pomegranate
v1.1.0
참고 : Pomegranate v1.0.0은 Pytorch를 Cython 대신 계산 백엔드로 사용하여 Pomegranate의 접지 재 작성입니다. 동일한 기능이 지원되지만 API는 크게 다릅니다. 코드를 다시 작성하는 데 도움이되는 자습서 및 예제 폴더를 참조하십시오.
Readthedocs | 튜토리얼 | 예
석류는 모든 모델의 모듈 식 구현 및 처리에 의해 정의 된 확률 론적 모델링을위한 라이브러리입니다. 모듈 식 구현을 통해 정규 분포를 혼합 모델로 쉽게 삭제하여 가우스 혼합물 모델을 감마를 삭제하는 것만 큼 쉽게 가우스 혼합물 모델을 생성하고 이종 혼합물을 생성하기 위해 감마 및 포아송 분포를 쉽게 만들 수 있습니다. 그러나 그게 전부는 아닙니다! 각 모델은 확률 분포로 취급되기 때문에 베이지안 네트워크는 정규 분포만큼 쉽게 혼합물로 삭제 될 수 있으며 숨겨진 Markov 모델을 베이 즈 분류기로 삭제하여 시퀀스를 통해 분류기를 만들 수 있습니다. 이 두 가지 설계 선택은 함께 다른 확률 모델링 패키지에서 볼 수없는 유연성을 가능하게합니다.
최근에, 석류 (v1.0.0)는 구식 Cython 백엔드를 대체하기 위해 Pytorch를 사용하여 처음부터 다시 작성되었습니다. 이 다시 쓰기는 BB 소프트웨어 엔지니어로 만든 많은 나쁜 디자인 선택을 수정할 수있는 기회를주었습니다. 불행히도, 이러한 변경 중 많은 부분이 거꾸로 호환되지 않으며 워크 플로를 방해합니다. 반대로, 이러한 변화는 대부분의 방법을 크게 증가 시켰으며, 코드를 개선하고 단순화했으며, 수년에 걸쳐 커뮤니티가 제기 한 많은 문제를 해결하고 기여하기가 훨씬 쉬워졌습니다. 아래에 더 많이 썼지 만 코드가 깨졌고 이것이 TL; DR이기 때문에 지금 여기에있을 것입니다.
특별 개발 보조금 으로이 작업을 지원하기위한 Numfocus에 특별한 외침.
pip install pomegranate
다시 쓰기 전에 마지막 Cython 릴리스가 필요한 경우 pip install pomegranate==0.14.8 사용하십시오. v3 전에 Cython 버전을 수동으로 설치해야 할 수도 있습니다.
이 재 작성은 네 가지 주요 이유에 의해 동기가 부여되었습니다.
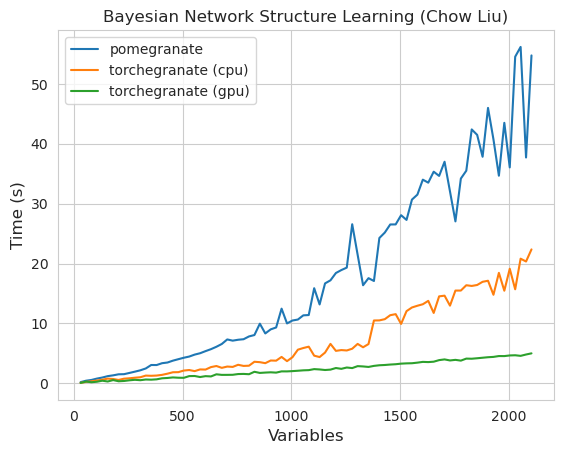
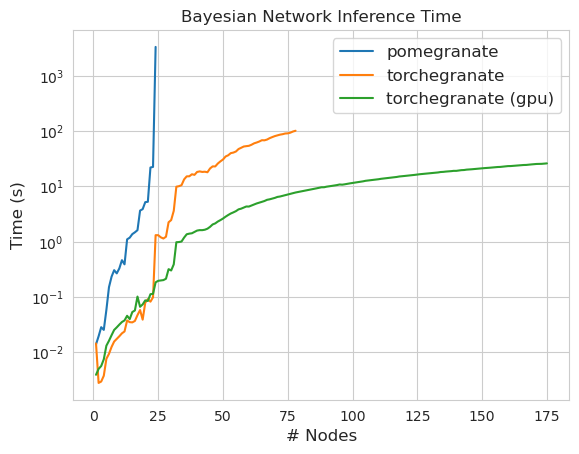
torch.nn.Module 의 인스턴스입니다.torch.masked.MaskedTensor 객체를 통해 지원됩니다NormalDistribution Normal 되도록FactorGraph 는 이제 모든 예측 및 훈련 방법으로 일류 시민으로 지원됩니다.DenseHMM 및 SparseHMM 모델로 나뉘어져 전이 행렬이 인코딩되는 방식이 다르고 DenseHMM 객체는 진정 조밀 한 그래프에서 상당히 빠릅니다.NaiveBayes BayesClassifier 로 중복되므로 영구적으로 제거되었습니다.MarkovNetwork 아직 구현되지 않았습니다 석류 V1.0.0의 대부분의 모델과 방법은 이전 버전의 상대보다 빠릅니다. 이것은 일반적으로 복잡성으로 인해 소규모 데이터 세트에서 간단한 분포에 대한 작은 속도 만 보이지만 빅 데이터 세트에서 더 복잡한 모델에 대한 훨씬 더 큰 속도와 같은 소속이 있습니다. 현재 주목할만한 예외는 Chow-Liu 트리 빌딩 이외의 베이지안 네트워크 구조 학습이 여전히 불완전하고 훨씬 빠르지 않다는 것입니다. 아래의 예에서, torchegranate 석류 v1.0.0을 개발하는 데 사용되는 일시적으로 저장소를 지칭하고 pomegranate 석류 V0.14.8을 나타냅니다.
여기서 무슨 일이 일어나고 있는지 누가 알 겠어요? 야생의.
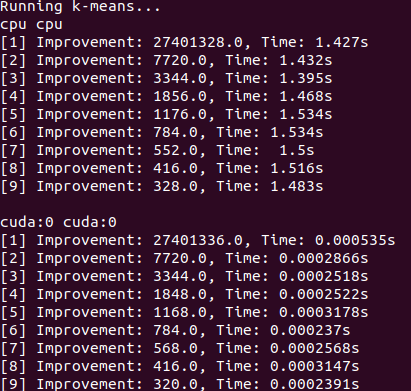
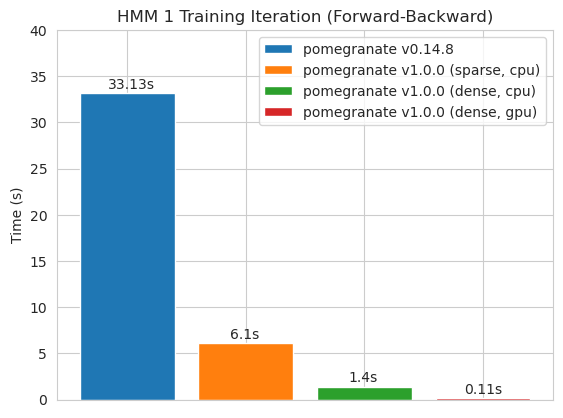
밀도가 높은 전환 매트릭스 (CPU)
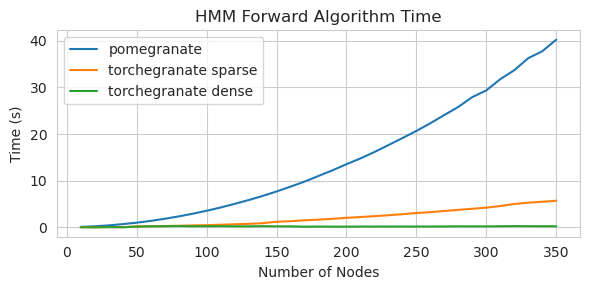
희소 전이 행렬 (CPU)
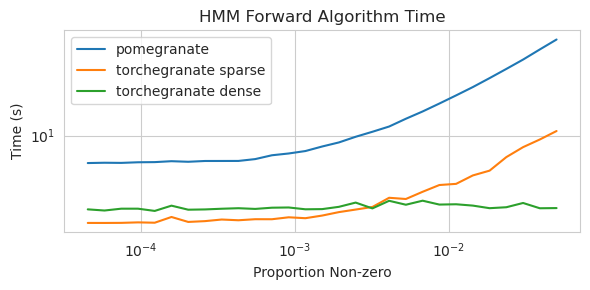
조밀 한 전환 매트릭스로 125 노드 모델 훈련
참고 코드 예제는 튜토리얼 폴더를 참조하십시오.
Cython 백엔드에서 Pytorch 백엔드로 전환하면 많은 기능이 가능하거나 확장되었습니다. 다시 쓰기는 Pytorch에 대한 얇은 래퍼이기 때문에 Pytorch를 위해 새로운 기능이 출시되므로 새로운 릴리스가 필요없이 석류 모델에 적용 할 수 있습니다.
석류의 모든 분포와 방법은 이제 GPU 지원을받습니다. 각 분포는 torch.nn.Module 이기 때문에 사용은 Pytorch로 작성된 다른 코드와 동일합니다. 이는 모델과 데이터가 사용자가 GPU로 이동해야 함을 의미합니다. 예를 들어:
> >> X = torch . exp ( torch . randn ( 50 , 4 ))
# Will execute on the CPU
> >> d = Exponential (). fit ( X )
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ])
# Will execute on a GPU
> >> d = Exponential (). cuda (). fit ( X . cuda ())
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ], device = 'cuda:0' )마찬가지로 모든 모델은 분포이므로 GPU에서 유사하게 사용할 수 있습니다. 모델이 GPU로 이동하면 IT와 관련된 모든 모델 (예 : 분포)도 GPU로 이동합니다.
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()]). cuda ()
> >> model . fit ( X )
[ 1 ] Improvement : 1.26068115234375 , Time : 0.001134 s
[ 2 ] Improvement : 0.168121337890625 , Time : 0.001097 s
[ 3 ] Improvement : 0.037841796875 , Time : 0.001095 s
>> > model . distributions [ 0 ]. scales
Parameter containing :
>> > model . distributions [ 1 ]. scales
tensor ([ 0.9141 , 1.0835 , 2.7503 , 2.2475 ], device = 'cuda:0' )
Parameter containing :
tensor ([ 1.9902 , 2.3871 , 0.8984 , 1.2215 ], device = 'cuda:0' )석류 모델은 이론적으로 다른 Pytorch 모듈과 동일한 혼합 또는 저 반영 체제에서 작동 할 수 있습니다. 그러나 석류는 대부분의 신경 네트워크보다 더 복잡한 작업을 사용하기 때문에 이러한 작업이 저 반영 체제에서 최적화되거나 구현되지 않았기 때문에 실제로 작동하지 않거나 실제로 도움이되지 않습니다. 따라서이 기능이 시간이 지남에 따라 더 유용 해지기를 바랍니다.
> >> X = torch . randn ( 100 , 4 )
> >> d = Normal ( covariance_type = 'diag' )
> >>
>> > with torch . autocast ( 'cuda' , dtype = torch . bfloat16 ):
> >> d . fit ( X ) 석류 분포는 모두 torch.nn.Module 의 인스턴스이므로 직렬화는 다른 Pytorch 모델과 동일합니다.
절약:
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()], verbose = True )
> >> model . cuda ()
> >> model . fit ( X )
> >> torch . save ( model , "test.torch" )로드 :
> >> model = torch . load ( "test.torch" )참고
torch.compile은 Pytorch 팀에 의해 활발한 개발 중이며 빠르게 향상 될 수 있습니다. 현재로서는 하나의 호환성 문제를 피하기 위해 모델을 초기화 할 때check_data=False를 전달해야 할 수도 있습니다.
Pytorch v2.0.0에서 torch.compile 작업을 함께 융합시키고 Cuda 그래프를 사용하며 일반적으로 GPU 실행에서 I/O 병목 현상을 제거하는 도구 주변의 유연한 래퍼로 소개되었습니다. 이러한 병목 현상은 많은 석류 크기의 데이터 설정에서 매우 중요 할 수 있기 때문에 많은 석류 사용자가 직면 한 torch.compile 은 매우 가치있는 것처럼 보입니다. 주로 forward 방법을 컴파일하는 전체 모델을 타겟팅하는 대신 개체에서 개별 메소드를 컴파일해야합니다.
# Create your object as normal
> >> mu = torch . exp ( torch . randn ( 100 ))
> >> d = Exponential ( mu ). cuda ()
# Create some data
> >> X = torch . exp ( torch . randn ( 1000 , 100 ))
> >> d . log_probability ( X )
# Compile the `log_probability` method!
> >> d . log_probability = torch . compile ( d . log_probability , mode = 'reduce-overhead' , fullgraph = True )
> >> d . log_probability ( X ) 불행히도, 나는 내부에서 각 배포의 log_probability 방법을 호출하는 혼합 모델의 predict 방법을 컴파일 할 때 메소드가 중첩 방식으로 호출 될 때 torch.compile 작동시키는 데 어려움이있었습니다. 이러한 오류 중 일부를 피하는 방식으로 코드를 구성하려고했지만 지금 오류 메시지가 불투명하기 때문에 약간 어려움을 겪었습니다.
석류는 torch.masked.MaskedTensor 객체를 통해 결 측값의 데이터 처리를 지원합니다. 간단히 말해서 누락 된 값에 마스크를 넣어야합니다.
> >> X = < your tensor with NaN for the missing values >
> >> mask = ~ torch . isnan ( X )
>> > X_masked = torch . masked . MaskedTensor ( X , mask = mask )
>> > d = Normal ( covariance_type = 'diag' ). fit ( X_masked )
>> > d . means
Parameter containing :
tensor ([ 0.2271 , 0.0290 , 0.0763 , 0.0135 ])모든 알고리즘은 현재 누락을 무시할 무언가로 취급합니다. 예를 들어, 값의 평균을 결 측값으로 계산할 때 평균은 단순히 현재 값의 평균값이됩니다. 부적절한 대치는 데이터를 편향시키고 분포를 왜곡하는 추정치를 생성하며 분산을 축소 할 수 없기 때문에 결 측값은 전치되지 않습니다.
모든 작업이 MaskedTensors에 아직 사용할 수있는 것은 아니기 때문에 다음 분포는 아직 결 측값에 대해 지원되지 않습니다. Bernoulli, 범주 형, 전체 공분산, 균일 한 정상
석류 v1.0.0의 새로운 기능은 혼합 모델, 베이 즈 분류기 및 숨겨진 Markov 모델에 대한 각 관찰에 대한 사전 확률로 전달할 수 있습니다. 이들은 우도를 평가하기 전에 모델의 구성 요소에 속하며 0과 1 사이의 범위가 있어야한다.이 값이 관찰을 위해 1.0을 포함 할 때, 그 관찰을 상태에 할당하는 측면에서는 더 이상 가능성이 없기 때문에이 값이 라벨로 취급되기 때문에 이전 확률이다. 따라서, 각 관측치가 일부 상태, 반 감독 된 학습에 대해 각 관측치가 1.0을 가질 때 (시퀀스가 숨겨진 Markov 모델에 대해서만 부분적으로 레이블을 지정할 때), 값이 0에서 1 사이 일 때 더 정교한 가중 형태의 가중치를 사용하는 경우 각각의 관측치가 1.0을 가질 때 이러한 이전 확률을 사용할 수 있습니다.