pomegranate
v1.1.0
Catatan Penting: Delima V1.0.0 adalah penulisan ulang delima menggunakan pytorch sebagai backend komputasi, bukan Cython. Meskipun fungsionalitas yang sama didukung, API sangat berbeda. Silakan lihat folder tutorial dan contoh untuk bantuan menulis ulang kode Anda.
Readthedocs | Tutorial | Contoh
Delima adalah perpustakaan untuk pemodelan probabilistik yang ditentukan oleh implementasi modular dan perawatan semua model sebagai distribusi probabilitas mereka. Implementasi modular memungkinkan seseorang untuk dengan mudah menjatuhkan distribusi normal ke dalam model campuran untuk membuat model campuran Gaussian semudah menjatuhkan gamma dan distribusi Poisson ke dalam model campuran untuk membuat campuran heterogen. Tapi bukan itu saja! Karena setiap model diperlakukan sebagai distribusi probabilitas, jaringan Bayesian dapat dijatuhkan ke dalam campuran semudah distribusi normal, dan model Markov tersembunyi dapat dijatuhkan ke pengklasifikasi Bayes untuk membuat classifier lebih dari sekuens. Bersama -sama, kedua pilihan desain ini memungkinkan fleksibilitas yang tidak terlihat dalam paket pemodelan probabilistik lainnya.
Baru -baru ini, delima (v1.0.0) ditulis ulang dari bawah ke atas menggunakan Pytorch untuk menggantikan backend Cython yang sudah ketinggalan zaman. Penulisan ulang ini memberi saya kesempatan untuk memperbaiki banyak pilihan desain buruk yang saya buat sebagai insinyur perangkat lunak BB. Sayangnya, banyak dari perubahan ini tidak kompatibel ke belakang dan akan mengganggu alur kerja. Di sisi lain, perubahan ini telah secara signifikan mempercepat sebagian besar metode, meningkatkan dan menyederhanakan kode, memperbaiki banyak masalah yang diangkat oleh masyarakat selama bertahun -tahun, dan membuatnya lebih mudah untuk berkontribusi. Saya telah menulis lebih banyak di bawah ini, tetapi Anda mungkin di sini sekarang karena kode Anda rusak dan ini adalah TL; DR.
Teriakan khusus untuk NumFocus untuk mendukung pekerjaan ini dengan hibah pengembangan khusus.
pip install pomegranate
Jika Anda memerlukan rilis Cython terakhir sebelum penulisan ulang, gunakan pip install pomegranate==0.14.8 . Anda mungkin perlu menginstal secara manual versi Cython sebelum v3.
Penulisan ulang ini dimotivasi oleh empat alasan utama:
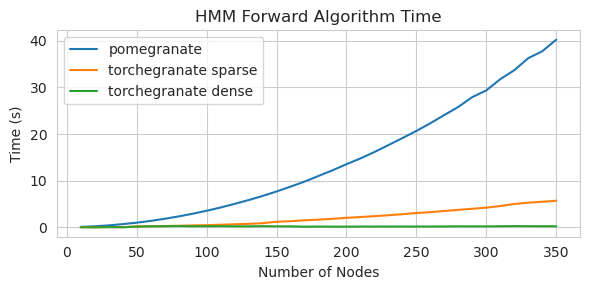
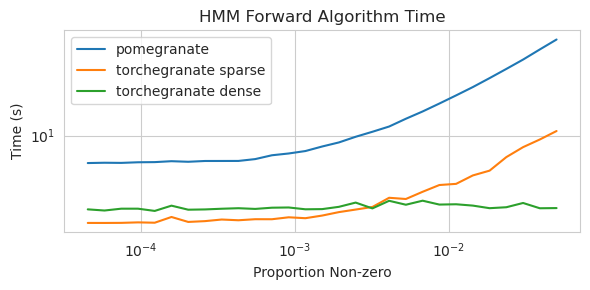
torch.nn.Moduletorch.masked.MaskedTensorNormalDistribution sekarang NormalFactorGraph sekarang didukung sebagai warga negara kelas satu, dengan semua metode prediksi dan pelatihanDenseHMM dan SparseHMM yang berbeda dalam bagaimana matriks transisi dikodekan, dengan objek DenseHMM secara signifikan lebih cepat pada grafik yang benar -benar padatNaiveBayes telah dihapus secara permanen karena redundan dengan BayesClassifierMarkovNetwork belum diterapkan Sebagian besar model dan metode dalam delima V1.0.0 lebih cepat daripada rekan -rekan mereka di versi sebelumnya. Ini umumnya skala berdasarkan kompleksitas, di mana orang hanya melihat speedup kecil untuk distribusi sederhana pada set data kecil tetapi speedup yang jauh lebih besar untuk model yang lebih kompleks pada set data besar, misalnya pelatihan model Markov tersembunyi atau inferensi jaringan Bayesian. Pengecualian penting untuk saat ini adalah bahwa pembelajaran struktur jaringan Bayesian, selain bangunan pohon chow-liu, masih belum lengkap dan tidak lebih cepat. Dalam contoh di bawah ini, torchegranate mengacu pada repositori sementara yang digunakan untuk mengembangkan delima V1.0.0 dan pomegranate mengacu pada delima v0.14.8.
Siapa yang tahu apa yang terjadi di sini? Liar.
Matriks transisi padat (CPU)
Matriks transisi jarang (CPU)
Melatih model 125 simpul dengan matriks transisi yang padat
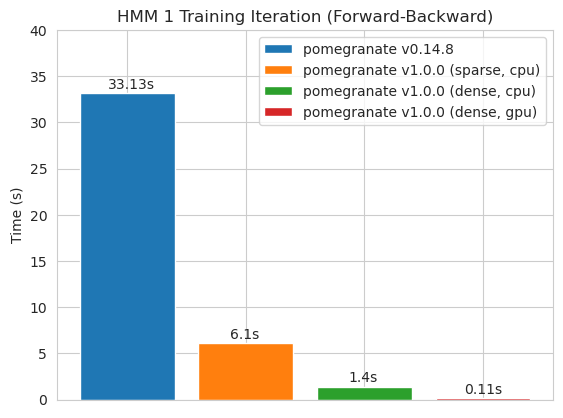
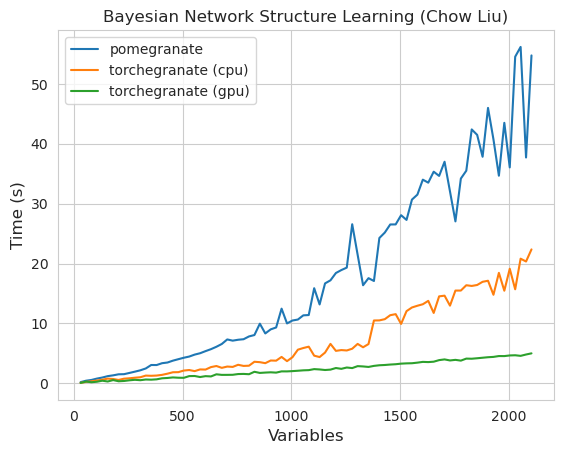
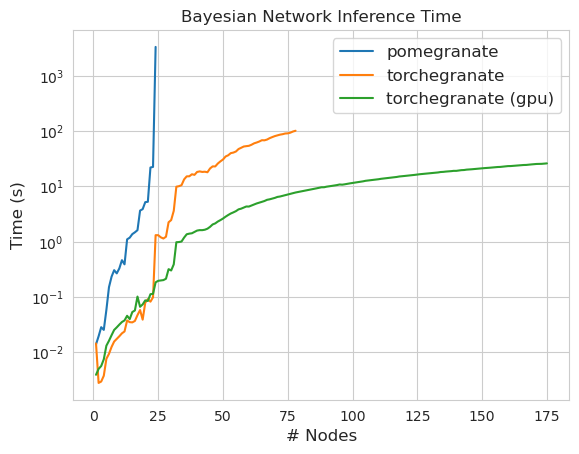
Catatan Silakan lihat folder tutorial untuk contoh kode.
Beralih dari backend Cython ke backend Pytorch telah memungkinkan atau memperluas sejumlah besar fitur. Karena penulisan ulang adalah pembungkus tipis di atas pytorch, karena fitur baru dirilis untuk pytorch mereka dapat diterapkan pada model delima tanpa perlu rilis baru dari saya.
Semua distribusi dan metode dalam delima sekarang memiliki dukungan GPU. Karena setiap distribusi adalah objek torch.nn.Module , penggunaannya identik dengan kode lain yang ditulis dalam Pytorch. Ini berarti bahwa baik model dan data harus dipindahkan ke GPU oleh pengguna. Misalnya:
> >> X = torch . exp ( torch . randn ( 50 , 4 ))
# Will execute on the CPU
> >> d = Exponential (). fit ( X )
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ])
# Will execute on a GPU
> >> d = Exponential (). cuda (). fit ( X . cuda ())
> >> d . scales
Parameter containing :
tensor ([ 1.8627 , 1.3132 , 1.7187 , 1.4957 ], device = 'cuda:0' )Demikian juga, semua model adalah distribusi, dan karenanya dapat digunakan pada GPU dengan cara yang sama. Ketika model dipindahkan ke GPU, semua model yang terkait dengannya (misalnya distribusi) dipindahkan ke GPU.
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()]). cuda ()
> >> model . fit ( X )
[ 1 ] Improvement : 1.26068115234375 , Time : 0.001134 s
[ 2 ] Improvement : 0.168121337890625 , Time : 0.001097 s
[ 3 ] Improvement : 0.037841796875 , Time : 0.001095 s
>> > model . distributions [ 0 ]. scales
Parameter containing :
>> > model . distributions [ 1 ]. scales
tensor ([ 0.9141 , 1.0835 , 2.7503 , 2.2475 ], device = 'cuda:0' )
Parameter containing :
tensor ([ 1.9902 , 2.3871 , 0.8984 , 1.2215 ], device = 'cuda:0' )Model delima dapat, secara teori, beroperasi dalam rezim campuran atau presisi rendah yang sama dengan modul Pytorch lainnya. Namun, karena delima menggunakan operasi yang lebih kompleks daripada kebanyakan jaringan saraf, ini kadang-kadang tidak berhasil atau membantu dalam praktik karena operasi ini belum dioptimalkan atau diimplementasikan dalam rezim presisi rendah. Jadi, semoga fitur ini akan menjadi lebih berguna dari waktu ke waktu.
> >> X = torch . randn ( 100 , 4 )
> >> d = Normal ( covariance_type = 'diag' )
> >>
>> > with torch . autocast ( 'cuda' , dtype = torch . bfloat16 ):
> >> d . fit ( X ) Distribusi delima adalah semua contoh torch.nn.Module dan karenanya serialisasi sama dengan model Pytorch lainnya.
Penghematan:
> >> X = torch . exp ( torch . randn ( 50 , 4 )). cuda ()
> >> model = GeneralMixtureModel ([ Exponential (), Exponential ()], verbose = True )
> >> model . cuda ()
> >> model . fit ( X )
> >> torch . save ( model , "test.torch" )Memuat:
> >> model = torch . load ( "test.torch" )Catatan
torch.compilesedang dalam pengembangan aktif oleh tim Pytorch dan dapat meningkat dengan cepat. Untuk saat ini, Anda mungkin perlu lulus dicheck_data=Falsesaat menginisialisasi model untuk menghindari satu masalah kompatibilitas.
Di Pytorch v2.0.0, torch.compile . Karena kemacetan ini bisa sangat signifikan dalam pengaturan data berukuran kecil hingga menengah yang dihadapi oleh banyak pengguna delima, torch.compile . Tampaknya itu akan sangat berharga. Daripada menargetkan seluruh model, yang sebagian besar hanya menyusun metode forward , Anda harus menyusun metode individu dari objek Anda.
# Create your object as normal
> >> mu = torch . exp ( torch . randn ( 100 ))
> >> d = Exponential ( mu ). cuda ()
# Create some data
> >> X = torch . exp ( torch . randn ( 1000 , 100 ))
> >> d . log_probability ( X )
# Compile the `log_probability` method!
> >> d . log_probability = torch . compile ( d . log_probability , mode = 'reduce-overhead' , fullgraph = True )
> >> d . log_probability ( X ) Sayangnya log_probability saya mengalami kesulitan membuat torch.compile predict Saya telah mencoba mengatur kode dengan cara yang menghindari beberapa kesalahan ini, tetapi karena pesan kesalahan saat ini buram, saya mengalami kesulitan.
Delima mendukung penanganan data dengan nilai -nilai yang hilang melalui objek torch.masked.MaskedTensor . Sederhananya, seseorang hanya perlu menaruh topeng di atas nilai -nilai yang hilang.
> >> X = < your tensor with NaN for the missing values >
> >> mask = ~ torch . isnan ( X )
>> > X_masked = torch . masked . MaskedTensor ( X , mask = mask )
>> > d = Normal ( covariance_type = 'diag' ). fit ( X_masked )
>> > d . means
Parameter containing :
tensor ([ 0.2271 , 0.0290 , 0.0763 , 0.0135 ])Semua algoritma saat ini memperlakukan ketidaksopanan sebagai sesuatu untuk diabaikan. Sebagai contoh, ketika menghitung rata -rata kolom dengan nilai yang hilang, rata -rata hanya akan menjadi nilai rata -rata dari nilai saat ini. Nilai -nilai yang hilang tidak diperhitungkan karena imputasi yang tidak tepat dapat bias data Anda, menghasilkan perkiraan yang tidak mungkin yang mendistorsi distribusi, dan juga mengecilkan varian.
Karena belum semua operasi belum tersedia untuk maskedtensor, distribusi berikut belum didukung untuk nilai yang hilang: Bernoulli, kategorikal, normal dengan kovarians penuh, seragam
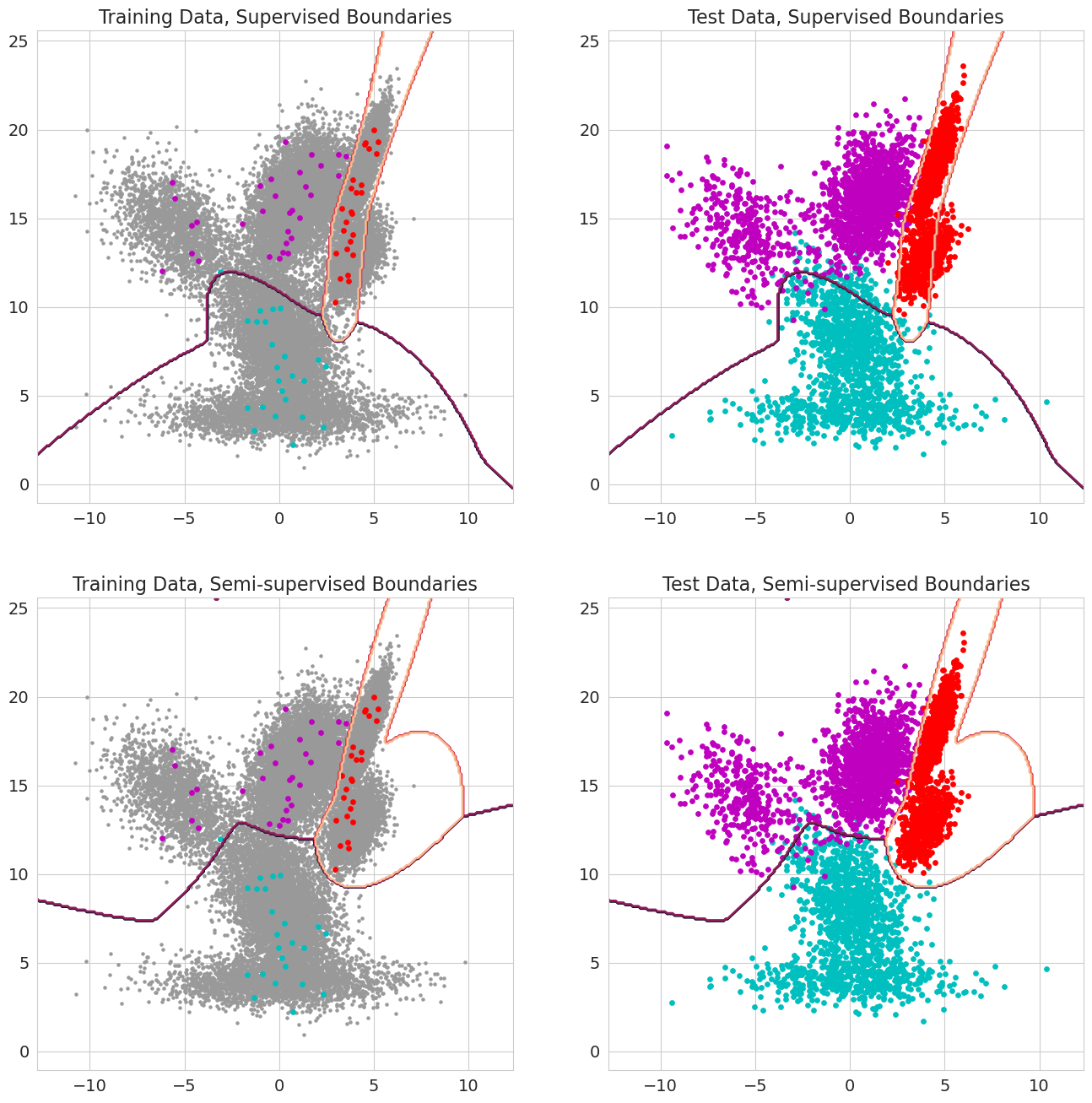
Fitur baru dalam delima V1.0.0 adalah mampu meneruskan probabilitas sebelumnya untuk setiap pengamatan untuk model campuran, pengklasifikasi Bayes, dan model Markov tersembunyi. Ini adalah probabilitas sebelumnya bahwa pengamatan milik komponen model sebelum mengevaluasi kemungkinan dan harus berkisar antara 0 dan 1. Ketika nilai -nilai ini termasuk 1.0 untuk pengamatan, itu diperlakukan sebagai label, karena kemungkinan tidak lagi penting dalam hal menetapkan pengamatan tersebut ke suatu negara. Oleh karena itu, seseorang dapat menggunakan probabilitas sebelumnya ini untuk melakukan pelatihan berlabel ketika setiap pengamatan memiliki 1.0 untuk beberapa negara bagian, pembelajaran semi-diawasi ketika subset pengamatan (termasuk ketika sekuens hanya diberi label sebagian untuk model Markov tersembunyi), atau bentuk bobot yang lebih canggih ketika nilai-nilai antara 0 dan 1.