ChineseNER
1.0.0
このプロジェクトは使用します
名前付きのエンティティ認識がわからない場合は、最初にこの記事を読むことができます。ちなみに、主演してください〜
これは、指定されたエンティティのBILSTM+CRFモデルを識別する最も簡単な方法です。
データフォルダーには、ボーソンデータ(https://bosonnlp.com)、1998年の毎日のラベル付きデータ、およびMSRA Microsoft Asia Research Instituteオープンソースデータ、3つのオープンソースデータセットがあります。その中には、Bosonデータセットには6つのエンティティタイプがあります。人々の毎日のコーパスとMSRAは、一般に、個人名、地名、組織名の3つのエンティティタイプのみを抽出します。
最初にデータ内のPythonファイルを実行して、使用するモデルのデータを処理します。
python train.pyでトレーニングを開始すると、訓練されたモデルがモデルフォルダーに保存されます。
python train.py pretrainedの使用は、前処理された単語ベクトルを使用してトレーニングを開始します。 vec.txtは、オンラインで見つかったより小さな前提条件のベクトルです。私のコードを参照して、それを変更して、他のより優先されるワードベクトルを使用することができます。
python train.py testにテストに使用すると、モデルフォルダーの最新モデルが自動的に読み取られ、テストするために中国語を入力します。テスト結果の品質は、モデルの精度に依存します。
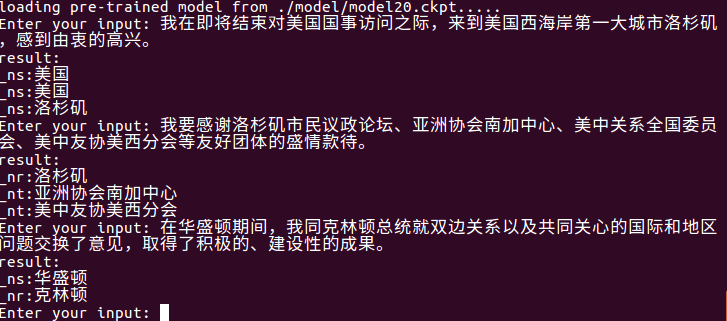
ファイルレベルのエンティティ抽出には、 python train.py input_file output_file使用します。
モデルフォルダーの最新モデルを自動的に読み取り、 input_fileでエンティティを抽出し、 output_fileに書き込むことができます。最初に元の文があり、次にエンティティタイプとエンティティ(必要に応じて変更できます)。
たとえば、 python train.py test1.txt res.txt 、res.txtコンテンツは次のとおりです。
追加の変更が随時追加されます。 。
Pytorchチュートリアルで直接bilstm+CRFモデルを使用します。
Train.pyトレーニングを実行するだけです。 CPUを使用してバッチを使用しないため、トレーニング速度は非常に遅いです。単に実行するだけの場合は、コードを実行するために一部のデータのみを使用することをお勧めします。 Pytorchは当面は更新されません。
パラメーターは慎重に調整されていませんでした。 BosonデータセットのF値は約70%〜75%であり、人々の日常およびMSRAデータセットのF値は約85%〜90%でした。 (結局のところ、Bosonには6つのエンティティタイプがあり、他の2つには3つのタイプしかありません)
2018-9-15 TensorFlowバージョンを追加しました。
2018-9-17は、1998年に人民の毎日のデータセットとMSRA Microsoft Asia Research Instituteのデータセットを追加しました。
2018-9-19コードスタイルは単純に変更され、将来の拡張のためにモデルが抽出されました。
2018-9-22 python train.py test機能を追加しました。
2018-10-6使用パラメーターを追加して、トレーニングに事前に訓練された単語ベクトルを使用するかどうかを判断します。
2018-10-11追加機能:テキストファイルからエンティティを抽出し、別のファイルに書き込むことができます。



