ChineseNER
1.0.0
Este proyecto usa
Si no comprende el reconocimiento de entidad nombrado, primero puede leer este artículo. Por cierto, por favor estelar ~
Esta es la forma más fácil de identificar un modelo BILSTM+CRF para una entidad nombrada.
Hay tres conjuntos de datos de código abierto disponibles en la carpeta de datos, datos de bosones (https://bosonnlp.com), datos etiquetados diarios de la gente de 1998 y datos de código abierto del Instituto de Investigación de Asia MSRA Microsoft Asia. Entre ellos, hay 6 tipos de entidades en el conjunto de datos del bosón. People's Daily Corpus y MSRA generalmente solo extraen tres tipos de entidad: nombre de la persona, nombre del lugar y nombre de la organización.
Primero ejecute el archivo Python en los datos para procesar los datos para que el modelo use.
Comience a entrenar con python train.py , y el modelo entrenado se guardará en la carpeta del modelo.
El uso de python train.py pretrained comenzará a entrenar utilizando vectores de palabras previos a la aparición. vec.txt es un vector de palabras previamente previo al estado de petróleo que se encuentra en línea. Puede consultar mi código para modificarlo para usar otros vectores de palabras mejores previos a la pretrada.
Use python train.py test para pruebas, y el último modelo en la carpeta del modelo se leerá e ingresará automáticamente el chino para probar. La calidad de los resultados de la prueba depende de la precisión del modelo.
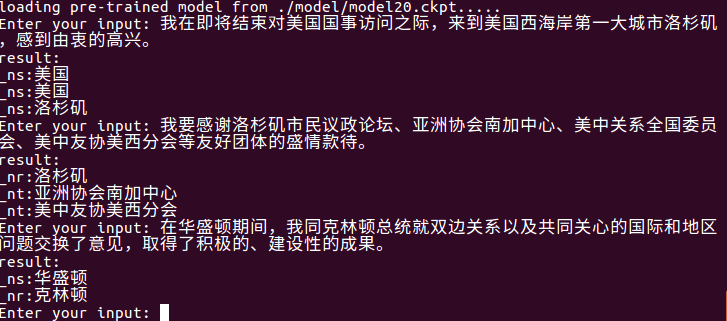
Use python train.py input_file output_file para la extracción de entidad a nivel de archivo.
Puede leer automáticamente el último modelo en la carpeta del modelo, extraer las entidades en input_file y escribirlas en output_file . Primero está la oración original, luego el tipo de entidad y la entidad (se pueden modificar según sea necesario).
Por ejemplo, python train.py test1.txt res.txt , res.txt El contenido es el siguiente:
Se agregan modificaciones adicionales de vez en cuando. .
Use el modelo BILSTM+CRF en el tutorial Pytorch directamente.
Simplemente ejecute el entrenamiento de Train.py. Como usamos CPU y no usamos lotes, la velocidad de entrenamiento es súper lenta. Si simplemente desea ejecutar el código, se recomienda usar solo algunos datos para ejecutarlo. Pytorch no se actualizará por el momento.
Los parámetros no se ajustaron con demasiada cuidado. El valor F del conjunto de datos del bosón fue de alrededor del 70%~ 75%, y el valor F de los conjuntos de datos diarios de las personas y MSRA fue de alrededor del 85%~ 90%. (Después de todo, Boson tiene 6 tipos de entidad, y los otros dos solo tienen 3 tipos)
2018-9-15 Se agregó la versión TensorFlow.
2018-9-17 agregó el conjunto de datos diarios de las personas en 1998 y el conjunto de datos del Instituto de Investigación de Asia MSRA Microsoft.
2018-9-19 El estilo del código se modificó simplemente y el modelo se extrajo para una futura expansión.
2018-9-22 agregó la función python train.py test .
2018-10-6 Agregue los parámetros de uso para determinar si se debe usar vectores de palabras previamente capacitados para el entrenamiento.
2018-10-11 Función agregada: puede extraer entidades de un archivo de texto y escribirlas en otro archivo.



