ChineseNER
1.0.0
Этот проект использует
Если вы не понимаете признание именного признания, вы можете сначала прочитать эту статью. Кстати, пожалуйста, звезда ~
Это самый простой способ идентифицировать модель Bilstm+CRF для названной сущности.
В папке данных доступно три набора данных с открытым исходным кодом: Data Data Boson (https://bosonnlp.com), ежедневные данные о людях с маркировкой людей и MSRA Microsoft Asia Research Institute Institute с открытым исходным кодом. Среди них есть 6 типов объектов в наборе данных бозон. Daily's Daily Corpus и MSRA, как правило, извлекают только три типа организации: название человека, название места и название организации.
Сначала запустите файл Python в данных, чтобы обработать данные для использования модели.
Начните обучение с python train.py , и обученная модель будет сохранена в папке модели.
Использование python train.py pretrained начнет подготовку с помощью предварительных векторов слов. VEC.TXT - это меньший предварительный вектор слов, найденный в Интернете. Вы можете обратиться к моему коду, чтобы изменить его на использование других лучших предварительно предварительно проведенных векторов Word.
Используйте python train.py test для тестирования, и последняя модель в папке модели будет автоматически прочитать и введите китайский язык для тестирования. Качество результатов теста зависит от точности модели.
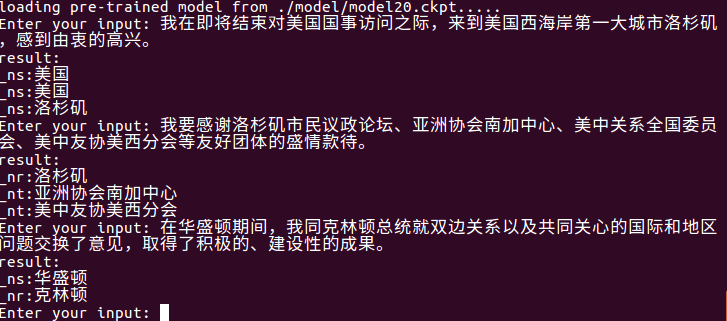
Используйте python train.py input_file output_file для извлечения объекта на уровне файлов.
Он может автоматически читать последнюю модель в папке модели, извлечь объекты в input_file и записать их в output_file . Сначала существует первоначальное предложение, затем тип объекта и сущность (может быть изменен по мере необходимости).
Например, python train.py test1.txt res.txt , res.txt Content выглядит следующим образом:
Время от времени добавляются дополнительные модификации. Полем
Используйте модель Bilstm+CRF в уроке Pytorch напрямую.
Просто запустите Train.py Training. Поскольку мы используем процессор и не используем партию, скорость тренировок очень медленная. Если вы хотите просто запустить код, рекомендуется использовать только некоторые данные для его запуска. Pytorch не будет обновляться на данный момент.
Параметры не были скорректированы слишком тщательно. Значение F набора данных бозона составляло около 70%~ 75%, а значение F наборов данных на людей и MSRA составляло около 85%~ 90%. (В конце концов, бозон имеет 6 типов объектов, а два других имеют только 3 типа)
2018-9-15 добавлена версия TensorFlow.
2018-9-17 добавил набор данных на людей в 1998 году и набор данных MSRA Microsoft Asia Institute.
2018-9-19 Стиль кода был просто изменен, и модель была извлечена для будущего расширения.
2018-9-22 Добавлена функция python train.py test .
2018-10-6 Добавьте параметры использования, чтобы определить, использовать ли предварительно обученные векторы Word для обучения.
2018-10-11 Добавленная функция: она может извлечь объекты из текстового файла и записывать их в другой файл.



