ChineseNER
1.0.0
本項目使用
對命名實體識別不了解的可以先看一下這篇文章。順便求star~
這是最簡單的一個命名實體識別BiLSTM+CRF模型。
data文件夾中有三個開源數據集可供使用,玻森數據(https://bosonnlp.com) 、1998年人民日報標註數據、MSRA微軟亞洲研究院開源數據。其中boson數據集有6種實體類型,人民日報語料和MSRA一般只提取人名、地名、組織名三種實體類型。
先運行數據中的python文件處理數據,供模型使用。
使用python train.py開始訓練,訓練的模型會存到model文件夾中。
使用python train.py pretrained會使用預訓練的詞向量開始訓練,vec.txt是在網上找的一個比較小的預訓練詞向量,可以參照我的代碼修改使用其他更好的預訓練詞向量。
使用python train.py test進行測試,會自動讀取model文件夾中最新的模型,輸入中文測試即可,測試結果好壞根據模型的準確度而定。
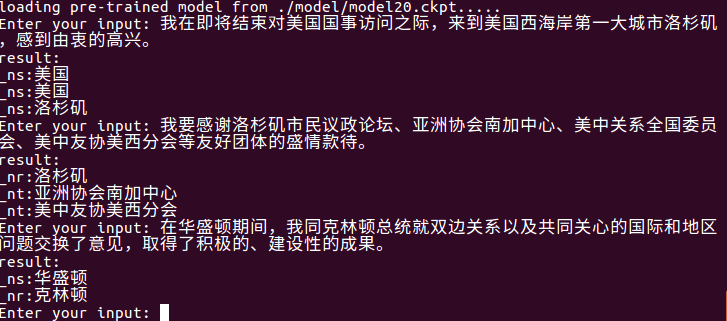
使用python train.py input_file output_file進行文件級實體抽取。
可以自動讀取model文件夾中最新的模型,將input_file中的實體抽取出來寫入output_file中。先是原句,然後是實體類型及實體(可按照需要修改)。
如python train.py test1.txt res.txt , res.txt內容如下:
不定期增加其他修改。 。
直接用的pytorch tutorial裡的Bilstm+crf模型.
運行train.py訓練即可。由於使用的是cpu,而且也沒有使用batch,所以訓練速度超級慢。想簡單跑一下代碼的話,建議只使用部分數據跑一下。 pytorch暫時不再更新。
參數並沒有調的太仔細,boson數據集的f值在70%~75%左右,人民日報和MSRA數據集的f值在85%~90%左右。 (畢竟boson有6種實體類型,另外兩個只有3種)
2018-9-15 增加tensorflow版本。
2018-9-17 增加1998年人民日報數據集和MSRA微軟亞洲研究院數據集。
2018-9-19 簡單修改了代碼風格,將model提取出來,方便以後拓展。
2018-9-22 增加python train.py test功能。
2018-10-6 增加使用參數確定是否使用預訓練詞向量進行訓練。
2018-10-11 增加功能:可以抽取一個文本文件中的實體,寫入另一個文件中。



