ChineseNER
1.0.0
Dieses Projekt verwendet
Wenn Sie die genannte Entitätserkennung nicht verstehen, können Sie diesen Artikel zuerst lesen. Übrigens, bitte Star ~
Dies ist der einfachste Weg, um ein BILSTM+CRF -Modell für eine benannte Entität zu identifizieren.
Im Datenordner sind drei Open -Source -Datensätze verfügbar, Boson -Daten (https://bosonnlp.com), die täglichen Daten von 1998 und die Open -Source -Daten von MSRA Microsoft Asia Research Institute. Unter ihnen gibt es im Boson -Datensatz 6 Entitätstypen. Das tägliche Corpus und die MSRA der Menschen extrahieren im Allgemeinen nur drei Entitätstypen: Personenname, Ortsname und Organisationsname.
Führen Sie zuerst die Python -Datei in den Daten aus, um die Daten für das zu verwendende Modell zu verarbeiten.
Beginnen Sie mit dem Training mit python train.py , und das ausgebildete Modell wird im Modellordner gespeichert.
Die Verwendung von python train.py pretrained dem Training mit vorbereiteten Wortvektoren mit dem Training beginnen. Vec.txt ist ein kleinerer vorbereiteter Wortvektor, der online gefunden wurde. Sie können auf meinen Code verweisen, um ihn so zu ändern, dass andere bessere vorbereitete Wortvektoren verwendet werden.
Verwenden Sie python train.py test zum Testen, und das neueste Modell im Modellordner wird automatisch gelesen und Chinesisch zum Testen eingeben. Die Qualität der Testergebnisse hängt von der Genauigkeit des Modells ab.
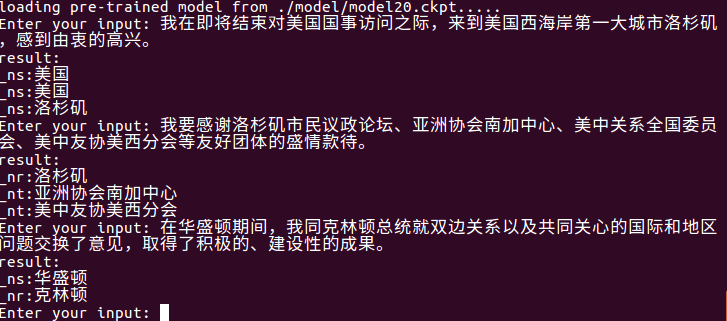
Verwenden Sie python train.py input_file output_file für die Entitätsförderung auf Dateiebene.
Es kann das neueste Modell automatisch im Modellordner lesen, die Entitäten in input_file extrahieren und in output_file schreiben. Zuerst gibt es den ursprünglichen Satz, dann der Entitätstyp und die Entität (können nach Bedarf geändert werden).
Beispielsweise ist python train.py test1.txt res.txt , Res.txt -Inhalt lautet wie folgt:
Zusätzliche Änderungen werden von Zeit zu Zeit hinzugefügt. .
Verwenden Sie das BILSTM+CRF -Modell im Pytorch -Tutorial direkt.
Führen Sie einfach Train. Py Training. Da wir CPU verwenden und keine Stapel verwenden, ist die Trainingsgeschwindigkeit super langsam. Wenn Sie einfach den Code ausführen möchten, wird empfohlen, nur einige Daten zum Ausführen zu verwenden. Pytorch wird vorerst nicht aktualisiert.
Die Parameter wurden nicht zu sorgfältig eingestellt. Der F -Wert des Boson -Datensatzes betrug rund 70%~ 75%, und der Wert der täglichen und MSRA -Datensätze betrug rund 85%~ 90%. (Immerhin hat Boson 6 Entitätstypen und die anderen beiden haben nur 3 Typen)
2018-9-15 TensorFlow-Version hinzugefügt.
2018-9-17 fügte den täglichen Datensatz der People 1998 und den Datensatz des MSRA Microsoft Asia Research Institute hinzu.
2018-9-19 Der Codestil wurde einfach geändert und das Modell wurde für die zukünftige Expansion extrahiert.
2018-9-22 python train.py test Testfunktion hinzugefügt.
2018-10-6 Fügen Sie die Verwendungsparameter hinzu, um festzustellen, ob vorgebaute Word-Vektoren für das Training verwendet werden sollen.
2018-10-11 Hinzugefügter Funktion: Es kann Entitäten aus einer Textdatei extrahieren und in eine andere Datei schreiben.



