبDenseHMM و SparseHMM التي تختلف في كيفية ترميز مصفوفة الانتقال ، مع وجود كائنات DenseHMM أسرع بكثير على الرسوم البيانية الكثيفة حقًاNaiveBayes بشكل دائم لأنه زائد مع BayesClassifierMarkovNetwork بعد معظم النماذج والأساليب في الرمان V1.0.0 أسرع من نظرائها في الإصدارات السابقة. يتميز هذا بشكل عام بالتعقيد ، حيث يرى المرء فقط سرعات صغيرة للتوزيعات البسيطة على مجموعات البيانات الصغيرة ولكن سرعات أكبر بكثير لنماذج أكثر تعقيدًا على مجموعات البيانات الكبيرة ، مثل تدريب نموذج ماركوف المخفي أو استنتاج شبكة بايزي. الاستثناء الملحوظ في الوقت الحالي هو أن تعلم بنية الشبكة Bayesian ، بخلاف بناء شجرة Chow-Liu ، لا يزال غير مكتمل وليس أسرع بكثير. في الأمثلة أدناه ، يشير torchegranate إلى المستودع المؤقت المستخدم لتطوير الرمان V1.0.0 ويشير pomegranate إلى الرمان V0.14.8.
من يدري ماذا يحدث هنا؟ بري.
مصفوفة انتقالية كثيفة (وحدة المعالجة المركزية)
مصفوفة الانتقال المتفرقة (وحدة المعالجة المركزية)
تدريب نموذج عقدة 125 مع مصفوفة انتقالية كثيفة
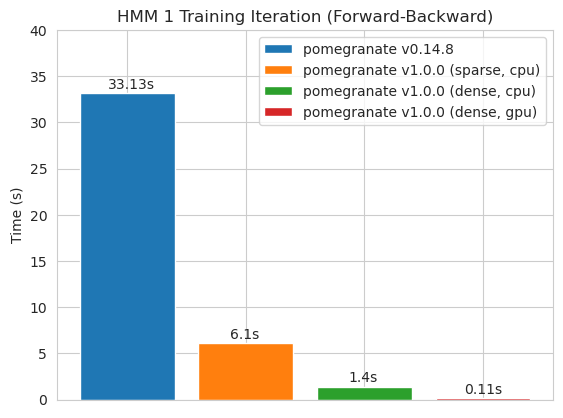
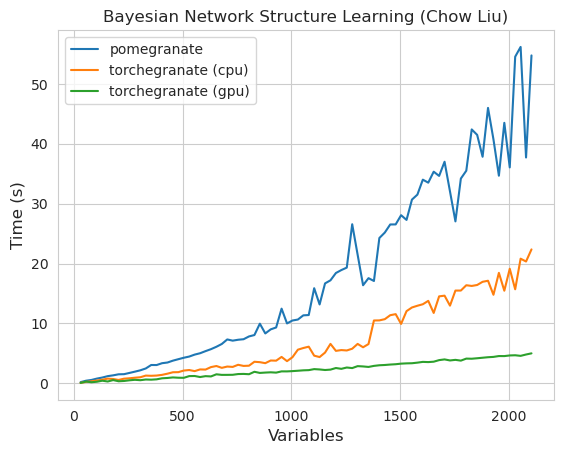
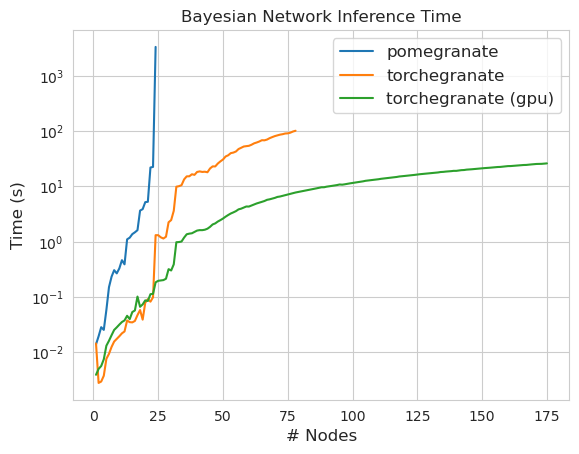
ملاحظة يرجى الاطلاع على مجلد الدروس لأمثلة رمز.
إن التحول من الواجهة الخلفية Cython إلى الخلفية Pytorch قد مكّن أو قام بتوسيع عدد كبير من الميزات. نظرًا لأن إعادة الكتابة عبارة عن غلاف رفيع فوق Pytorch ، حيث يتم إصدار الميزات الجديدة لـ Pytorch ، يمكن تطبيقها على نماذج الرمان دون الحاجة إلى إصدار جديد مني.
جميع التوزيعات والأساليب في الرمان لديها الآن دعم GPU. لأن كل توزيع هو كائن torch.nn.Module ، فإن الاستخدام مطابق للرمز الآخر المكتوب في Pytorch. هذا يعني أنه يجب نقل كل من النموذج والبيانات إلى وحدة معالجة الرسومات من قبل المستخدم. على سبيل المثال:
> >> X = torch . exp ( torch . randn ( 50 , 4 ))
# Will execute on the CPU
> >> d = Exponential (). fit ( X )
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ])
# Will execute on a GPU
> >> d = Exponential (). cuda (). fit ( X . cuda ())
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ], device = 'cuda:0' )وبالمثل ، فإن جميع النماذج عبارة عن توزيعات ، وبالتالي يمكن استخدامها على وحدة معالجة الرسومات بالمثل. عندما يتم نقل نموذج إلى وحدة معالجة الرسومات ، يتم نقل جميع النماذج المرتبطة به (على سبيل المثال) إلى وحدة معالجة الرسومات.
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()]). cuda ()
> >> model . fit ( X )
[ 1 ] Improvement : 1.26068115234375 , Time : 0.001134 s
[ 2 ] Improvement : 0.168121337890625 , Time : 0.001097 s
[ 3 ] Improvement : 0.037841796875 , Time : 0.001095 s
>> > model . distributions [ 0 ]. scales
Parameter containing :
>> > model . distributions [ 1 ]. scales
tensor ([ 0.9141 , 1.0835 , 2.7503 , 2.2475 ], device = 'cuda:0' )
Parameter containing :
tensor ([ 1.9902 , 2.3871 , 0.8984 , 1.2215 ], device = 'cuda:0' )يمكن أن تعمل نماذج الرمان ، من الناحية النظرية ، في نفس الأنظمة المختلطة أو منخفضة الدقة مثل وحدات Pytorch الأخرى. ومع ذلك ، نظرًا لأن الرمان يستخدم عمليات أكثر تعقيدًا من معظم الشبكات العصبية ، فإن هذا في بعض الأحيان لا يعمل أو يساعد في الممارسة العملية لأن هذه العمليات لم يتم تحسينها أو تنفيذها في نظام الدقة المنخفض. لذلك ، نأمل أن تصبح هذه الميزة أكثر فائدة مع مرور الوقت.
> >> X = torch . randn ( 100 , 4 )
> >> d = Normal ( covariance_type = 'diag' )
> >>
>> > with torch . autocast ( 'cuda' , dtype = torch . bfloat16 ):
> >> d . fit ( X ) توزيعات الرمان كلها مثيلات من torch.nn.Module وبالتالي فإن التسلسل هو نفسه أي نموذج pytorch آخر.
توفير:
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()], verbose = True )
> >> model . cuda ()
> >> model . fit ( X )
> >> torch . save ( model , "test.torch" )تحميل:
> >> model = torch . load ( "test.torch" )ملاحظة
torch.compileتحت التطوير النشط من قبل فريق Pytorch وقد يتحسن بسرعة. في الوقت الحالي ، قد تحتاج إلى المرور فيcheck_data=Falseعند تهيئة النماذج لتجنب مشكلة توافق واحدة.
في Pytorch v2.0.0 ، تم تقديم torch.compile كركب مرن حول الأدوات التي من شأنها دمج العمليات معًا ، وتستخدم الرسوم البيانية CUDA ، وحاول بشكل عام إزالة الاختناقات I/O في تنفيذ GPU. نظرًا لأن هذه الاختناقات يمكن أن تكون مهمة للغاية في إعدادات البيانات الصغيرة إلى المتوسطة الحجم التي يواجهها العديد من مستخدمي الرمان ، يبدو أن torch.compile سيكون ذا قيمة كبيرة. بدلاً من استهداف النماذج بأكملها ، والتي تجمع في الغالب الطريقة forward ، يجب عليك تجميع الأساليب الفردية من كائناتك.
# Create your object as normal
> >> mu = torch . exp ( torch . randn ( 100 ))
> >> d = Exponential ( mu ). cuda ()
# Create some data
> >> X = torch . exp ( torch . randn ( 1000 , 100 ))
> >> d . log_probability ( X )
# Compile the `log_probability` method!
> >> d . log_probability = torch . compile ( d . log_probability , mode = 'reduce-overhead' , fullgraph = True )
> >> d . log_probability ( X ) لسوء الحظ ، لقد واجهت صعوبة في الحصول على torch.compile للعمل عندما يتم استدعاء الأساليب بطريقة متداخلة ، على سبيل المثال ، عند تجميع طريقة predict بنموذج الخليط الذي يدعو داخله ، طريقة log_probability لكل توزيع. لقد حاولت تنظيم الكود بطريقة تتجنب بعض هذه الأخطاء ، ولكن لأن رسائل الخطأ في الوقت الحالي غير شفافة ، واجهت بعض الصعوبة.
يدعم الرمان معالجة البيانات مع قيم مفقودة من خلال torch.masked.MaskedTensor كائنات. ببساطة ، يحتاج المرء إلى وضع قناع على القيم المفقودة.
> >> X = < your tensor with NaN for the missing values >
> >> mask = ~ torch . isnan ( X )
>> > X_masked = torch . masked . MaskedTensor ( X , mask = mask )
>> > d = Normal ( covariance_type = 'diag' ). fit ( X_masked )
>> > d . means
Parameter containing :
tensor ([ 0.2271 , 0.0290 , 0.0763 , 0.0135 ])جميع الخوارزميات تعامل حاليًا في فقدانها كشيء لتجاهله. على سبيل المثال ، عند حساب متوسط العمود ذي القيم المفقودة ، سيكون الوسط ببساطة متوسط القيمة للقيم الحالية. لا يتم احتساب القيم المفقودة لأن التضمين غير السليم يمكن أن يحيز بياناتك ، ويحدث تقديرات غير محتملة تشوه التوزيعات ، وكذلك تقليص التباين.
نظرًا لأن جميع العمليات غير متوفرة بعد لـ MaskedTensors ، فإن التوزيعات التالية لم يتم دعمها بعد للقيم المفقودة: Bernoulli ، فئر ، طبيعي مع التباين الكامل ، الزي الرسمي
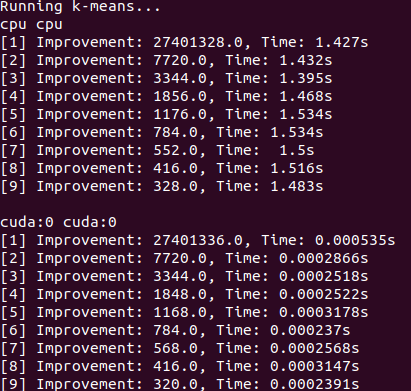
ميزة جديدة في الرمان V1.0.0 هي قادرة على المرور في الاحتمالات السابقة لكل ملاحظة لنماذج الخليط ، مصنفات بايز ، ونماذج ماركوف المخفية. هذه هي الاحتمال المسبق أن تكون الملاحظة تنتمي إلى مكون من النموذج قبل تقييم الاحتمالية ويجب أن تتراوح بين 0 و 1. عندما تتضمن هذه القيم 1.0 للمراقبة ، يتم التعامل معها كتسمية ، لأن الاحتمال لم يعد يهم من حيث تعيين تلك الملاحظة إلى الدولة. وبالتالي ، يمكن للمرء استخدام هذه الاحتمالات السابقة للقيام بالتدريب المسمى عندما يكون لكل ملاحظة 1.0 لبعض الحالة ، أو التعلم شبه الخاضع للإشراف عندما تكون مجموعة فرعية من الملاحظات (بما في ذلك عندما يتم تصنيف التسلسلات جزئيًا فقط لنماذج ماركوف المخفية) ، أو أشكال أكثر تطوراً من الترجيح عندما تكون القيم بين 0 و 1.